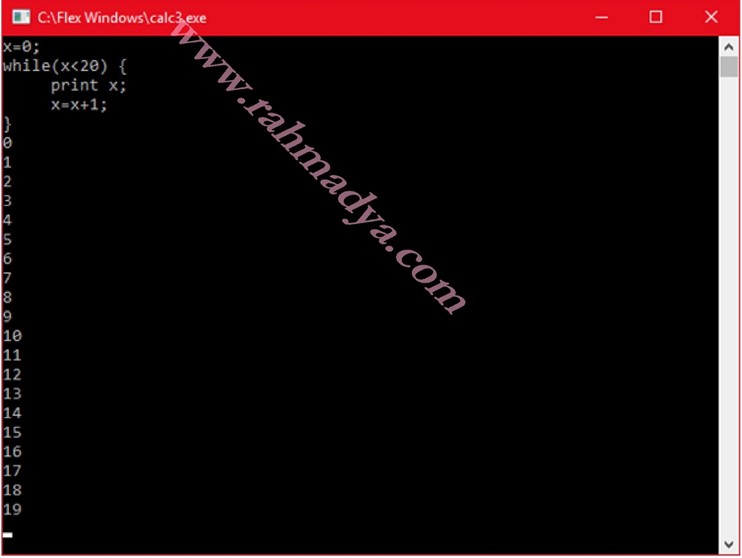
Mahasiswa jaman dulu sudah mengenal kompilasi program menjadi file executable. File jenis ini tidak bisa langsung dilihat kode programnya, sehingga lebih aman dari ‘penggunaan kembali’ oleh orang lain. Postingan ini khusus untuk pengguna windows, platform yang bisa menjalankan langsung dile EXE.
Pertama-tama siapkan dahulu file python yang akan dikonversi dilanjutkan dengan menuju ke lokasi foldernya. Klik kanan dan pilih Open in Terminal. Atau bisa masuk langsung ke Command lalu arahkan ke folder aplikasi.
In the past, students were already familiar with compiling programs into executable files. This type of file cannot be directly viewed as source code, making it safer from being reused by others. This post is specifically for Windows users, a platform that can directly run EXE files.
First, prepare the Python file that will be converted, then navigate to its folder location. Right-click and select “Open in Terminal.” Alternatively, you can directly go to the Command Prompt and navigate to the application folder.

A. Install Pyinstaller
Setelah masuk ke command prompt, install library untuk konversi ke executable, yakni pyinstaller. Ketik kode:
After entering the Command Prompt, install the library for converting to an executable, which is pyinstaller. Type the following code:
pip install pyinstaller

B. Run Pyinstaller
Setelah pyinstaller terinstall, jalankan untuk mengkonversi file py menjadi exe. Ketikan instruksi:
After pyinstaller is installed, run it to convert the .py file to .exe. Type the following command:
pyinstaller –onefile -w process.py

Proses kompilasi berjalan dengan lama tergantung kompleksitasnya. Untuk program contoh, cukup lama prosesnya (sepeminuman the). Setelah selesai, pada folder dist tampak process.exe sudah terbentuk. Selanjutnya saya pindahkan ke folder tempat akan dieksekusi. Ukurannya fantastis, 500-an Mb, dibanding dengan sebelumnya yang 1 Kb. Mungkin akibat memasukan library-library yang digunakan. Salah satunya adalah tensorflow.
The compilation process takes time depending on its complexity. For the example program, it took quite a while (around a few minutes). Once it’s done, you will see that the process.exe file is created in the “dist” folder. Next, you can move it to the folder where you want to execute it. The size of the executable file is significantly larger, around several hundred megabytes, compared to the original file size of 1 KB. This increase in size is likely due to the inclusion of the libraries used in the program. One of them is TensorFlow.

C. Cek Hasil Konversi
Berikutnya kita uji dengan menjalankan file EXE. Kebetulan di sini file exe akan diakses oleh file PHP (maaf, rumit ya). Sebelumnya diakses dengan kode pada process.php sebagai berikut:
Next, we will test the executable file by running the EXE file. In this case, the EXE file will be accessed by a PHP file (apologies for the complexity). Before accessing it, use the following code in process.php:
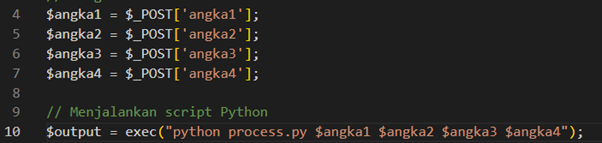
Kemudian di sini process.py akan kita ganti dengan process.exe yang baru saja kita konversi. Ganti menjadi sebagai berikut.
Then, here we will replace process.py with the newly converted process.exe. Change it as follows:

Untuk memastikan bukan file process.py yang dipakai, ganti saja (rename), misalnya xprocess.py. Setelah itu jalankan file phpnya dengan kode:
To ensure that the file being used is not process.py, simply rename it, for example, to xprocess.py. After that, run the PHP file with the following code:
php -S localhost:8000

Atau gunakan cara biasa dengan XAMPP setelah memindahkan file aplikasi ke htdocs (lihat pos yang lalu).
Alternatively, you can use the conventional method with XAMPP after moving the application files to the htdocs directory (as mentioned in the previous post).
Dengan memasukan 4 input, file html tersebut menjalankan file process.php yang menangkap inputan, selanjutnya mengakses file process.exe yang sebelumnya python. Jadi, jika ingin kode rahasia Anda tidak bisa dibuka karena file .py maka dengan .exe akan lebih aman. Lebih jelasnya lihat video youtube berikut:
By entering 4 inputs, the HTML file executes the process.php file, which captures the inputs and then accesses the previously Python file, process.exe. So, if you want to protect your secret code from being easily accessed, using .exe files instead of .py files will provide more security. For more clarity, please refer to the following YouTube video: