Saat ini, Artificial Intelligence (AI) telah menjadi “tokoh utama” dalam perkembangan teknologi modern. Menariknya, AI dapat berperan sebagai tokoh baik maupun tokoh buruk (villain). Di satu sisi, AI memudahkan pekerjaan manusia; namun di sisi lain, sifatnya yang instan sering membuat orisinalitas hilang, menumbuhkan rasa malas, dan menimbulkan ketergantungan. Meski begitu, manfaat yang dirasakan pengguna tetap sangat besar.
Salah satu kemampuan AI yang paling populer saat ini adalah sifat generatifnya (generative AI), misalnya dalam membuat presentasi. Dengan hanya memberikan prompt tertentu, model yang dikenal dengan nama Large Language Models (LLMs) mampu menghasilkan konten sesuai permintaan, termasuk pembuatan slide PowerPoint.
Jika dahulu chatbot hanya memberikan saran atau rekomendasi, kini telah berkembang menjadi action chat: chatbot tidak hanya memberi saran, tetapi juga mengeksekusi perintah secara langsung. Apakah hal ini berbahaya? Tentu saja ada potensi risikonya. Anda mungkin teringat film Mission Impossible yang dibintangi Tom Cruise, di mana AI mampu mengeksekusi tindakan berbahaya seperti pengeboman tanpa melibatkan manusia.
Dalam contoh yang lebih aman, berikut ini adalah demonstrasi action chat di mana chatbot mengeksekusi pembuatan file PowerPoint yang dapat langsung diunduh. Materi presentasi diambil dari file PDF yang diunggah pengguna, kemudian diproses menjadi database vektor menggunakan teknologi seperti FAISS, Chroma, Pinecone, dan lainnya. Proses ini dalam istilah teknis dikenal dengan nama Retrieval-Augmented Generation (RAG).
Udara pagi di desa membuat segar setelah semalaman tidur nyenyak karena lelah akibat perjalanan Bekasi ke Ciamis di malam hari. Menyusuri jalan beraspal sambil memandang sawah yang masih hijau membuat rileks hati. Sesekali kendaraan melalui jalan itu diselingi dengan bunyi jangkrik di pinggir kali.
Kebetulan di dekat rumah bibi ada gedung yang akan dijadikan dapur makan bergizi, proyek dari presiden Prabowo, sesuai dengan janji saat kampanye dulu. Postingan ini hanya selingan terkait dengan perang AI antara Amerika Serikat dengan China. Lalu apa hubungannya dengan proyek makan bergizi Prabowo?
Ketika tulisan ini dibuat, baru saja saya menginstal DeepSeek dari China yang diberikan mesin AI-nya secara cuma-cuma. Berbeda dengan ChatGPT dimana GPT tidak bisa kita pasang di laptop atau server kita, bahkan untuk memanfaatkan GPT untuk aplikasi yang dibuat perlu berlangganan. Itu pun hanya berupa Application Programming Interface (AI) dan mesin AI tidak berada di server kita.
China secara mengejutkan membuat mesin AI yang kabarnya lebih canggih dari ChatGPT, khususnya di bidang matematis. Sebelumnya Alibaba memang menampilkan QWEN yang memiliki ketangguhan mirip ChatGPT, dengan kekhususan di bidang bisnis. Tentu saja dengan DeepSeek, aplikasi-aplikasi berbasis LLM dan Generative AI yang tadinya berlangganan ChatGPT pasti berhenti berlangganan. Berikut video untuk menginstall DeepSeek versi mini (diberi istilah distilled atau hasil penyulingan) agar bisa dipasang di laptop atau server kecil. Ukuran bervariasi dari 1,5 gigabyte hingga 400-an Gb.
Jika dibandingkan ternyata untuk pertanyaan sederhana sepertinya ChatGPT masih lebih praktis dan cepat, apalagi di Macbook ada fasilitas menekan Option+Space untuk mengaktifkan ChatGPT instan. Ini merupakan keunggulan ChatGPT dimana versi onlinenya selalu ok, berbeda dnegan DeepSeek yang terkadang “busy”, karena tidak sanggup menjawab pertanyaa orang-orang seluruh dunia. Tapi tetap saja kita bisa memasang secara offline yang tidak perlu pulsa di komputer atau laptop kita.
Untuk interface, banyak aplikasi yang menyediakan selain Chatbox, salah satunya yang saya coba adalah LM Studio. Kemampuan DeepSeek dalam DeepThink bisa dilihat, dan tentu saja fasilitas upload PDF tersedia, walaupun di ChatGPT pun bisa upload PDF. Jadi jika kita malas membaca paper, tinggal upload file pdf paper/artikel ilmiah dan tanya saja atau minta resume.
Jadi dengan AI anak-anak kita dengan mudah belajar apapun. Tinggal bagaimana otak anak-anak kita bisa segera menyerap ilmu yang sekarang bebas diakses. Jadi sebesar apapun biaya untuk fasilitas pembelajaran, jika otak anak-anak kita ‘melempem’ sepertinya mubazir. Lebih baik investasi ke kecerdasarn generasi kita ke depan, karena kalau sudah cerdas, tinggal diasah mental (keimanan, cinta tanah air, dan lain-lain) dan belajar dari media apapun, terutama memanfaatkan Artificial Intelligence (AI).
Kira-kira satu atau dua tahun yang lalu, beberapa proyek meminta untuk implementasi AI di aplikasi berbasis web. Kebetulan karena jamannya pilpres dan pilkada, teknik scrapping berita di media online kemudian mengecek sentimen dan emosi dari postingan banyak yang minta. Alhasil mengingat keterbatasan yang ada, Naive Bayes, SVM dan metode klasik lainnya jadi andalan. Dengan data terbatas bisa dilatih model yang mampu mengetahui sentimen dari berita online, dengan akurasi yang tidak jauh dari 80%.
Waktu itu ChatGPT mulai muncul dan tentu saja mengalahkan model-model klasik lainnya. Salah satu keterbatasannya adalah jika ingin memanfaatkan fasilitas model GPT itu, harus berlangganan, dan karena berbasis Application Programming Interface (API), mesin AI tidak berada di sisi kita, melainkan hanya ‘menyewa’. Biayanya pun tidak tanggung-tanggung, hitungan per kata.
Untuk menghitung sentimen, dengan metode klasik pun bisa, tapi jika diminta membuat ringkasan (summary), meringkas, melaporkan (reporting), tentu saja mengandalkan model LLM gratis, waktu itu masih kurang akurat. Namun toh, aplikasi bisa berjalan dengan tetap pengguna mengecek ulang keakuratannya dan tidak serta-merta percaya.
Waktu terus berjalan, Donald Trump tampil dan mengumumkan perang dagang dengan China. Nah, di sinilah muncul DeepSeek, AI buatan China yang mengungguli ChatGPT dari sisi kalkulasi matematis. Bukan hanya itu, mesin AI-nya pun dibagikan secara cuma-cuma dalam skema Opensource. Sehingga pengguna tidak perlu berlangganan jika ingin memanfaatkan Generative AI tersebut. Bayangkan, bagaimana hebohnya pengguna yang sudah terlanjur berlangganan ChatGPT, dipastikan akan beralih ke yang gratis. Walaupun tentu saja masih banyak yang ragu, tapi toh, model yang dibagikan itu karena open source, bisa terlihat struktur dalamnya. Ada beberapa bias, khususnya informasi terkait Taiwan, yang menurut DeepSeek masih bagian dari China. Sebelumnya, model QWEN dari Alibaba juga mulai menyaingi ChatGPT, yang cocok untuk bisnis, tapi dari sisi matematis masih kalah dengan DeepSeek.
Kelebihan DeepSeek ternyata tidak didukung oleh situs onlinenya yang terkadang ‘sibuk’ ketika ditanya, terutama ketika memanfaatkan fasilitas ‘deepthink’ dan ‘web’. Namun, toh bisa kita install di laptop kita dan dapat berjalan walau tanpa terkoneksi ke jaringan, sangat cocok untuk yang tidak punya pulsa. Berikut video bagaimana menginstallnya di Mac, dengan bantuan situs Ollama [Link] dan interface Chatbox [Link].
Terkadang kita mengalami kesulitan memahami sesuatu yang abstrak. Apalagi jika disajikan dalam bentuk kalimat. Beberapa terkadang kurang memahami notasi-notasi matematis ala jurnal ilmiah. Jika sudah memahami, terkadang perlu waktu lagi mengimplementasikannya dalam sebuah aplikasi dengan bahasa pemrograman tertentu.
Nah beberapa aplikasi, terutama yang berbayar berusaha membantu pengguna dalam memahami metode-metode yang ada, misalnya Matlab. Selain menyediakan panduan online di situs resminya [Url] juga menyediakan link youtube yang berisi simulasi menarik. Misalnya kasus LSTM berikut ini.
Atau teori konvolusi berikut ini yang jika dijabarkan dalam notasi matematis sangat membingungkan bagi yang tidak terbiasa.
Beberapa aplikasi free seperti Google Colab juga tidak kalah dalam menyajikan implementasi dalam format Jupyter Notebooknya yang berisi gambar dan teks penjelasan yang menarik. Selain membaca teori, bisa langsung di running, seperti Google Colab ini [Url]. Selamat mencoba.
Kali ini kita akan membahas AI secara umum, khususnya yang kerap diimplementasikan saat ini.
Tidak dapat dipungkiri AI sudah merambah ke segala bidang dari kedokteran, ekonomi, teknik, hingga bidang sosial. Perkembangannya pun sangat pesat dengan tingkat akurasi tiap model yang hampir mendekati 100%.
AI yang memiliki ruang lingkup yang lebih luas saat ini mulai mengerucut ke Machine Learning karena memiliki keunggulan dibanding model AI yang lain. Hal ini berkaitan dengan ketersediaan data besar (Big Data) yang mudah diakses. Dengan berbekal sebuah data, model Machine Learning dapat dilatih untuk menghasilkan model dengan akurasi yang lebih baik dari model AI non Machine Learning.
Gambar berikut merupakan karakteristik penerapan model Machine Learning AI saat ini. Model learning yang dipakai pada gambar tersebut adalah Supervised Learning. Model learning lainnya adalah Unsupervised Learning dan Reinforced Learning.
Saat ini banyak situs-situs yang menyediakan model yang sudah dilatih, dikenal dengan istilah pre-trained model. Situs-situs tersebut dikenal dengan nama hub yang dapat diakses dan dimanfaatkan oleh publik.
Tipe yang pertama adalah pengguna hanya menggunakan pre-trained dari hub. Bentuknya ada yang menggunakan Application Programming Interface (API) dan ada pula yang modelnya bisa diunduh untuk digunakan. Salah satu keuntungan API adalah pengguna hanya bisa memanfaatkan kecerdasan yang dimiliki model tetapi tidak bisa mengunduh modelnya. Sementara hub kebanyakan membolehkan pengguna mengunduh model pre-trained nya.
Model jenis pertama ini misalnya adalah mentranslate bahasa dari bahasa Indonesia ke bahasa Inggris berikut ini. Ketika kalimat diinputkan maka dihasilkan translate-nya ke bahasa Inggris. Dengan API kita tidak perlu masuk ke situs penyedia translate, misalnya Google Translate atau yang saat ini terkenal ChatGPT.
Model ML jenis kedua yang banyak juga dipakai adalah dengan melatih ulang model pre-trained dengan data khas karena akan digunakan untuk lingkungan tertentu. Mekanisme ini dikenal dengan nama Transfer Learning. Ketika training, bobot yang sudah dilatih sebelumnya dengan data berukuran besar ditahan agar tidak berubah, yang dikenal dengan istilah freeze.
Sebagai contoh adalah penggunaan chat bot dengan model dari hub bernama hugging face. Di sini model yang sudah dilatih memiliki kemampuan menjawab pertanyaan dari serangkaian paragraf. Dengan AI pertanyaan yang berbeda-beda terhadap hal yang sama akan menghasilkan jawaban yang sama berdasarkan informasi tertentu.
Di sini data spesifik misalnya data informasi pendaftaran seperti syarat-syarat, kapan mulai perkuliahan, biaya kuliah, dan sebagainya dapat diberikan ke sistem, misalnya dalam format Comma Separated Value (CSV).
Jika ditanya hal tertentu maka sistem akan menjawab sesuai dengan data CSV tersebut. Hal ini mengurangi beban humas dalam menjawab pertanyaan-pertanyaan konsumen atau pihak-pihak lain yang berkepentingan.
Model yang ketiga adalah model yang dilatih dengan data sendiri tanpa memanfaatkan model pre-trained. Hal ini terjadi biasanya karena tidak ada pre-trained model yang tersedia. Atau model tersebut memang bukan dari model standar melainkan model yang baru dibuat. Biasanya bermaksud meningkatkan performa model usulan tersebut. Nah, di sini tantangannya adalah selain membutuhkan data yang besar, juga memerlukan sumber daya hardware dengan GPU dan RAM yang kuat.
Sebagai contoh adalah model yang melatih mesin kategori teks. Di sini sebuah mesin, misalnya SVM dilatih dengan data latih yang sudah memiliki label berupa kategori misalnya ideologi, politik, ekonomi, sosial-budaya, pertahanan dan keamanan. Setelah dilatih, maka sebuah AI mampu mengkategorikan sebuah teks menjadi salah satu dari kelima kategori tersebut. Mungkin otak kita lebih baik dari mesin AI tersebut, tetapi untuk jutaan naskah yang muncul di internet dan kita harus mengkategorikan secara menual tentu saja tidak efisien. Di sini lah salah satu peran AI (think/do rationally) yang merupakan kuadran AI menurut buku AI karya Russell. Ok, semoga postingan ini membantu.
Beberapa postingan di medsos tentang foto-foto yang dimodif tertentu dengan bantuan AI, entah tambah tua atau tambah muda menunjukan kemampuan AI dalam melakukan pembuatan (genarating) obyek. Awalnya Naive Bayes bisa digunakan untuk menggenerate obyek berdasarkan fitur tertentu, namun karena karakternya yang memang ‘naive’ maka kesulitan dihadapi karena tidak adanya hubungan antar variabel, padahal seharusnya ada. Model yang mampu melakukan hal tersebut adalah Variational Auto-Encoder (VAE).
VAE memiliki tiga komponen yakni encoder, latent space dan decoder. Encoder menghasilkan latent space yang menyimpan ciri dalam bentuk distribusi. Dan encoder membangkitkan kembali dalam bentuk varian baru yang mengambil dari distribusi. Jadi dimana letak AI-nya? Tentu saja dari kemampuan membuat variannya, dimana obyek baru yang dibentuk bukan obyek awal dan benar-benar diciptakan dari ekstraksi fitur obyek awal yang berupa distribusi.
Gambar di atas memperlihatkan sistem yang mampu membuat ulang angka-angka dari obyek awalnya (bagian bawah). Beberapa ada kesalahan, khususnya di angka 8 dan 4 yang memang mirip dengan 5 dan 9. Untuk lebih jelasnya silahkan coba jalankan kode Colab berikut [link].
Majalah TIME membahas Artificial Intelligence (AI) yang merambah ke segala bidang. Banyak peran manusia yang tergantikan, misalnya bagian informasi yang menjawab pertanyaan dari customer. Tadinya berupa chat dengan manusia, sekarang digantikan oleh mesin. Banyak kekhawatiran dari pekerja yang terancam digantikan tugas-tugasnya. Namun efisiensi sangat penting dalam tiap organisasi dan manusia seharusnya fokus ke bidang-bidang tertentu seperti kreativitas dan hal-hal yang tidak bisa dijalankan oleh mesin.
Saat ini Pre-Trained Model banyak tersedia dalam hub-hub di internet. Dengan data yang besar dengan mesin super komputer, aplikasi dishare oleh hub-hub tersebut. Untuk meng-kustomisasi aplikasi sesuai dengan problem yang ada mekanisme Transfer Learning sangat membantu karena tidak perlu Big Data dengan super computer untuk training.
Mula-mula model dibuat dengan Google Colab, sebelum diunduh modelnya agar bisa digunakan untuk aplikasi Web. Gunakan ChatGPT untuk merakit aplikasi Web, misalnya dengan Framework FLASK. Banyak yang mengatakan AI tidak mengalahkan manusia, tapi manusia dikalahkan oleh orang yang menggunakan AI. Jadi pekerja yang paham AI diyakini bisa menyingkirkan pekerja yang tidak paham AI. Di majalah TIME juga disebutkan bagaimana memanfaatkan AI yang ada untuk mempermudah pekerjaan. Berikut video bagaimana mengimplementasikan model yang diuji coba di Google Colab dalam aplikasi web dengan framework FLASK. Semoga informasi ini membantu.
Bahasa pemrograman merupakan bahasa juga karena ketika dibuat memanfaatkan kombinasi antara bahasa manusia dan bahasa mesin. Ada satu mata kuliah di ilmu komputer, namanya teknik kompilasi. Sempat mengajar mata kuliah ini dengan memanfaatkan software lex and yacc. Aplikasi ini bisa membuat syntax bahasa baru, misalnya mengganti if – else menjadi jika – maka dengan memanfaatkan reguler expression di bahasa c++.
Di manakah keunikannya? Tentu saja mahasiswa bisa melihat bahwa bahasa pemrograman yang kita lihat sehari-hari merupakan buatan manusia yang tidak perlu diagung-agungkan. Dahsyat memang bisa membuat bahasa sendiri, atau minimal untuk lingkungan sendiri yang bikin hacker ‘bingung’ karena syntax-nya lain dari yang lain.
Kembali ke bahasa Prolog, bahasa ini mirip CLIPS yang dipakai untuk belajar Sistem Pakar (expert system) yang biasa juga digunakan untuk belajar Artificial Intelligence (AI). Untuk belajar cepat, saat ini cukup dengan bertanya ke ChatGPT maka dengan cepat kita bisa mencoba bahasa pemrograman legendaris ini. Silahkan gunakan aplikasi online yang tidak memerlukan instalasi di laptop kita [Url]. Istilah-istilah entailed di buku AI, misalnya karangan Russel bisa diimplementasikan di sini. Selamat mencoba.
“Bapak sudah beritahu ke mahasiswa belom info itu?”, tanya rekan saya yang staf dan mendapat tugas sebagai call center yang menjawab WA saat COVID yang lalu. “Sudah .. kenapa Mbak?”, tanyaku heran. “Ini anak kok pada nanya semua ke call center!”. Terus terang saya cuma bisa melongo mendengar protesnya. Aneh juga, tugasnya call center yang menjelaskan ke orang yang nanya. Apalagi yang nanya mahasiswa yang notabene adalah konsumen yang menghidupi roda kampus.
Mungkin karena membludaknya mahasiswa yang bertanya akibatnya kewalahan menjawab, mungkin jempolnya sampai bentol klak-klik hp nya. Ketika kondisi seperti ini maka masuklah Artificial Intelligence (AI) yang secara perlahan menggantikan fungsi manusia yang bisa capek/lelah, bosan, dan sejenisnya. Khususnya untuk fungsi-fungsi rutinitas, administratif, dan lainnya yang bikin BT.
Dalam bukunya, Artificial Intelligence – a Modern Approach, Russel menyinggung bagaimana di awal perkembangan AI, Alan Turing mencetuskan Turing Test yang menguji sebuah mesin dengan cara Chatting. Seseorang akan diminta menebak lawan chattingnya apakah manusia atau mesin. Waktu itu mungkin masih bisa ditebak, walau butuh waktu beberapa menit, tapi saat ini sangat sulit, apalagi perkembangan Large Language Model (LLM) seperti ChatGPT, dan sejenisnya.
Salah satu vendor penyedia model siap pakai adalah Hugging Face yang dapat kita akses, dan kita coba untuk gunakan pada postingan ini. Model ini mirip ChatGPT yang sudah berisi model terlatih sebelumnya. Nah jika ingin dimanfaatkan untuk memberi informasi ke pihak-pihak yang bertanya dapat kita latih ulang dengan data khusus organisasi atau produk/jasa yang dipasarkan. Jadi tidak perlu orang yang menjawab chat yang ditanya, cukup mesin saja. Video berikut contoh dengan Google Colab dengan kode dapat diakses di link berikut [Url]. Jika sudah silahkan aplikasikan ke Web yang berupa aplikasi Chat untuk tanya jawab terhadap konsumen.
Artificial Intelligence (AI) sangat luas, baik dari implementasi maupun definisi. AI terbagi jadi empat kuadran yakni Think Humanly, Think Rationally, Act Humanly, dan Act Rationally. Namun demikian definisi yang memuaskan sulit didapat, misalnya Alan Turing cenderung mendefinisikan AI sebagai Think Humanly, dengan Turing Test-nya dimana seseorang diminta menebak dia chatting dengan manusia atau mesin. Sementara itu tokoh lain seperti Elaine Rich menyatakan bahwa AI merupakan rancangan komputer yang melakukan sesuatu dimana saat ini manusia menunjukan hasil yang lebih baik. Misalnya aplikasi catur, ketika Grandmaster Gary Kasparov kalah oleh aplikasi catur Deep Blue, maka catur bisa dikatakan bukan wilayah AI lagi. Kalau bukan AI apa namanya? Alhasil, pertandingan catur harus mencegah pemain memanfaatkan AI. Misal ada robot yang mengendalikan motor dan mengalahkan Valentino Rossi, berarti robot pembalap itu sudah di luar AI.
Inilah yang dikhawatirkan oleh beberapa ilmuwan AI dimana produk dari AI yang mengalahkan manusia. Ketika ChatGPT muncul, ujian atau tugas mahasiswa sudah harus dipastikan tanpa memanfaatkan ChatGPT mengingat kemampuan aplikasi ini dalam men-generate tulisan atau menjawab soal-soal. Repotnya ketika AI yang telah dibuat belum ada cara mengantisipasi dampaknya.
Beragam produk AI dihasilkan setiap hari. Yang unik kebanyakan diakses tanpa perlu membayar, mirip Google yang gratis digunakan untuk searching, atau ChatGPT untuk menjawab pertanyaan-pertanyaan. Mengapa? Hal ini karena pengguna hanya diberi akses tanpa memiliki Engine AI itu sendiri. Ketika pengembang AI menciptakan engine, biasanya mereka tidak memberikan engine itu ke orang lain, melainkan hanya memberikan akses saja, misalnya dengan API. Video berikut memperlihatkan bagaiman mengimplementasikan AI lewat akses API dengan salah satu situs online untuk praktik DevOps, yakni Play-with-Docker.
Beberapa situs penyedia server gratis banyak tersedia, misalnya webhost [Link]. Sayangnya tidak bisa digunakan untuk AI berbasis python, hanya php dan sejenisnya (javascript). Beberapa bisa memiliki akses ke konsol untuk menginstal library python, namun ada kalanya diminta memasukan kartu kredit, walau gratis, ini cukup memberatkan.
Untungnya saat ini ada situs yang menyediakan deployment gratis berbasis python. Di sini kita bisa menjalankan AI yang berbasis Python dan diakses via website, namanya Streamlit Sharing [Link]. Urutan langkahnya adalah sebagai berikut:
1. Konversi aplikasi menjadi python (bukan ipynb).
2. Buat menjadi format Streamlit (dengan library streamlit). Tentu saja kita harus memasangnya dengan PIP biasa.
3. Mengupload aplikasi py dengan streamlit tersebut ke Github. Di sini fungsinya agar Streamlit menerima aplikasi python yang telah dibuat.
Untuk jelasnya dapat dilihat pada video youtube berikut ini. Sekian selamat mencoba dan mendeploy sendiri aplikasi python berbasis web dengan Streamlit.
Pengelola program studi pasti mengenal Penetapan, Pelaksanaan, Evaluasi, Pengendalian dan Peningkatan yang diisitlahkan dengan PPEPP. Ini merupakan siklus yang mengandalakan Sistem Penjaminan Mutu Internal (SPMI). Karena konsep, tentu saja sangat rumit bagi yang baru mengenalnya. Oke, jika Anda sudah mengenal metode backpropagation learning dalam machine learning, bisa kita pahami dengan menganalogikan PPEPP dengan proses learning tersebut.
Penetapan
Penetapan merupakan inti dari rencana meningkatkan mutu. Di sini berisi keputusan resmi berupa indikator yang akan dicapai. Dalam machine learning (ML) ibarat target output dari model yang akan dilatih.
Pelaksanaan
Ketika target disertai input yang menghasilkan target tersebut tersedia, maka proses pelatihan berjalan. Dalam pelaksanaannya, model diberi bobot dan bias tertentu, kemudian forward propagation berjalan. Di sini input tertentu diharapkan menghasilkan output sesuai dengan target. Output mengikuti kalkulasi input berdasarkan bobot dan bias yang diset.
Evaluasi
Dalam akreditasi, evaluasi berusahan mencari praktik baik, praktik buruk, dan praktik baru ketika proses pelaksanaan selesai. Nah, di sini jika output sesuai dengan target maka dikatakan praktik baik terjadi, begitu pula sebaliknya. Dalam proses learning, evaluasi ini menghasilkan error, misalnya dihitung dengan standar Mean Square Error (MSE).
Pengendalian
Tahap ini terjadi ketika diketahui adanya praktik buruk, maupun praktik baru yang belum jelas baik atau buruknya. Dalam ML berupa error. Nah, proses pengendalian bermaksud membuat rekomendasi dan revisi terhadap bobot dan bias pada model yang dilatih.
Peningkatan
Tahap ini berisi optimalisasi, yaitu bagaimana meningkatkan, menyesuaikan dan menyelaraskan output dengan targetnya, dalam kampus diistilahkan Indeks Kenerja Utama (IKU) yang berpatokan standar nasional DIKTI, dan Indeks Kinerja Tambahan (IKT) yang berdasarkan kampus yang ingin melebihi standar nasional DIKTI. Bisa jadi adanya perubahan target jika sulit tercapai, atau target yang tidak relevan.
Jadi jika PPEPP berjalan dengan baik, secara logika organisasi akan berkembang ke arah yang lebih baik. Nah, oleh karena itu target yang tepat perlu dibuat karena proses akan mengikuti target tersebut. Makin banyak iterasi yang dibutuhkan, tentu saja membutuhkan waktu dan biaya yang besar, jadi gunakan proses yang efisien dan efektif agar tidak perlu membutuhkan iterasi (dalam backpropagation diistilahkan dengan epoch) yang banyak. Semoga tulisan ini bisa memudahkan pemahaman terhadap PPEPP dalam akreditasi program studi.
Dari SD kita sudah belajar membaca, menulis, berhitung, dan lain-lain. Saat belajar biasanya dimulai dari yang sederhana kemudian lanjut ke yang sulit. Hal tersebut wajar, karena jika langsung sulit dipastikan siswa akan ‘down’.
Waktu terus berjalan, teknologi berkembang, hingga munculah Artificial Intelligence (AI) yang memanjakan siswa. Waktu ada kalkulator pun guru sudah cemas dan khawatir, siswa kurang teliti dalam berhitung, apalagi jika ada AI?
Ternyata kalkulator, komputer, dan aplikasi-aplikasi vertikal (SPSS, rapidminer, dll) tidak membuat mahasiswa kurang kompeten. Alat-alat tersebut ternyata bisa juga dimanfaatkan untuk alat bantu memahami ilmu yang akan dipelajari. Sebagai contoh untuk yang belajar jaringan syaraf tiruan (JST) dalam memahami fenomena dapat menggunakan ChatGPT dan alat simulator lain (misalnya MATLAB).
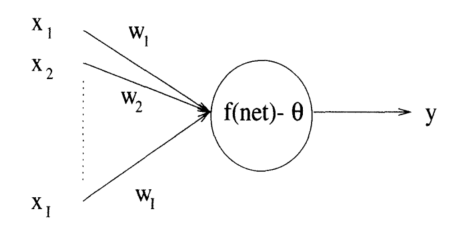
Salah satu buku yang menurut saya menarik adalah buku karangan Englebrecht dalam membahas JST. Dia menerangkan konsep network dimulai dari satu neuron terlebih dahulu, umpan maju dan mekanisme learning. Dengan 1 neuron penjelasan lebih sederhana.
Beragam jenis JST diturunkan dari model di atas, yang diperkenalkan pertama kali oleh Pitt. Untuk jalur balik backpropagation dengan beragam learning rule sangat mudah dipelajari (SGD, Widrow-hoff, delta rule, dll).
Nah, dengan AI kita bisa dengan mudah mengimplementasikan model matematik tersebut untuk network dengan 1 neuron.
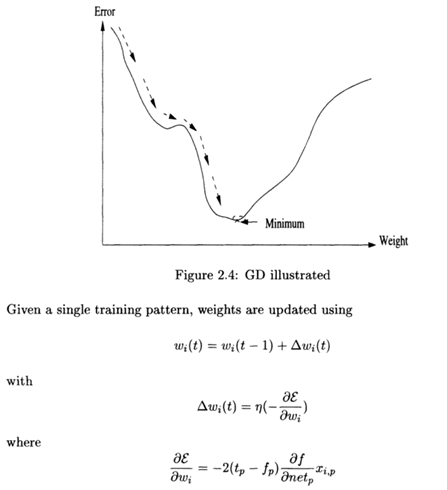
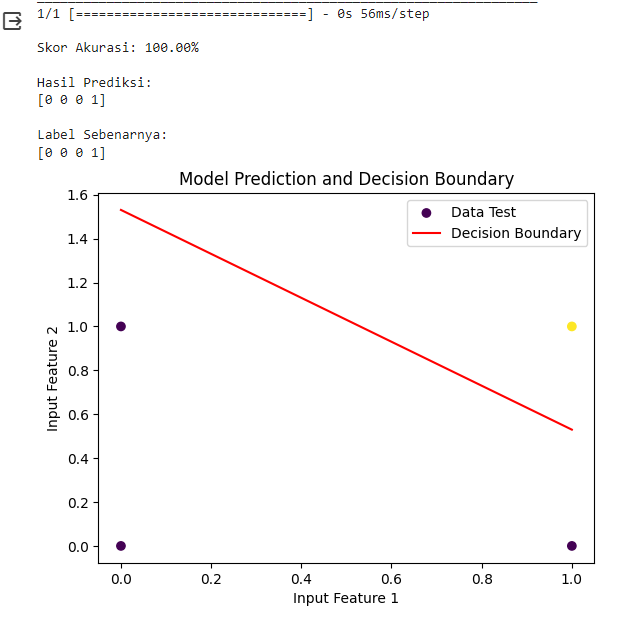
Perhatikan bagaimana Delta Rule melakukan perubahan bobot dan bias dibanding SGD dimana yang satu menggunakan error, SGD dengan gradien yang diambil dari derivatif/turunan sinyal output. Juga pada bagian bias-nya. Termasuk dengan chatGPT bisa juga langsung menanyakan grafik boundary, dengan Google Colab. Ini contoh untuk kasus penyelesaian logika AND, nah silahkan coba kasus lainnya. Di sini ternyata untuk logika XOR tidak bisa dengan 1 neuron.
Konon kabarnya kemenangan Donald Trump dibantu oleh intelligence media analytic yang mengandalkan pengaruh media sosial, salah satunya facebook [link]. Nah, kita akan memasuki pilpres dan pileg tahun depan, ada waktu sekitar 3 bulan untuk kampanye. Apakah waktu tersebut cukup?
Melihat kondisi geografis Indonesia yang tersebar dalam pulau-pulau, sangat sulit jika kampanye dilakukan dengan cara off line, turun ke lapangan. Dengan jumlah provinsi sebanyak 34 provinsi, tidak efektif hanya mengandalkan kunjungan langsung. Maka cara yang efektif tentu saja lewat media online.
Peran media analytic jadi sangat penting, selain untuk menebarkan kampanye positif (tentu saja kampanya negatif tidak etis). Beberapa mahasiswa sudah bisa membuat sentiment analysis dari twitter yang memang berbasis text. Nah, bagaimana dengan yang video? Tentu saja butuh sedikit usaha untuk mengkonversi ucapan menjadi tulisan, seperti video berikut:
Ketika video berhasil dikonversi menjadi tulisan, maka di sini Natural Language Processing (NLP) bekerja dengan memanfaatkan metode-metode yang ada, misal SVM, Naïve Bayes, BERT, dan sejenisnya, termasuk fasilitas khusus untuk bahasa selain Inggris, misalnya bahasa Indonesia. Berikut bagaimana menganalisa video menjadi sentiment analysis dan fasilitas lain seperti wordcloud.
Istilah Big Data muncul bersamaan dengan perkembangan hardware dan software, termasuk media sosial seperti facebook, twitter, tiktok, instagram, dan sebagainya. Secara sederhana, Big Data dengan konsep volume, velocity, veracity, dan variety, merupakan kumpulan data yang tidak mudah disimpan dalam penyimpanan konvensional [link]. Untuk mengolahnya butuh piranti yang kuat (super computer), dan beberapa software seperti Matlab memperkenalkan konsep pemrosesan Tall Array [link], dimana untuk uji coba digunakan data sederhana, setelah ok baru data yang besar agar ketika testing tidak memberatkan kinerja komputer.
Sebenarnya konsep big data adalah data yang buruk lebih baik dari pada tidak ada data. Namun, jika kurang pandai mengelola data dapat dipastikan hasil kurang relevan, tidak akurat atau tidak bermakna. Jadi Big Data memerlukan satu komponen lain yaitu Algoritma, dimana saat ini penerapannya disertai dengan Artificial Intelligence. Dengan algoritma yang tepat disertai pemrosesan paralel, pengolahan Big Data jadi lebih mudah dan cepat.
Bagaimana dengan “brainware”? Dalam hal ini adalah manusia. Berbeda dengan komputer yang bisa dijalankan secara paralel, kita sebagai manusia ternyata tidak sanggup paralel. Istilah multitasking sebenarnya bukan bersamaan secara paralel melainkan berganti-ganti secara cepat. Repotnya, tiap berganti memerlukan delay yang secara total mengurangi performa. Bahkan ada psikolog yang meneliti ketika mengerjakan suatu tugas psikis, jika sering diinterupsi, kerap terjadi error/kesalahan. Peneliti lain menghasilkan informasi adanya penambahan waktu sekitar 30% jika dua aktivitas dilakukan secara bersamaan dibanding secara serial satu kali finish dilanjutkan dengan aktivitas kedua hingga finish juga [link]. Namun untuk tugas tertentu seperti petugas McD yang menerima pesan sekalian melakukan pembayaran lebih menguntungkan dengan orang yang sama mengingat penambahan waktu 30% tapi menurunkan membayar petugas yang terpisah.
Untuk melatih the power of one sederhana, kerjakan satu aktivitas satu saja, hilangkan gangguan seperti notifikasi, berita yang tiba-tiba muncul di browser, youtube kesukaan, dan sejenisnya. Kemampuan untuk ‘bersikap bodo amat’ terkadang perlu [link], maksudnya adalah menyingkirkan yang tidak penting. Sehingga kemampuan ‘mengupas’ hal-hal yang tidak perlu hingga yang tinggal adalah hal yang perlu dikerjakan, dijamin tugas akan selesai. Prinsip the power of one ini merupakan awal dari prinsip ‘do less and obsess’ konsep yang mendorong seseorang untuk fokus pada hal-hal yang benar-benar penting dan mendalam daripada mencoba melakukan terlalu banyak hal dengan sekali waktu.
Orang pun senang dengan the ‘power of one’. Manakah yang lebih Anda sukai, berdialog dengan orang yang kerap membaca notif dari HP dengan orang yang fokus mendengarkan dan merespon pembicaraan dengan Anda. Sekian, semoga bermanfaat.