Ada dua kubu pengertian AI yang terkenal yakni Russel [link] dan Elaine Rich [link]. Russel mendefinisikan 4 kuadran AI yakni think rationally, act rationally, think humanly, dan act humanly. Sementara Elaine Rich bersikukuh bahwa AI adalah bagaimana membuat komputer cerdas tetapi saat ini masih kecerdasannya di bawah manusia. Maksudnya adalah ada batas dimana ketika manusia sudah dikalahkan maka sudah tidak disebut AI lagi. Misalnya catur, ketika Kasparov di tahun 94 dikalahkan oleh Deep Blue buatan IBM, maka catur menurutnya sudah bukan AI lagi. Sama dengan permainan GO yg manusia sudah tidak bisa menang lagi melawan komputer. Silahkan percaya yang mana, tetapi yang kedua sepertinya sudah mulai terasa saat ini, yakni kekhawatiran AI mengalahkan manusia. Untuk think dan act rationally, okelah, tetapi jika think dan act humanly sudah dikalahkan AI, wah bisa repot. Saat ini penolakan mulai menghantui aplikasi AI, misalnya ChatGPT [link]. PBB pun sudah mewanti-wanti [link].
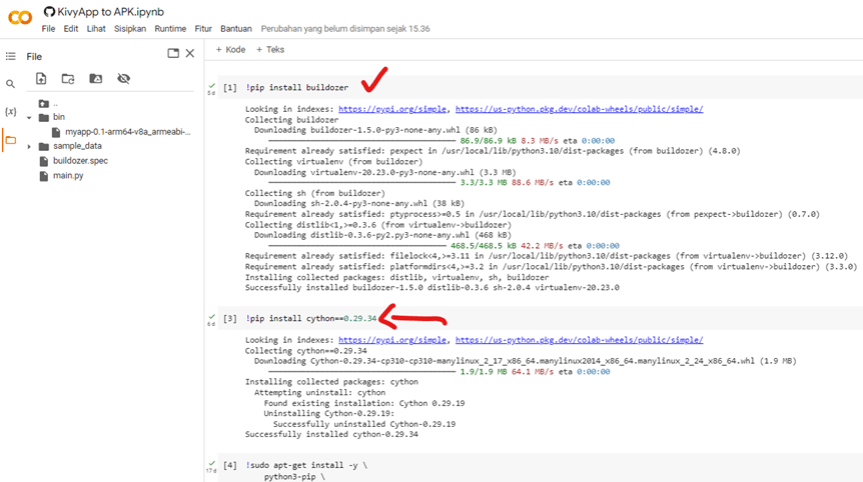
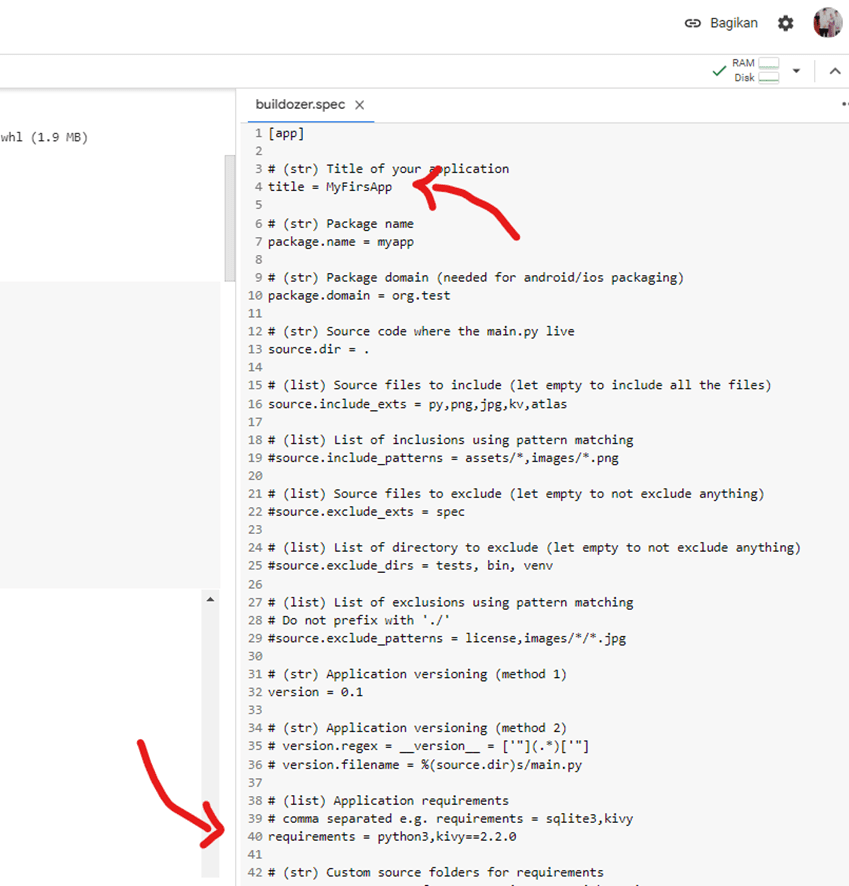
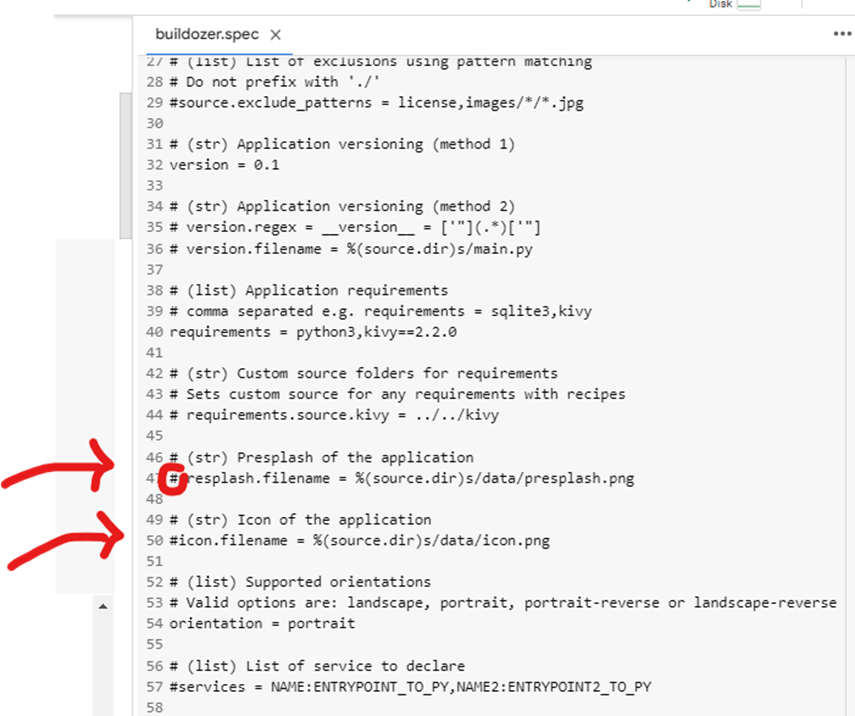
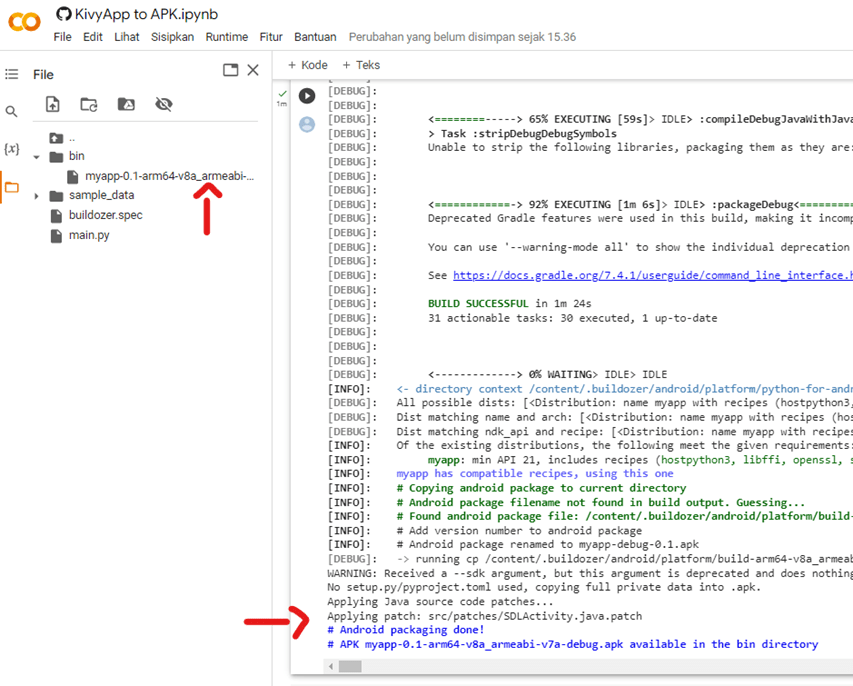
Tentu saja ibarat pisau yang bisa dipakai untuk kejahatan maupun kebaikan, ada baiknya bijak menggunakan AI. Misalnya memanfaatkan AI untuk belajar AI, salah satunya adalah ChatGPT. Aplikasi ini sangat praktis dalam belajar memrogram AI, atau setidaknya tidak hanya teori melainkan mempraktikannya secara langsung. Kita bisa belajar bagaimana AI diterapkan pada aplikasi Web yang saat ini ada, misalnya menambah ChatBot, similarity check, sistem rekomendasi, dan lain-lain. Tentu saja kemampuan menyisipkan AI di server web, misalnya PHP, DotNet dan sejenisnya. Selain pada Web, aplikasi desktop dan mobile sangat perlu juga diketahui bagi yang ingin belajar AI dasar, langsung praktik dan tidak hanya teori saja. Lintas platform pun dengan mudah dapat dilihat dengan hasil yang dapat dilihat langsung.
Dengan kecepatan membuat AI saat ini, kita hanya fokus ke bagian utama dari disain AI yaitu value. Beberapa hal yang ‘menjengkelkan’, ‘membosankan’, dan membuat ‘gundah’ masyarakat merupakan salah satu sasaran dari dibuatkannya AI. Hal-hal tersebut dapat dicapai dengan efisiensi, efektivitas, kecepatan, akurasi, dan kemudahan-kemudahan lainnya. Analisis dan diagnosis kesehatan bisa cepat dan murah, manajemen jadi tepat, dan lain-lain.
Masalahnya adalah standard untuk AI, seperti ISO, dan sejenisnya saat ini masih dalam tahap istilah, terminologi, dan lain-lain. PBB pun masih hanya masih berupa pertemuan untuk inisiatif-inisitaif seperti “The United Nations AI for Good Global Summit.”. Untungnya tiap domain implementasi, seperti pada kedokteran, transportasi, edukasi, dan lain-lain sudah punya standar yang dapat dipakai untuk membatasi penggunaan AI yang berlebihan.
Sebelum adanya kesepakatan, ada baiknya kita tetap memanfaatkan AI untuk hal-hal baik, salah satunya untuk belajar AI denga bantuan AI. Sekian semoga bermanfaat.