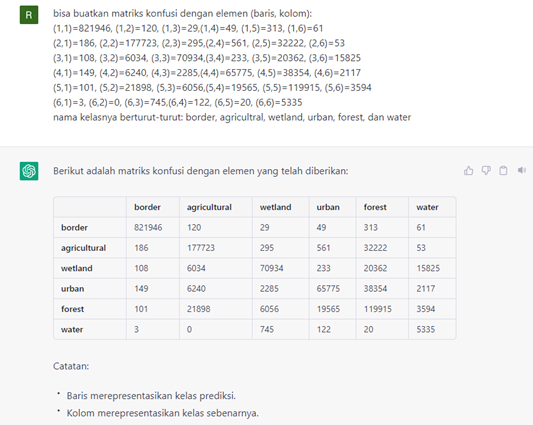
Dalam machine learning dikenal beberapa jenis data antara lain: data training dan data testing. Terkadang data training dipisah menjadi data training dan target. Dalam prakteknya, data training menggunakan sebagaian prosentase dengan sisanya dijadikan data tasting untuk pengujian model.
Excel dapat digunakan untuk mempersiapkan data training walaupun memiliki beberapa keterbatasan dalam mengelola “big data”. Untuk data yang tidak terlalu besar, aplikasi bawaan ms office ini cukup dapat diandalkan.
Walaupun cross validation banyak diterapkan saat ini, tetapi dengan 80% data training dan sisanya untuk testing (20%) sudah cukup untuk mengukur akurasi model yang dirancang. Sebagai contoh data training berikut dapat digunakan, dengan data latihnya. Berikut langkah proses mempersiapkan data training dan data testing.
1. ANFIS
Untuk ANFIS data training dan target digabung menjadi satu. Formatnya karena sudah sesuai dengan format pentabelan di Excel maka cukup menyiapkan data training saja. Gunakan dua kode ini untuk mengimport data dengan Matlab.
-
load(‘data.dat’);
-
load(‘testing.dat’);
Untuk ANFIS, fungsi “anfisedit” disediakan Matlab untuk melatih ANFIS lewat data yang ada. Karena isian sudah dalam bentuk DAT maka sebenarnya dua kode di atas hanya digunakan nanti untuk testing dan training lewat model lainnya seperti JST, SVM, dll.
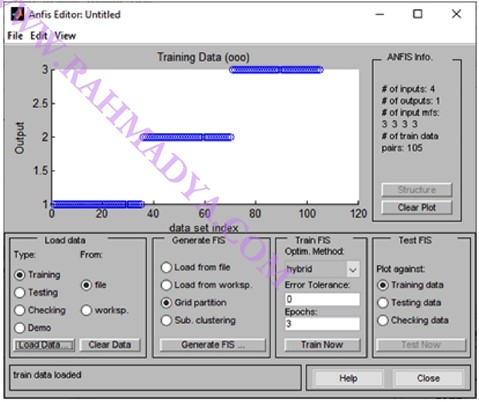
Pastikan training data muncul dengan tiga kelas sesuai dengan data (kelas 1, 2 dan 3). Berikutnya “Generate FIS” diklik untuk meramu FIS yang masih kosong.

Angka 3 di atas berarti ada 3 komponen MF di tiap input. Jumlah angka yang muncul menandakan jumlah masukan, di sini ada empat input yang merupakan variabel penentu output. Tipe MF ada banyak, di sini akan digunakan “trimf” yang paling sederhana (linear). Gunakan saja defaultnya (3 komponen di tiap inputan), yang merepresentasikan kondisi “low”, “medium”, dan “high”. Output gunakan saja konstan. ANFIS hanya tersedia di jenis fuzzy “Sugeno”. Tekan “Struktur” di sisi kanan untuk melihat sekilas Network yang siap dilatih.
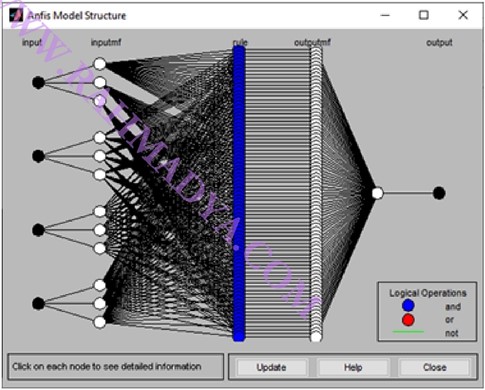
Berikutnya masuk ke panel “Train FIS” untuk melatih Network. Ada dua pilihan pembelajaran: hybrid dan backpropagation. Gunakan saja “hybrid”. Berikut merupakan hasil training dengan 3 epoch (mirip iterasi).

Error tampak di layar utama (sekitar 0.1445). Simpan hasil pelatihan lewat “File” – “Export” – Pilih file.

Setelah nama fuzzy diisi (berekstensi *.fis) maka model siap diuji dengan data testing yang sudah ada. Misalnya diberi nama “anfisiris.fis”. Untuk testing gunakan kode berikut ini:
-
anfisiris=readfis(‘anfisiris.fis’);
-
prediksi=evalfis(testing(:,1:4);
-
tes=testing(:,1:4)
-
hasil=evalfis(tes,anfisiris)
Terakhir adalah menghitung akurasi dengan cara prosentase MAPE (Mean Average Percentage Error)-nya:
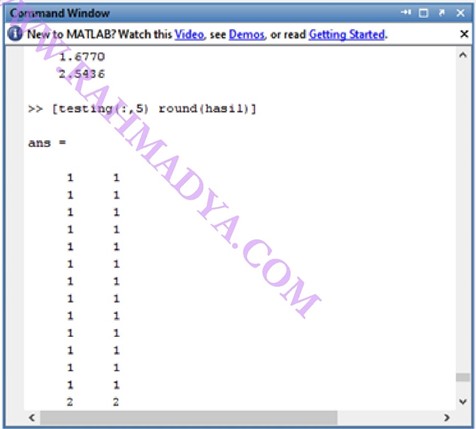
Jika dibandingkan maka akan tampak beberapa yang error, misalnya di sini ada satu yang error, jadi nilai MAPE-nya= 1/39 *100 = 2,56 %. Atau akurasinya = 100-2,56 = 97,44%. Sedangkan jika ingin mengetahui prediksi mana saja yang tidak akurat dapat menggunakan matriks confusion.
-
target=testing(:,5);
-
target=transpose(target);
-
prediksi=transpose(round(hasil));
-
c=confusionmat(target,prediksi)
-
c =
-
13 0 0
-
0 13 0
-
0 1 12
Cara membaca matriks confusion adalah sebagai berikut. Kolom merupakan prediksi sementara baris adalah aktualnya (dalam hal ini sama dengan target (testing di kolom kelima). Fungsi “round” ditambahkan pada hasil untuk mencari kelas prediksi terdekat, misalnya 2.7 dikategorikan kelas “3”. Diagonal pada matriks confusion menyatakan akurasi. Perhatikan di baris kedua kolom ketiga, di sini harusnya 13 tetapi berisi 12 karena ada satu prediksi 3 (baris ketiga) tetapi kenyataannya 2 (kolom kedua).
2. Neural Networks (Jaringan Syaraf Tiruan)
JST perlu memisahkan data training dengan target (labelnya). Selain itu, formatnya juga berbeda dengan data pada ANFIS, dimana variabel berdasarkan baris. Untuk itu perlu modifikasi data yang ada berdasarkan “data.dat” dan “testing.dat”. Berikut ini kode untuk data training dan targetnya.
Coba cek dengan fungsi “size”, pastikan jumlah baris merepresentasikan jumlah variabel, sementara jumlah kolom merepresentasikan jumlah data. Berikutnya buat JST kosong dan latih.
-
network=newff(datalatih,target,[81 81]);
-
network=train(network,datalatih,target);
Perlu disiapkan data untuk testing.
Selanjutnya menggunakan fungsi “sim” untuk memprediksi.
-
hasil=sim(network,tesdata);
-
aktual=targettes;
-
prediksi=round(hasil);
-
c=confusionmat(aktual,prediksi);
-
c =
-
13 0 0 0
-
0 11 2 0
-
0 4 6 3
-
0 0 0 0
Dari matriks confusion di atas dapat diketahui precision-nya (atau dikenal juga dengan nama MAPE). Caranya adalah membandingkan total yang benar (angka di sisi diagonal) dengan total data testing.
-
13+11+6
-
ans =
-
30
-
ans/39
-
ans =
-
0.7692
Akurasi yang dihasilkan (MAPE) adalah 76.92%.
3. Support Vector Machine (SVM)
SVM hanya memisahkan dua kelas yang berbeda. Jika ada lebih dari dua kelas, maka perlu modifikasi dengan menggunakan lebih dari satu garis pemisah. Salah satu tekniknya adalah membuat pohon keputusan. Misalnya ada tiga kelas (kelas 1, kelas 2 dan kelas 3) maka perlu dibuat tiga garis pemisah, misalnya kita beri nama svm1, svm2 dan svm3.
-
svm1, pemisah antara kelas 1 dan kelas 2
-
svm 2, pemisah antara kelas 1 dan kelas 3, dan
-
svm 3, pemisah antara kelas 2 dan kelas 3

(source: link)
Selanjutnya, dibuat logika if-else untuk mengarahkan garis pemisah yang sesuai (atau dengan teknik lain yang sesuai). Berikut ini salah satu contohnya:
-
test1=svmclassify(svm1,datatesting)
-
if test1==1
-
test2=svmclassify(svm2,datatesting)
-
if test2==1
-
class=’1′
-
else
-
class=’3′
-
end
-
else
-
test3=svmclassify(svm3,datatesting)
-
if test3==2
-
class=’2′
-
else
-
class=’3′
-
end
-
end
Untuk membuat garis pemisah, Matlab menyediakan fungsi “svmtrain”. Jika ingin membuat garis pemisah antara kelas 1 dan kelas 2 (svm1) diperlukan data latih yang memiliki kelas 1 dan kelas 2 (tanpa menyertakan kelas 3) disertai dengan group-nya (dalam JST dikenal dengan istilah target).
Di sini “train” merupakan data gabungan kelas 1 dan kelas 2, begitu pula “group” merupakan kelas yang sesuai dengan “train”. Gunakan excel untuk memilah-milah antara kelas 1 dengan kelas lainnya untuk membuat svm2, dan svm3.