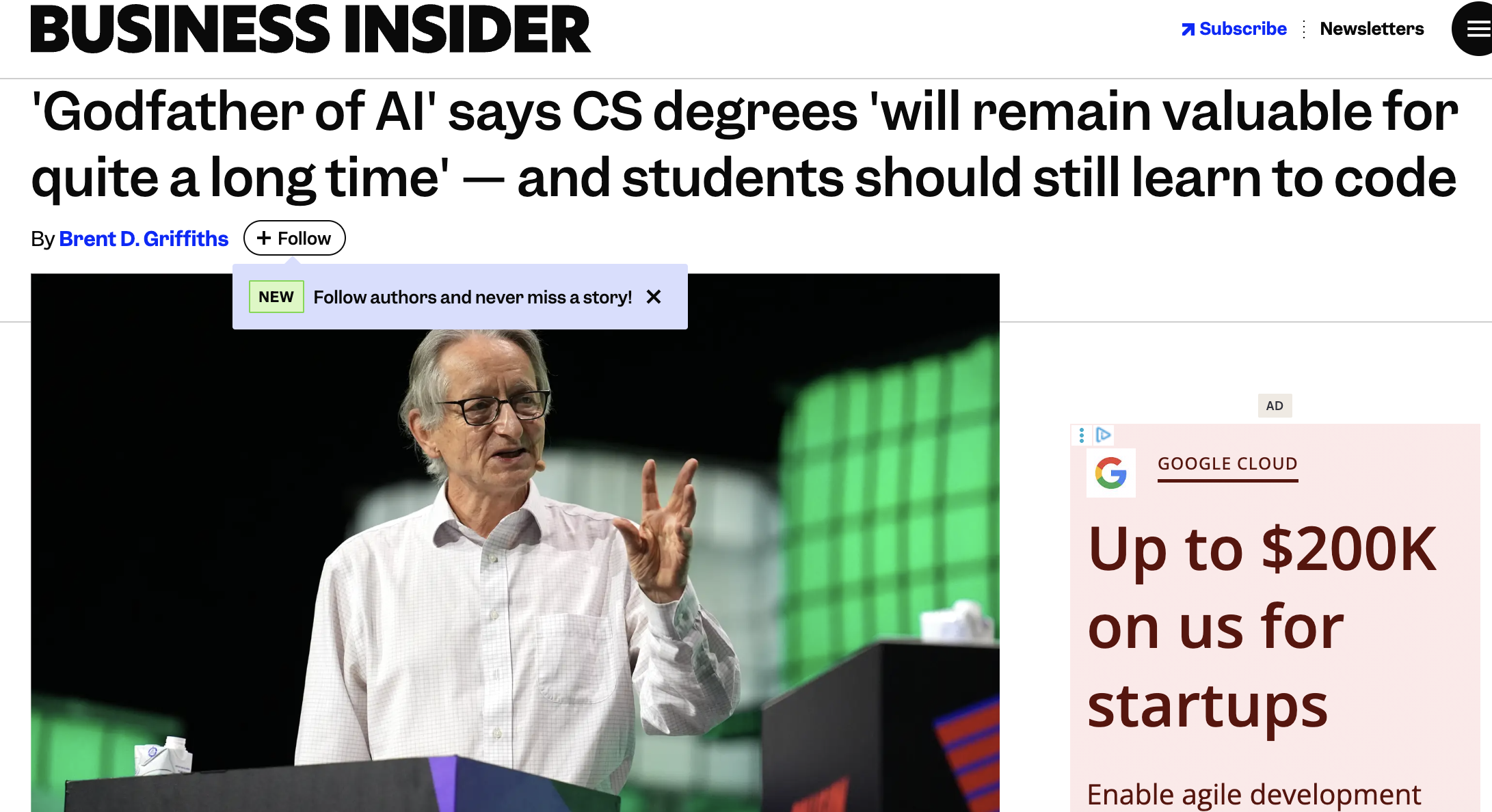
Artikel berita ini [Url] menunjukan bahwa sebagai seorang dosen dan peneliti perlu mewaspadai diri ketika menjadi anggota penulis (co-author). Kalau untuk rekan biasanya kita sudah percaya dan mudah memverifikasinya, namun yang perlu diperhatikan adalah mahasiswa bimbingan.
Salah satu hal detil yang terkadang terlewati adalah artikel referensi yang jadi rujukan. Kasus diatas menunjukan hal sepele, bisa berakibat fatal. Ternyata referensi yang ditunjukan AI adalah fiktif atau istilahnya halusinasi (hallucination), karakteristik generatif dari Large Language Models (LLMs). Sebenarnya mudah, tinggal searching saja referensinya di google lalu kalau asli dan bukan fiktif, biasanya akan muncul dan bisa kita lihat DOI dan reputasi jurnalnya. Namun karena beban yang besar (jika jumlah mahasiswa banyak), terkadang si dosen tidak sempat mengeceknya.
Terkadang penulisan jurnal memiliki penulis yang banyak, apalagi jurnal internasional. Masa sih, tidak ada satu pun co-author yang mengecek referensinya, apakah dibuat dengan AI atau tidak. Memang, dengan menarik artikel dari jurnal sudah beres, tetapi untuk kampus bereputasi (kasus di atas tingkat 11 dunia) memaksa dosen yang sekaligus dekan di satu departemen harus mengundurkan diri. Ibarat motor balap, AI (chatgpt, gemini, meta, dll) jika dikendarai oleh orang yang naik sepeda aja susah, bisa berakibat fatal.
IBM SPSS masih andalan bagi peneliti bidang apapun, baik teknik maupun sosial karena tiap penelitian kuantitatif pasti membutuhkan pengolahan data statistik baik deskriptif maupun inferensial. Penerapannya pun sangat dibutuhkan oleh orang-orang non komputer yang telah menyebar kuesioner risetnya. Walaupun Excel bisa, SPSS lebih powerful khususnya yang menggambarkan keterkaitan antar data, validasi data, hingga analisa faktor.
Saat ini bidang sains data (data science) menjadi primadona dan bahkan jadi rebutan antara orang komputer dengan statistik. Jika di suatu kampus ada mata kuliah wajib tentang sains data pasti pengajar antara orang komputer dan non-komputer akan rebutan. Bahkan di nomenklatur DIKTI pun sains data tidak milik komputer maupun MIPA. Bidang ini ada di multidisiplin (bukan ilmu formal). Nah, bagi orang non-komputer, penggunaan SPSS untuk mata kuliah sains data masih menjadi andalan.
Berikut ini video dasar-dasar SPSS yang saya ajarkan untuk mahasiswa agribisnis, fakultas pertanian. Studi kasusnya sederhana hanya mengetahui signifikansi pretest dan postest suatu data mahasiswa selama workshop atau pelatihan.
Salah satu pembeda orang yang belajar sekarang dengan jaman dulu adalah adanya Artificial Intelligence (AI). Jika jaman dulu mencari informasi itu sulit, mahal, dan perlu usaha keras, saat ini sangat mudah dan terbiasa di mana-mana (di internet). Ada informasi beberapa jurusan ter-disrupsi, misalnya programmer yang tergantikan dengan AI. Namun, mbah-nya AI mengatakan, tetap saja jurusan ilmu komputer dicari (Link).
Nah, yang membuat jurusan ilmu komputer tetap penting adalah justru ilmu-ilmu lain yang dipelajari, seperti matematika, statistika, dan sejenisnya. Walau dalam waktu beberapa bulan suatu ilmu segera usang, tetap saja skill ‘belajar’ yang diperoleh, misalnya dari belajar pemrograman, tetap melekat di sisi siswa. Seperti orang yang belajar bahasa asing, misalnya bahasa Jepang, sebenarnya ketika belajar, ada aspek-aspek tertentu yang membentuk siswa itu memiliki kemampuan mempelajari sesuatu, yang makin lama makin cepat dan mahir mempelajari hal baru.
Anda mungkin pernah membaca buku. Terkadang orang yang pesimis mengatakan bahwa tidak ada manfaatnya membaca buku, toh tidak pasti digunakan. Bahkan terkadang terlupakan dalam beberapa bulan ke depan. Namun, ketika seseorang membaca (atau mempelajari hal baru), sebenarnya manfaatnya pada terbukanya fikiran (insight) hasil dari bacaan tersebut. Bahkan ke depan seorang guru yang ‘menginspirasi’ jauh lebih penting dari apa yang diajarkan. Bagaimana siswa melihat si guru mencari letak kesalahan kode program, menyelesaikan masalah, atau pengalamannya dalam menuntut ilmu di negara asing, bisa menambah wawasan siswa. Kedekatan terkadang bisa membedakan antara offline dengan online.
Ilmu terus berkembang, dimana saat ini mungkin benar dan tepat, belum tentu di masa yang akan datang pasti tepat. Terkadang kasus-kasus tertentu tidak bisa diselesaikan dengan buku teks, sehingga muncul jurnal-jurnal yang menjabarkan hal-hal baru yang bisa mematahkan teori lama. Beberapa bidang memanfaatkan riset yang diolah kemudian dengan statistik. Kebetulan saya mengajar siswa agribisnis, fakultas pertanian UNISMA Bekasi, yang kali ini mulai masuk ke statistika terapan, dengan software SPSS. Sebelumnya video berikut masuk dulu ke Excel, guna menjebatani sebelum masuk ke software tersebut.
Peneliti dalam melakukan publikasi terkadang melibatkan peneliti-peneliti lain. Terkadang bidang ilmu yang berbeda. Untuk mengetahui informasi terkait bagaimana terlibatnya antara satu peneliti dengan peneliti lain, beberapa tools tersedia salah satunya adalah Vosviewer. Aplikasi berbasis Java ini memanfaatkan diagran network.
Selain itu suatu term atau kata kunci tertentu, yang merupakan topik penelitian, dapat dirunut pihak-pihak yang terlibat, bahkan dalam bentuk klasterisasi dalam bentuk diagram network yang cantik. Tentu saja untuk lebih detil, perlu mencari kelemahan dan kelebihan jurnal-jurnal yang jadi rujukan.
Video berikut menggambarkan bagaimana menginstal Vosviewer di Mac. Yang perlu jadi perhatian adalah Mac OS terkadang tidak bisa menjalankan Aplikasi ini. Untungnya ada versi yang dijalankan lewat Java Runtime Environmen (JRE), suatu aplikasi *.Jar.
Salah satu keunggulan dari Vosviewer adalah kemampuan memetakan siapa saja Author yang menjadi pioneer suat tema penelitian. Tentu saja diperlukan data CSV yang diperoleh dari Scopus, misalnya.
Turnitin masih menjadi andalan utama dalam pengecekan plagiasi, khususnya di dunia akademik seperti dalam penyusunan skripsi, tesis, maupun pengajuan kenaikan pangkat dosen. Meskipun pemanfaatan ChatGPT semakin meluas untuk membantu penulisan, hasil teks dari ChatGPT tetap berisiko terdeteksi oleh Turnitin jika memiliki kemiripan dengan repositori akademik seperti makalah, tugas, dan tesis; situs web umum dan artikel daring; serta dokumen yang sebelumnya telah diunggah oleh pengguna lain. Oleh karena itu, penting untuk melakukan parafrase dan menyisipkan pemikiran orisinal saat menggunakan bantuan LLM. Di sisi lain, ChatGPT juga dapat dimanfaatkan sebagai alat bantu untuk memeriksa kesalahan ketik, menyusun kalimat, hingga memperbaiki struktur penulisan agar lebih baik sebelum dicek dengan Turnitin.
Cara tersebut tergolong aman, tapi disarankan untuk tidak langsung menyalin dan menempel jawaban dari AI. Ada baiknya, ikuti langkah-langkah berikut agar tulisan tidak terdeteksi sebagai hasil buatan AI: edit teks dengan gaya penulisanmu sendiri, tambahkan opini atau sudut pandang pribadi, ubah struktur kalimat, gabungkan dengan referensi atau kutipan nyata, serta gunakan ChatGPT sebagai alat bantu, bukan sebagai sumber utama. Menulis ulang dengan gaya sendiri tidak hanya membuat tulisan lebih natural, tetapi juga memastikan konsistensi dengan style pribadi dan menghindari deteksi sistem AI writing.
Terdapat beragam skema dalam penggunaan Turnitin, dan yang paling mudah adalah melalui fitur Quick Submit. Namun, tidak semua institusi atau organisasi yang berlangganan Turnitin mengaktifkan fitur tersebut. Jika Quick Submit tidak tersedia, alternatifnya adalah menggunakan skema class-based, yaitu dengan mengunggah dokumen sebagai seorang mahasiswa (student) dalam kelas yang telah dibuat di Turnitin, terlampir ilustrasinya. Oiya, ternyata masih bisa exclude, jaga-jaga nanti diminta cek plagiasi tapi sudah publish (biasanya kena 100% similarity).
Setelah era Kampus Merdeka, kini kita memasuki era Kampus Berdampak, seiring dengan pergantian Menteri Pendidikan dari Nadiem Makarim kepada Prof. Brian Yuliarto, Ph.D., yang menjabat sebagai Menteri Pendidikan Tinggi, Sains, dan Teknologi sejak 19 Februari 2025. Salah satu tolok ukur dari dampak tersebut adalah keberadaan karya akademik yang dapat diakses publik, seperti jurnal ilmiah. Jurnal ini pun terbagi dalam berbagai kategori, mulai dari yang tidak terakreditasi namun memiliki ISSN, jurnal terakreditasi nasional (SINTA 1 hingga SINTA 6), jurnal terindeks internasional, hingga jurnal terindeks internasional bereputasi seperti yang terindeks di SCOPUS dan Web of Science.
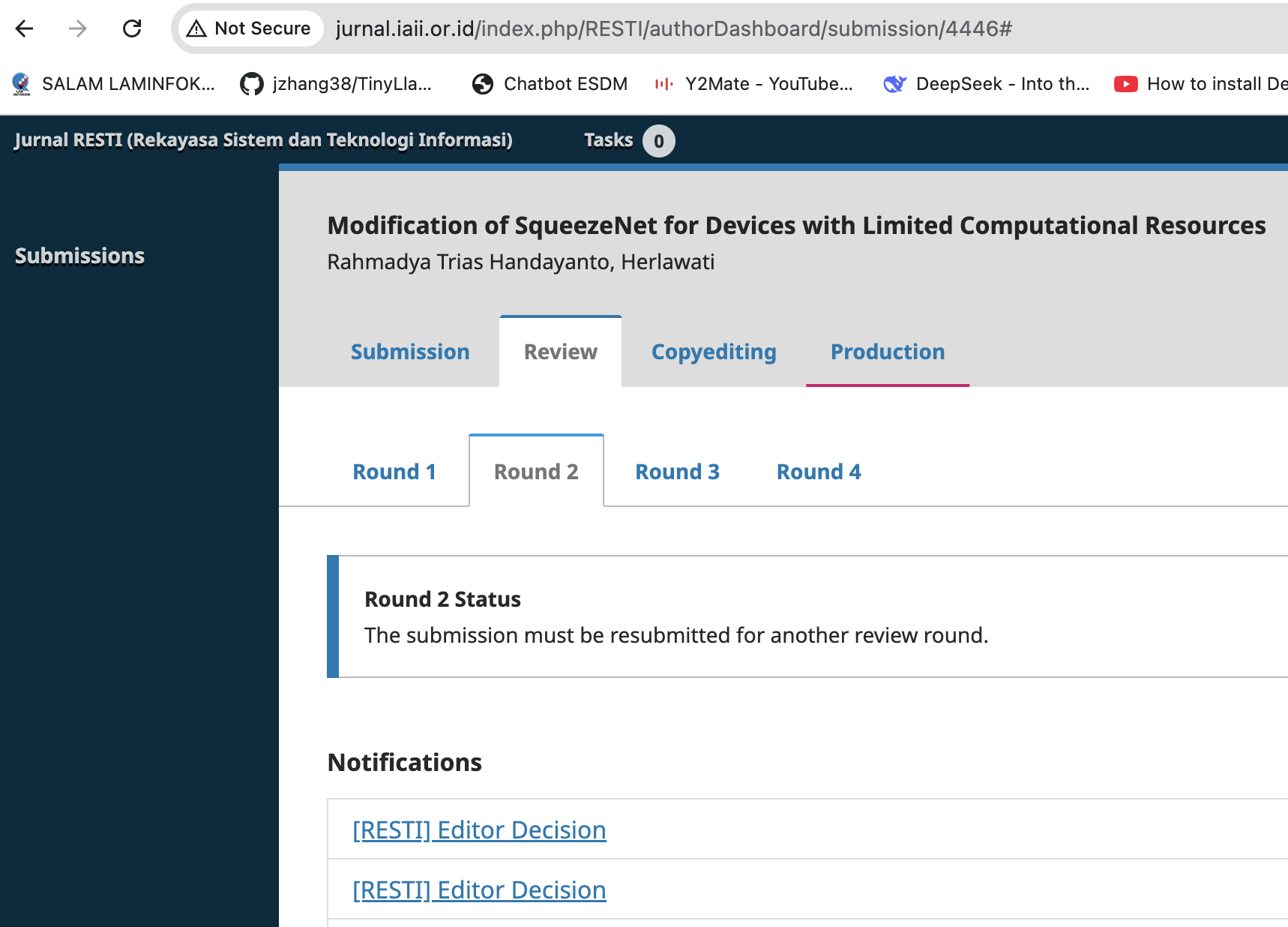
Untuk jurnal lokal, syarat minimal bagi seorang doktor yang ingin naik jabatan menjadi lektor kepala (dalam istilah internasional disebut associate professor) adalah memiliki publikasi pada jurnal nasional terakreditasi minimal SINTA-2, dan karya tersebut tidak boleh merupakan bagian dari disertasi saat studi doktoral. Karena seluruh jurnal internasional saya merupakan bagian dari disertasi, akhirnya saya mencoba untuk submit ke jurnal nasional SINTA-2, yaitu RESTI (http://jurnal.iaii.or.id/index.php/RESTI), yang diterbitkan oleh Ikatan Ahli Informatika Indonesia (IAII).
Setelah melalui proses revisi yang cukup panjang—tiga hingga empat ronde revisi—dan hampir satu tahun menunggu sejak submission, akhirnya artikel saya berhasil diterbitkan: http://jurnal.iaii.or.id/index.php/RESTI/article/view/4446.
Menulis di jurnal umumnya terbagi menjadi dua jenis: berbayar dan tidak berbayar. Sangat jarang ada penulis yang dibayar; justru dalam banyak kasus, penulislah yang harus membayar—baik menggunakan dana pribadi, dari institusi, maupun melalui sponsor. Meskipun terdengar aneh, hal ini wajar karena publikasi jurnal memerlukan biaya, mulai dari proses editorial, peer review, hingga penyediaan penyimpanan digital jangka panjang, mengingat artikel ilmiah diharapkan tersedia selamanya (selama tidak terjadi perang nuklir, he he). Untuk jurnal nasional terakreditasi SINTA-2, biaya publikasi biasanya berkisar antara 2 juta hingga 2,5 juta rupiah. Namun, tidak jarang tarif ini meningkat karena penerbit tahu bahwa banyak dosen yang membutuhkan publikasi SINTA-2 sebagai syarat utama untuk usul kenaikan jabatan fungsional akademik.
Sempat dulu saya pernah submit ke jurnal nasional yang saat itu masih terindeks SCOPUS—sayangnya sekarang sudah tidak lagi, istilahnya discontinued from SCOPUS. Waktu itu gratis karena artikelnya merupakan best paper dari sebuah konferensi, sehingga mendapat “jatah” publikasi tanpa biaya. Nah, yang ini saya submit sebagai jurnal nasional biasa. Namun karena proses editorialnya sangat baik, dan jurnal ini dikelola oleh asosiasi profesi independen, yaitu Ikatan Ahli Informatika Indonesia (IAII), yang tidak berorientasi pada profit (non-profit organization), akhirnya jurnal tersebut berhasil terindeks SCOPUS. Alhamdulillah.
Ternyata, jika kita submit ke jurnal yang sedang dalam proses pengajuan ke SCOPUS—biasanya jurnal SINTA-2, karena jurnal SINTA-1 umumnya sudah terindeks SCOPUS—ada manfaat tambahan ketika jurnal tersebut akhirnya disetujui dan resmi masuk SCOPUS. Beberapa edisi sebelumnya, terutama yang digunakan sebagai bahan evaluasi dalam proses penilaian SCOPUS, biasanya ikut terindeks juga. Sekian cerita dari saya, semoga bisa menjadi inspirasi untuk ikut berkontribusi lewat publikasi di jurnal SINTA-2. Banyak manfaat yang bisa kita peroleh dari menulis di jurnal nasional, salah satunya adalah menjaga agar devisa tidak lari ke luar negeri, sekaligus ikut mendukung peningkatan kualitas riset dan publikasi ilmiah di dalam negeri.
Dalam Remote Sensing dan (Geographic Information System) GIS, beberapa aplikasi GIS seperti ArcGIS dan QGIS (Quantum GIS) telah saya coba. ArcGIS merupakan perangkat lunak komersial yang memiliki beragam fitur canggih, seperti ArcMap dan toolbox geoprocessing, yang memudahkan pengguna dalam melakukan analisis spasial tingkat lanjut. Di sisi lain, QGIS dikenal sebagai alternatif open source yang tidak kalah powerful, dengan komunitas pengguna yang aktif serta dukungan plugin yang beragam.
Dalam praktiknya, data spasial diunduh dari sumber resmi seperti portal Tanah Airku, yang menyediakan data vektor maupun raster untuk wilayah Indonesia. Data tersebut kemudian digunakan dalam berbagai analisis, seperti clip untuk memotong area berdasarkan batas administrasi, buffer untuk menentukan zona pengaruh dari suatu objek (misalnya rumah sakit), serta visualisasi berbagai layer seperti jaringan jalan, fasilitas kesehatan, dan penggunaan lahan di wilayah Kota Bandung.
Proses ini dianggap sangat penting untuk mendukung berbagai kebutuhan analisis spasial, terutama dalam bidang teknik sipil. Profesi ini sering kali memerlukan informasi geospasial yang akurat dan terstruktur, serta menggunakan software berlisensi untuk mendukung kegiatan perencanaan, pemetaan, hingga pengambilan keputusan berbasis lokasi. Dengan pemahaman dan keterampilan dalam penggunaan GIS, data spasial dapat dimaksimalkan untuk menjawab tantangan nyata di lapangan.
Assalamualaikum pengguna Mac! Terkadang kita dipusingkan dengan aplikasi berbayar untuk mengedit PDF. Namun, dengan aplikasi PDF Reader Pro, kita bisa memanfaatkan fasilitas gratisnya untuk memotong halaman PDF. Caranya cukup mudah, pertama, buka file PDF dengan aplikasi tersebut. Kemudian, untuk memotong halaman tertentu, gunakan fitur “Print”, lalu pilih “Range From” dan tentukan halaman yang ingin dipotong. Setelah itu, pilih “Save as PDF” di bagian bawah dan beri nama sesuai keinginan. Dengan cara ini, kita bisa menyimpan halaman yang diinginkan tanpa harus menggunakan aplikasi berbayar.
Selanjutnya, bagaimana jika ingin menggabungkan beberapa halaman PDF, misalnya menggabungkan cover dengan isi dokumen? Caranya hampir sama dengan langkah sebelumnya. Pilih opsi “Print” dan tentukan halaman yang ingin digabungkan. Setelah itu, simpan hasilnya dengan nama baru, misalnya “Isi”. Jika ingin menyisipkan cover dengan isi, buka terlebih dahulu file cover, lalu di menu “File” pilih “Merge PDFs”. Selanjutnya, pilih file isi yang ingin digabungkan dengan cover, lalu beri nama baru untuk file hasil gabungan tersebut.
Setelah selesai, cek hasilnya dan pastikan halaman telah tersusun dengan benar. Dengan trik ini, kita bisa memotong dan menggabungkan halaman PDF tanpa perlu aplikasi berbayar. Meskipun ada aplikasi online yang bisa digunakan, namun ada risiko data kita diambil tanpa izin. Dengan menggunakan PDF Reader Pro, kita bisa mengedit PDF dengan aman dan gratis. Semoga tutorial ini bermanfaat. Wassalamualaikum warahmatullahi wabarakatuh.
Beberapa aplikasi chatbot sudah mendukung mode offline, sehingga tidak memerlukan koneksi internet untuk beroperasi. Dengan fitur ini, pengguna tetap dapat mengakses berbagai layanan seperti pembuatan ringkasan atau analisis teks tanpa harus terhubung ke server online. Namun, penggunaan chatbot offline memiliki keterbatasan, salah satunya adalah kebutuhan perangkat dengan prosesor CPU dan GPU yang cukup tinggi agar proses berjalan lancar.
Salah satu keuntungan utama dari chatbot offline adalah privasi yang lebih terjaga. Karena data tidak dikirim ke server eksternal, risiko informasi tersebar atau dibagikan secara tidak sengaja ke pihak lain dapat diminimalkan. Dalam pengujian terhadap sebuah paper ilmiah, chatbot offline mampu mengenali bahwa dokumen tersebut adalah studi literatur yang berisi ringkasan berbagai penelitian terdahulu. Dengan demikian, pengguna dapat dengan cepat memahami konteks dokumen tanpa harus membaca seluruh isinya.
Meskipun hasil yang diberikan cukup baik, chatbot offline masih memiliki keterbatasan dalam memahami dan menyajikan informasi. Dalam beberapa kasus, penggunaan prosesor yang tinggi dapat mempengaruhi kinerja perangkat, terutama jika dokumen yang diproses sangat kompleks. Namun, chatbot ini tetap memberikan manfaat dengan kemampuannya membaca abstrak, mengenali isi utama, serta memberikan gambaran umum dari sebuah artikel sebelum pengguna membacanya lebih lanjut.
Scopus dapat dimanfaatkan untuk studi literatur atau Systematic Literature Review (SLR) dengan fitur pencarian kata kunci dan filter waktu. Pengguna bisa mengunduh abstrak atau full paper jika kampus memiliki langganan jurnal, sementara paper open access dapat diakses gratis. Scopus membatasi unduhan hingga 50 paper per batch, sehingga proses harus dilakukan bertahap jika jumlahnya banyak.
Untuk mempercepat analisis, AI seperti ChatGPT dapat digunakan untuk meringkas paper, mengekstrak novelty, atau mencari informasi spesifik dalam dokumen PDF. Fitur upload PDF di ChatGPT kini tidak memiliki batasan jumlah halaman, hanya dibatasi ukuran maksimal 20 MB, sehingga mempermudah peneliti dalam meninjau referensi dengan lebih efisien.
Baik skripsi, tesis, maupun disertasi tidak lepas dari diagram. Biasanya diagram digunakan ketika menggambarkan flow atau alur dari penelitian, yang dikenal dengan istilah framework. Atau diagram standar lainnya yang menggambarkan prosedur, roadmap, dan sejenisnya. Karena keterbatasan waktu, biasanya siswa mengopi saja dari internet, padahal jika menggunakan gambar hasil karya orang lain perlu menginformasikan sumbernya. Maka, para siswa perlu dibekali kemampuan dengan cepat membuat sendiri diagramnya.
Banyak aplikasi baik online maupun di laptop yang menyediakan hal tersebut. Beberapa mungkin terlalu ‘canggih’ sehingga mahasiswa enggan mempelajarinya. Namun, jika mendengar kata ‘power point’, tentu saja sebagian besar mahasiswa pernah memakainya. Nah, tidak ada salahnya dari pada plagiasi gambar dari internet, lebih menggunakan aplikasi bawaan microsoft office saja untuk membuat diagram.
Jika tidak memiliki lisensi Microsoft Office, bisa menggunakan WPS Office yang isinya tidak jauh berbeda dengan Microsoft Office. Tentu saja jika menggunakan alat yang canggih seperti Microsoft Visio, hasilnya lebih baik. Atau bisa menggunakan aplikasi online web io atau Canva. Tentu saja yang online membutuhkan biaya pulsa, atau setidaknya waktu respon yang sedikit lambat karena online. Untuk adik-adik yang sedang skripsi, bisa menggunakan alternatif murah dengan power point. Silahkan lihat ilustrasi dari video berikut. Semoga sedikit membantu.
Sitasi dan daftar pustaka merupakan hal-hal wajib yang ada dalam sebuah artikel ilmiah, baik jurnal, skripsi, disertasi, dan sejenisnya. Saat ini, walau banyak tool untuk otomatisasi pengelolaannya, Mendeley masih menjadi andalan penulis-penulis di dunia. Dengan menambahkan koleksi ke Mendeley, tinggal klik langsung sitasi muncul di daftar pustaka, khusus yang Mendeley desktop.
Salah satu yang menjadikan aplikasi ini disukai orang adalah gratis, berbeda dengan yang lain yang dipaksa berbayar. Nah, entah mengapa pengguna Mendeley desktop seolah dipaksa menggunakan Mendeley reference manager. Beberapa sumber menyebutkan adanya peralihan aplikasi ke online yang lebih ringan, yang jelas Mendeley tidak lagi mensuport Mendeley desktop. Sepertinya ketika penulis sudah nyaman dengan Mendeley desktop, Mendeley.Com mungkin mengalami kemunduran dari sisi akses karena jarang yang membukanya. Itu dugaan saya saja sih.
Nah, bagaimana pengguna yang sudah terbiasa dengan Mendeley desktop tetapi dipaksa mendeley reference manager? Tidak jadi masalah karena kita masih bisa menginstal aplikasi tersebut dan mengunduh source code nya di internet (Link). Plug in agar terpasang di MS Word sepertinya perlu cara khusus bagi pengguna Macbook, lihat tutorial berikut.
Tentu saja Microsoft Word perlu dimiliki oleh pengguna Mendeley. Bagaimana dengan WPS Office yang saat ini mulai banyak diminati. Pengguna MS Word tidak akan memiliki masalah berarti jika beralih ke WPS Office, khususnya yang ingin mengetik di tablet. Saya mencoba mengetik di tablet Huawei ternyata mirip dengan menggunakan laptop.
Nah, bagaimana untuk mengetik jurnal atau artikel ilmiah lainnya? Silahkan lihat caranya di video berikut.
Apapun tools nya, kita harus bisa beradaptasi. Yang penting tetap produktif dalam menulis.
Ada istilah Desember itu “gede-gede nya sumber”, dan Januari “Hujan Sehari-hari”. Nah, hujan sudah biasa terjadi di bulan Desember ini. Namun demikian, aktivitas harus terus berjalan, termasuk seminar INCREASING di Universitas Islam 45 Bekasi. Dimulai pukul 09.00 Acara seminar dengan pembicara Prof Nurul Huda dari Universitas Yarsi membahas bagaimana peluang dan tantangan penelitian dan pengabdian pada masyarakat di kampus.
Setelah pemberian penghargaan skor Sinta tertinggi di kampus, baik all years, three years maupun penerbitan buku, HKI, dan sejenisnya, lanjut ke parallel session yang dimulai Jam 13.00 secara daring dengan Zoom.
Seperti biasa, foto-foto merupakan acara heboh karena bisa menjadi kenangan tersendiri. Terkadang penghargaan tidak harus dalam bentuk uang. Sekedar apresiasi saja sudah membuat bahagia.
Acara seminar merupakan acara bertukar fikiran antara satu peneliti dengan peneliti lainnya. Terkadang walau beda disiplin ilmu, tetap saja alur berfikir dapat dimengerti, karena metode ilmiah tetap sama antara satu bidang ilmu dengan bidang ilmu lainnya.
Semoga acara seperti ini terus rutin dijalankan. Keakraban dan peningkatan mutu dijamin pasti berjalan.
Jika Anda membaca literatur kuno India, khususnya agama Budha, sesuatu itu muncul akibat ketidaktahuan. Terlepas percaya atau tidak, hal-hal yang dulu tidak ada dan sekarang ada akibat hal tersebut. Kita mungkin sudah lupa atau tidak sadar bagaimana ketika bayi kita tidak tahu bagaimana caranya mensuplai makanan ke tubuh kita. Jadi, ketidaktahuan akan sesuatu memantik problem yang harus diselesaikan. Ketidaktahuan memancing keingintahuan, dan memunculkan ilmu-ilmu baru. Ok, filsafat mungkin memusingkan, postingan ini kita membumi saja.
Problem Jangka Pendek
Dari kecil kita sudah mampu menyelesaikan problem-problem yang tidak perlu membutuhkan pemikiran mendalam. Dengan bertanya, searching di internet, dan kegiatan sederhana lainny bisa menyelesaikan problem sederhana. Repotnya kebanyakan soal-soal di bangku sekolah masuk kategori ini, sehingga ketika anak itu kuliah, ada kebingungan, khususnya ketika muncul problem yang perlu pemikiran mendalam.
Problem Jangka Panjang
Berbeda dengan problem jangka pendek yang sederhana, problem jangka panjang memerlukan pemikiran yang mendalam, terkadang berupa tahapan-tahapan yang harus dilalui oleh seorang anak/pelajar. Terkadang berbeda dengan problem sebelumnya yang bisa dilakukan lewat kursus, pelatihan, dan sejenisnya, problem jangka panjang membutuhkan effort untuk menyelesaikannya. Usaha tersebut terkadang meminta ‘tumbal’. Banyak rekan-rekan saya yang tidak kuat, sakit, bahkan meninggal dunia. Seorang anak yang cerdas dan terlatih menyelesaikan problem-problem singkat berupa soal-soal ujian terkadang kewalahan ketika problem harus diselesaikan tidak dalam waktu beberapa menit saja, bisa satu hari, satu bulan bahkan satu tahun, yang jika tidak sabar akan mengganggu pikirannya.
Repotnya banyak problem-problem jangka panjang yang butuh pemikiran mendalam harus diselesaikan oleh seorang anak yang harus memutuskan masa depannya, misalnya melanjutkan jurusan/bidang apa, karir apa yang akan diambil, bekerja di mana dan sebagainya yang tidak bisa dilakukan dengan cepat karena harus memikirkan secara mendalam. Bagi yang pernah mengambil doktor, sudah pasti mengenal tipe problem ini.
Salah satu buku ternama ‘furute skills‘ membahas bahwa problem solving merupakan skill utama di atas critical thinking dan creativity ya karena memang problem-solving merupakan induk dari keberlangsungan hidup umat manusia. Jadi cara paling mudah dalam belajar adalah dengan ingin mencari tahu hal-hal yang tidak/belum diketahui. Ketika membaca, kuliah, atau aktivitas lain jika Anda berhasil memancing keingintahuan, dipastikan ada yang ‘berbekas’ dari aktivitas itu … minimal tidak tertidur.
Model merupakan konsep yang menggambarkan kondisi real. Awalnya disebut model matematis, tetapi untuk mempersingkat biasanya disebut model saja. Ada model fisika, teknik, dan ada juga model ilmu sosial, misalnya pada faktor-faktor yang berpengaruh satu sama lain. Model yang ada biasanya merujuk pada penelitian sebelumnya, jadi kita tidak diperbolehkan asal membuat model tanpa ada rujukan. Misalnya pada postingan ini model yang mengecek apakah faktor-faktor pelayanan, kepuasan dan loyalitas saling berpengaruh.
Banyak tools yang dapat digunakan, misalnya LISREL dan AMOS. LISREL merupakan model yang telah lama dikenal, sementara AMOS merupakan tool baru yang kini menjadi bagian dari IBM yang sudah terlebih dahulu terkenal dengan SPSS. Postingan yang lalu telah dibahas model analisis Jalur [Link], nah kali ini kita coba untuk Confirmatory Factor Analysis. Silahkan lihat tayangan berikut yang mengilusrasikan secara singkat CFA dengan AMOS graphic.