Bahasa pemrograman merupakan bahasa juga karena ketika dibuat memanfaatkan kombinasi antara bahasa manusia dan bahasa mesin. Ada satu mata kuliah di ilmu komputer, namanya teknik kompilasi. Sempat mengajar mata kuliah ini dengan memanfaatkan software lex and yacc. Aplikasi ini bisa membuat syntax bahasa baru, misalnya mengganti if – else menjadi jika – maka dengan memanfaatkan reguler expression di bahasa c++.
Di manakah keunikannya? Tentu saja mahasiswa bisa melihat bahwa bahasa pemrograman yang kita lihat sehari-hari merupakan buatan manusia yang tidak perlu diagung-agungkan. Dahsyat memang bisa membuat bahasa sendiri, atau minimal untuk lingkungan sendiri yang bikin hacker ‘bingung’ karena syntax-nya lain dari yang lain.
Kembali ke bahasa Prolog, bahasa ini mirip CLIPS yang dipakai untuk belajar Sistem Pakar (expert system) yang biasa juga digunakan untuk belajar Artificial Intelligence (AI). Untuk belajar cepat, saat ini cukup dengan bertanya ke ChatGPT maka dengan cepat kita bisa mencoba bahasa pemrograman legendaris ini. Silahkan gunakan aplikasi online yang tidak memerlukan instalasi di laptop kita [Url]. Istilah-istilah entailed di buku AI, misalnya karangan Russel bisa diimplementasikan di sini. Selamat mencoba.
Dulu saya pernah menggunakan Matlab dengan paralel prosesing (pos yang lalu). Caranya dengan menjalankan serempak aplikasi Matlab beberapa kali. Tetapi saat ini, Matlab terbaru menyediakan fasilitas Big Data.
Salah satu fasilitasnya adalah dengan menyediakan ‘workers’, yaitu proses terpisah, istilah lain dari processor. Selain itu disediakan pula sejenis matriks tetapi hanya sebagian yang ditampilkan, dikenal dengan nama ‘Tall Array’. Fasilitas ini memungkinkan pemodel merakit model tanpa khawatir berat akibat menguji dengan seluruh data. Dengan Tall array tidak seluruh data dirunning, hanya beberapa saja, yang penting jalan. Jika model yang dirakit sudah ok dijalankan dengan Tall Array, maka untuk menjalankan total data dengan instruksi ‘gather’. Silahkan baca lagi postingan tersebut untuk detilnya.
Untuk mengeksekusi Big Data dan Deep Learning, ada baiknya anda menggunakan laptop/komputer dengan GPU dengan compute ability di atas 5. Khusus Windows, silahkan diset GPU agar idle time diperpanjang, mengingat Windows ketika melihat GPU ‘nganggur’/idle, akan direset, padahal tidak idle, melainkan sedang mengeksekusi program. Silahkan lihat cara mengeset di sini.
Untuk mengetahui bagaimana menggunakan Matlab untuk aplikasi Big Data, silahkan lihat video berikut ini. Sekian selamat mencoba.
Lanjutan dari pos sebelumnya, kali ini membahas praktik sederhana menjalankan hasil pemodelan Machine Learning (ML) dengan Python pada PHP. Sebenarnya Python memiliki framework Web sendiri, misalnya Flask dan Django. Namun, kebanyakan server menggunakan Apache yang berbasis PHP. Oleh karena itu perlu mengintegrasikan Python dengan Apache. Silahkan lihat tatacara untuk XAMPP di windows pada video berikut.
Untuk Linux, misal Ubuntu agak sedikit rumit karena hak akses pada file, serta environment yang agak rumit, seperti video berikut.
Video berikut menjelaskan sample deployment sentiment analysis dengan bahasa Python pada PHP-MySQL di windows.
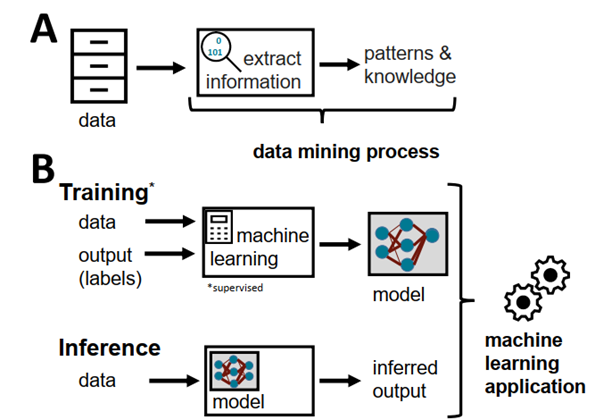
So far, we are familiar with both waterfall-based and iteration-based development cycles. The rapid development of Artificial Intelligence (AI) and Machine Learning (ML) makes it quite difficult for vendors to follow the development methods used because AI, DM, and ML involve datasets. So the data and methods in ML cannot be separated.
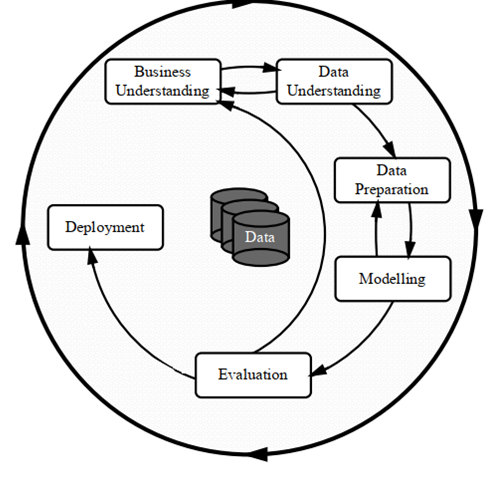
One of the development processes currently used is the Cross Industry Standard Process for Data Mining (CRISP-DM). This process integrates DM modeling into the development process. Especially in the data understanding to evaluation section.
After CRISP-DM was used to create Data Mining-based applications, some developers needed a new process standard specifically for ML, especially due to the rapid development of Deep Learning. So that raises CRISP-ML where ML is slightly different from DM. An integration with quality assurance (QA) results in the CRISP-ML(Q) development model.
In accordance with its meaning, ML requires a learning process before inference, which is usually unsupervised. For more details, please see the following video.
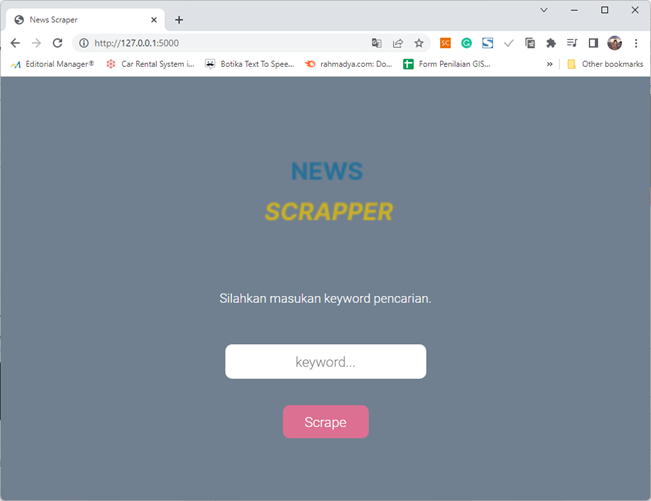
There are two terms in web searching, namely Web Crawling and Web Scraping. The two terms have a difference. If Web Crawling looks for the location/address of the site, Web Scrapping retrieves the content or site content.
Google for example, when searching, this engine will crawl sites around the world based on keywords. Next the user will get a list of sites suggested by Google based on their ranking. Furthermore, the content will be searched manually by the user from sites suggested by Google or other search engines. The combination of crawling and scraping results in a system that in addition to finding the location of sites based on keywords, also retrieves the content of these sites.
The following video is an example of how a simple application scrapes information from four sample sites based on keywords and then the results are stored in csv (Jurnal link). Stored results can be further utilized, for example for sentiment analysis (Jurnal link).
Tahun 2014 saya masih menjadi mahasiswa doktoral Information Management. Ada satu mata kuliah: Decision Support Technologies yang berisi bagaimana sistem informasi membantu pengambil keputusan, salah satunya dengan pemanfaatan Big Data.
Waktu itu saya satu grup dengan mhs dari Thailand dan Uzbekistan. Tugasnya cukup menarik, yaitu menggunakan data dari Kagel yang berisi jutaan record penulis artikel ilmiah yang masih kasar (raw). Targetnya adalah mengumpulkan penulis yang berserakan menjadi rapih, dimana tidak ada redundansi penulis. Terkadang ada nama penulis yang terbalik susunannya, tanpa nama tengah, dan lain-lain. Selain itu perlu deteksi untuk afiliasi dan bidang ilmunya. Yang tersulit adalah terkadang nama belakang perempuan yang mengikuti nama suami.
Kendala utamanya adalah data yang berukuran besar baik dari sisi kapasitas maupun jumlah record. Ketika dibuka dengan Excel, tidak seluruhnya terambil karena ada batas record Microsoft Excel yakni sebanyak 1,048,576 record dan 16,384 kolom. Terpaksa menggunakan sistem basis data, yang termudah adalah Microsoft Access. Waktu itu fasilitas Big Data pada Matlab masih minim, terpaksa ketika menjalankan pemrosesan paralel, secara bersamaan dibuka 3 Matlab sekaligus (lihat postingan saya tahun 2014 yang lalu).
Tipe Data Tall
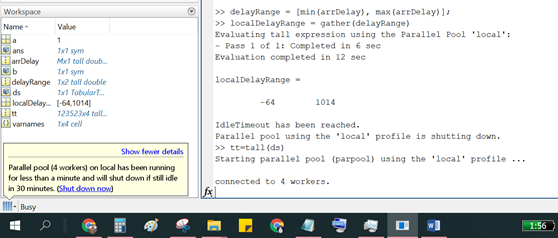
Sekitar tahun 2016-an Matlab memperkenalkan tipe data Tall dalam menangani data berukuran besar. Prinsipnya adalah proses upload ke memory yang tidak langsung. Sebab kalau ketika impor data dengan cara langsung maka akibatnya memory akan habis, biasanya muncul pesan ‘out of memory‘. Oleh karena itu Matlab membolehkan mengupload dengan cara ‘mencicil’. Tentu saja untuk memperoleh hasil proses yang lengkap dengan bantuan fungsi gather.
Seperti biasa, cara mudah mempelajari Matlab adalah lewat fasilitas help-nya yang lengkap, maklum software ‘berbayar’. Lisensinya saat ini sekitar 34 jutaan, kalau hanya setahun sekitar 13 juta dan kurang dari 1 juta untuk pelajar. Pertama-tama ketik saja di Command Window: help tall. Pastikan muncul, jika tidak muncul, berarti Matlab Anda belum support fungsi Big Data tersebut. Walau mahal, tetapi Anda bisa mencoba sebulan secara gratis. Ok, jalankan saja help yang muncul.
Dengan fungsi datastore, pertama-tama sampel Big Data disiapkan. Di sini masih menggunakan Comma Separated Value (CSV). Perhatikan hasil proses fungsi tall yang berupa matriks berukuran Mx4. Nah, disini istilah M muncul yang berarti ‘beberapa’, karena yang ditarik belum seluruhnya.
Tampak paralel pool sudah terbentuk, dengan 4 worker. Di sini dibatasi 30 menit, jika idle/tidak digunakan akan di-shutdown. Terakhir, fungsi gather dibutuhkan untuk merekapitulasi hasil olah.
Tampak informasi pooling yang merupakan ciri khas pemrosesan paralel telah selesai dilakukan. Sekian, semoga informasi ini bermanfaat.
Pada postingan yang lalu telah dibahas klasterisasi dengan KMeans menggunakan bahasa Matlab. Kali ini kita coba menggunakan bahasa Python dengan GUI Jupyter notebook pada Google (Google Colab).
Sebelumnya kita siapkan terlebih dahulu file data sebagai berikut. Kemudian buka Google Colab untuk mengklasterisasi file tersebut. Sebagai referensi, silahkan kunjungi situs ini. Saat ini kita dengan mudah memperoleh contoh kode program dengan metode tertentu lewat google dengan kata kunci: colab <metode>.
Mengimpor Library
Library utama adalah Sklearn dengan alat bantu Pandas untuk pengelolaan ekspor dan impor file serta matplotlib untuk pembuatan grafik.
from sklearn.cluster import KMeans
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
from matplotlib import pyplot as plt
Perhatikan di sini KMeans harus ditulis dengan K dan M berhuruf besar, begitu pula kelas-kelas yang lain seperti MinMaxScaler
Menarik Data
Perhatikan data harus diletakan di bagian file agar bisa ditarik lewat instruksi di bawah ini. Jika tidak maka akan muncul pesan error dimana data ‘beasiswa.csv’ tidak ada.
Selain itu tambahkan instruksi untuk mengeplot data. Tentu saja ini khusus data yang kurang dari 3 dimensi. Jika lebih maka cukup instruksi di atas saj.
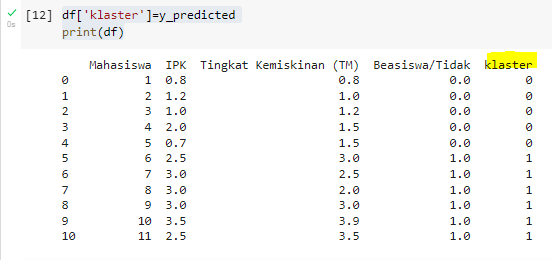
Nah, hal terpenting adalah tidak hanya menghitung y_predicted saja melainkan melabel kembali datanya. Percuma saja jika kita tidak mampu memetakan kembali siapa saja yang masuk kategori klaster ‘0’ dan ‘1’.
df[‘klaster’]=y_predicted
print(df)
Finishing
Di sini langkah terpenting lainnya adalah kembali memvisualisasikan dalam bentuk grafik dan menyimpan hasilnya dalam format CSV.
Hasilnya adalah grafik dengan pola warna yang berbeda tiap klaster-nya.
Salah satu kelebihan Pandas adalah dalam ekspor dan impor data. Dalam hal ini kita akan menyimpan hasil klasterisasi dengan nama ‘klasterisasi.csv’. Lihat panduan lengkapnya di sini.
df.to_csv(‘klasterisasi.csv’)
Silahkan file hasil sempan diunduh karena Google Colab hanya menyimpan file tersebut sementara, kecuali kalau Anda menggunakan Google Drive (lihat caranya). Untuk mengujinya kita buat satu sel baru dan coba panggil kembali file ‘klasterisasi.csv’ yang baru terbentuk itu. df=pd.read_csv(‘klasterisasi.csv’)
df.head()
Note: ada field yang belum dinamai (Unnamed), bantu ya di kolom komentar caranya. Oiya, MinMaxScaler digunakan untuk jika data ‘jomplang’ misalnya satu dimensi, IPK dari 0 sampai 4 sementara misalnya penghasilan jutaan, tentu saja KMeans ‘pusing’. Oleh karena itu perlu dilakukan proses preprocessing. Sekian, semoga bermanfaat.
Decision Tree (DT) merupakan metode machine learning klasik yang memiliki keunggulan dari sisi interpretasi dibanding Deep Learning (DL). Memang akurasi Deep Learning, terutama yang digunakan untuk mengolah citra sudah hampir 100% tetapi beberapa domain, misalnya kesehatan membutuhkan model yang dapat dilihat “isi” di dalamnya. Kita tahu bahwa DL sering dikatakan “black box” karena tidak dapat diketahui alur di dalamnya. Nah, di sinilah DT digunakan karena memiliki keunggulan dari sisi transparansi. Bahkan ketika DT terbentuk kita bisa memprediksi secara manual hasil akhir dengan melihat alur DT tersebut tanpa bantuan komputer. Silahkan lihat pos saya terdahulu tentang DT.
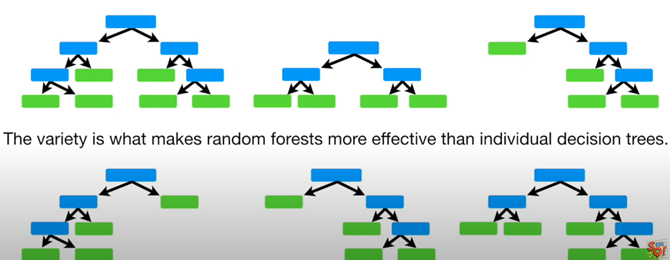
Nah, karena data yang besar terkadang DT sangat sulit terbentuk. Seorang peneliti dari IBM bernama Tin Kam Ho membuat algoritma DT di tahun 1995 (saya baru masuk S1 FT UGM waktu itu). Prinsipnya adalah membuat DT-DT kecil secara acak kemudian digunakan untuk memprediksi melalui mekanisme voting. Misalnya kita ingin memprediksi sesuatu dengan enam buah Trees di bawah ini.
Jika hasilnya 2 Yes dan 4 No maka secara voting hasil prediksinya adalah No karena yang terbanyak No. Oiya, Tree yang dibentuk di atas ketika memilih root dan node tidak perlu menggunakan kalkulasi njlimet seperti DT yaitu dengan Entropi dan Gain Information.
Bagaimana menerapkan lewat bahasa pemrograman? Python memiliki library Scikit Learning untuk Random Forests. Oiya, jika ingin melihat kode di dalam library tersebut silahkan buka saja Source di Github yang disediakan oleh Scikit Learning. Jika ingin memodif silahkan tiru-amati-modifikasi source code tersebut, khususnya para mahasiswa doktoral yang fokus ke metode. Untuk lebih jelasnya silahkan lihat link Video saya di Youtube berikut ini. Sekian, semoga bermanfaat.
Support Vector Regression (SVR) merupakan metode klasik yang memanfaatkan teori matematika dan statistik untuk regresi dengan model Support Vector Machine (SVM). Jadi SVM ternyata bukan hanya untuk klasifikasi melainkan juga untuk regresi dan deteksi outliers.
Silahkan gunakan Scikit Learning untuk bahasa Python. Postingan ini mengilustrasikan penggunaannya dengan Google Colab. Data COVID dapat kita temukan di internet, atau silahkan gunakan file Excel link ini. Pilih negara yang ingin Anda prediksi kemudian simpan dalam bentuk file. Berikut kira-kira kode programnya.
#impor pustaka svm import pandas as pd import numpy as np import matplotlib.pyplot as plt from sklearn.svm import SVR from google.colab import files import io #data latih upload_files = files.upload() for filename in upload_files.keys():
x=upload_files[filename].decode(‘utf-8’)
data1 = pd.read_csv(io.StringIO(x), header=None) #print(data1.head()) X1=np.asarray(data1)
x_train=X1[0:,0:1]
y_train=X1[0:,1:2] #membuat model (classifier) clf = SVR(kernel=‘poly’, C=100, gamma=‘auto’, degree=2, epsilon=.1,
oef0=1)
clf.fit(x_train,y_train) #prediksi data test=x_train.reshape(-1,1)
y_pred=clf.predict(test)
y_next=np.array([[457],[465],[470],[471],[480]])
prednext=clf.predict(y_next) print(prednext) #Visualisasi Data absis=[x_train]
ordinat=[y_train] #ordinat2=np.concatenate([x_train],[prednext]) plt.scatter(absis, ordinat, cmap=‘flag’, marker=‘o’)
plt.scatter(absis, y_pred, cmap=‘flag’, marker=‘x’)
plt.scatter(y_next, prednext, cmap=‘flag’, marker=‘x’) #Label plt.xlabel(“Day”)
plt.ylabel(“Number of infected People”)
plt.title(“Projection Pattern of COVID-19 Spread in India”)
plt.grid()
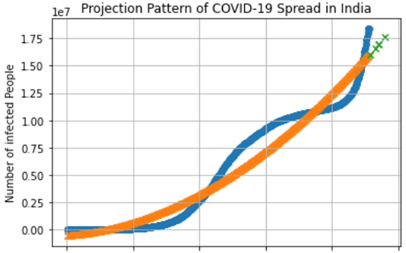
Jika dijalankan, masukan saja data CSV yang Anda ingin prediksi dan tunggu beberapa saat, agak lama karena 400-an hari (lebih dari setahun). Jika selesai pastikan hasil prediksi muncul.
Tampak garis biru merupakan data asli dari Excel sementara garis oranye merupakan hasil fitting berdasarkan kernel polinomial (kuadratik). Lima tanggal prediksi tampak di ujung kanan berwarna hijau. Silahkan lihat video lengkapnya di chanel saya. Sekian, semoga bisa menginspirasi.
Saat ini tidak dapat dipungkiri bahwa Deep Learning paling banyak diteliti dan digunakan dalam aplikasi-aplikasi artificial intelligence. Beberapa pengguna tidak menyukai metode tersebut karena karakteristiknya yang tidak dapat dilihat logika di dalam modelnya atau sering diistilahkan dengan black box walaupun akurasinya saat ini dengan model terbarunya hingga mendekati 100%. Selain itu, deep learning membutuhkan kinerja prosesor yang tinggi, terutama ketika proses pelatihan (learning).
Jika ingin membuat model yang dapat dilihat alur logikanya, naïve bayes merupakan salah satu pilihan yang baik. Walaupun kinerjanya menurut beberapa penelitian kalah dengan metode terkini seperti misalnya support vector machine (SVM), metode ini memiliki karakteristik statistik yang kental, yaitu probabilistik. Ada istilah confidence dalam metode ini.
Untuk perhitungan, naïve bayes lebih mudah menurut saya dibanding decision tree yang mengharuskan membuat model tree dengan konsep entropy dan gain informationnya. Pada naïve bayes, kita hanya menghitung probabilitas ketika menghitung confidence tiap-tiap kelas prediksi.
Plus Minus
Metode naïve bayes, dalam Scikit Learn diisitilahkan dengan Gaussian Naïve Bayes, karena dalam mengkonversi tabel kategorikal lewat pendekatan fungsi Gauss. Walaupun akurasinya kurang dibanding metode lain, sifat probabilistiknya sangat membantu penjelasan ke pengguna dalam aplikasinya. Misalnya dalam memprediksi sebuah sentimen dalam sentiment analysis, metode ini tidak hanya menjelaskan positif, negatif, atau netral saja, melainkan berapa kadar positif dan negatifnya dalam bentuk probabilitas. Terkadang jika dalam sistem dashboard menunjukan negatif dengan probabilitas yang tinggi bisa saja digambarkan dengan warna merah yang artinya warning, sehingga eksekutif segera mengambil tindakan yang perlu dalam manajemen.
Statistik merupakan bidang yang paling banyak dimanfaatkan dalam machine learning. Belakangan beberapa ahli machine learning enggan disebut ahli statistik karena belakangan metode-metode terbaru tidak terlalu mengadopsi konsep statistik, misalnya tensorflow yang cenderung ke arah tensor dan matriks dalam aljabar. Silahkan lihat penjelasan slide di atas dalam video youtube berikut ini, semoga bermanfaat.
Pohon keputusan merupakan satu metode klasik dalam prediksi/klasifikasi. Tekniknya adalah dengan menggunakan pertanyaan di suatu atribut (disebut test attribute) kemudian mengarahkan ke cabang mana sesuai dengan jawabannya. Tugas utama dalam metode ini adalah model membuat pohon/tree berdasarkan informasi dari data yang menjadi rujukan.
Perhitungan Manual
Pada slide di bawah, perhitungan manual dijelaskan yang diambil dari buku Data Mining karya Han and Kamber.
Beberapa kesalahan hitung terjadi ketika menghitung expected information dan entropi di tiap-tiap fitur/atribut. Untuk yang sedang mengambil kuliah ini ada baiknya berlatih soal-soal agar ketika ujian tidak terjadi salah hitung.
Perhitungan dengan Program
Berikutnya disertakan pula bagaimana mengimplementasikannya dengan Python, dalam hal ini menggunakan Google Colab. Saran untuk mahasiswa S1 dan D3 ada baiknya mengetik langsung kode (tanpa copas) agar bisa melatih skill/keterampilan. Sekaligus juga debug ketika ada error terjadi. Silahkan lihat video lengkapnya di youtube berikut ini. Semoga bermanfaat.
Algoritma Genetika (GA) merupakan salah satu nature-inspired optimization yang meniru evolusi makhluk hidup. Gampangnya, generasi terkini merupakan generasi yang terbaik yang adaptif terhadap lingkungan. Prinsip seleksi, kawin silang, dan mutasi diterapkan ketika proses optimasi secara pemilihan acak (random) dilakukan. Karena adanya unsur pemilihan acak, GA masuk dalam kategori metaheuristik bersama particle swarm optimization (PSO), simulated annealing (SA), tabu search (TS), dan lain-lain.
Bagaimana algoritma tersebut bekerja dalam suatu bahasa pemrograman saat ini dengan mudah kita jumpai di internet, dari youtube, blog, hingga e-learning gratis. Saat ini modul-modul atau library dapat dijumpai, misalnya di Matlab. Nah, dalam postingan ini kita akan mencoba dengan bahasa pemrograman Python. Sebelumnya perlu sedikit pengertian antara pembuatan program dari awal dengan pemrograman lewat bantuan sebuah modul atau library.
Beberapa pengajar biasanya melarang mahasiswa untuk langsung menggunakan library karena memang peserta didik harus memahami konsep dasarnya terlebih dahulu. Untungnya beberapa situs menyediakan kode program jenis ini yang dishare misalnya ahmedfgad, datascienceplus, pythonheatlhcare, dan lain-lain. Saya dulu menggunakan Matlab, dan ketika beralih ke Python karena pernah dengan bahasa lain maka dengan mudah mengikuti kode dengan bahasa lainnya. Oiya, saat ini GA, PSO, TS, dan lain-lain lebih sering disebut metode dibanding dengan algoritma karena tingkat kompleks dan ciri khas akibat mengikuti prinsip tertentu (makhluk hidup, fisika, biologi, dan lain-lain).
Selain memahami prinsip dasar, dengan kode python GA yang murni berisi langkah-langkah dari seleksi, kawin silang dan mutasi, jika Anda mengambil riset doktoral terkadang perlu menggabungkan dengan metode-metode lain, misalnya riset saya dulu, mutlak harus memodifikasi seluruh kode yang ada, jadi agak sulit jika menggunakan library yang tinggal diimpor.
Nah, jika Anda sudah memahami, dan sekedar menggunakan atau membandingkan metode satu dengan lainnya, penggunaan library jauh lebih praktis. Misal Anda menemukan metode baru dan harus membandingkan dengan metode lain, maka metode lain pembanding itu dapat digunakan, bahkan karena karakternya yang dishare maka orang lain (terutama reviewer jurnal) yakin keabsahannya (bisa dicek sendiri). Untuk GA bisa menggunakan library dari situs-situs berikut antara lain geneticalgorithms, pygad, pydea, dan lain-lain. Sebagai ilustrasi silahkan melihat video saya berikut yang menggunakan Google Colab.
Aplikasi web biasanya merupakan aplikasi bertipe front-end dimana antara user dengan machine saling berinteraksi. Sementara itu machine learning, bagian khusus dari data mining, kebanyakan bekerja sebagai back-end. Nah, agar machine learning terhubung dengan user, dibutuhkan user interface, salah satunya adalah aplikasi berbasis web. Python, sebagai bahasa yang memang dikhususkan untuk back-end menyediakan pula aplikasi front-end dalam bentuk web lewat beberapa framework-nya, salah satunya adalah Flask.
Menyisipkan Machine Learning
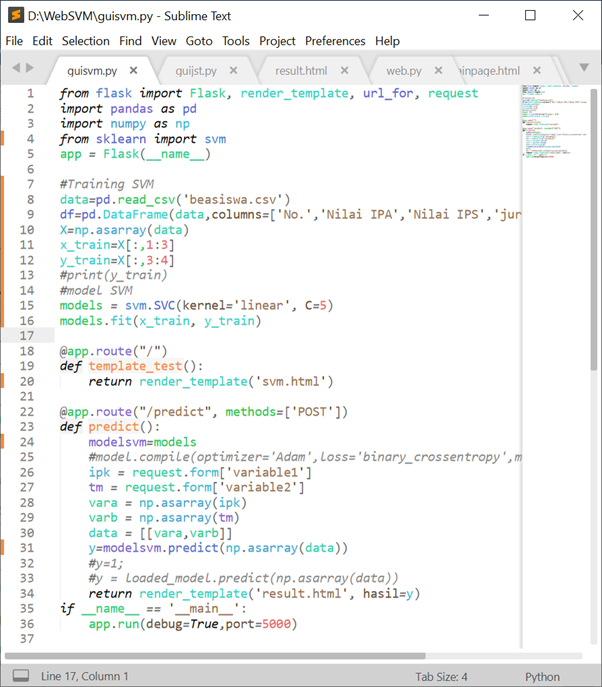
Bagaimana cara kerja Flask, silahkan lihat pos saya terdahulu. Beberapa library perlu dipersiapkan dari yang diperuntukan menjalankan machine learning (Pandas, NumPy, Keras, SKlearn, dan lain sebagainya) hingga yang memang khusus untuk Flask. Untuk studi kasus dipilih Support Vector Machine (SVM) untuk mengklasifikasi data penentuan beasiswa. Diperlukan tiga file program dengan satu file data. Tiga file tersebut antara lain satu file utama python dan dua file html untuk interface (main program untuk inputan dan result.html untuk keluaran). Berikut tampilan program utamanya.
Perhatikan letak training SVM setelah proses impor pustaka-pustaka yang dibutuhkan. Dua fungsi (template_test dan predict) dibutuhkan berturut-turut ketika program dieksekusi dan ketika tombol ditekan (via browser).
Testing
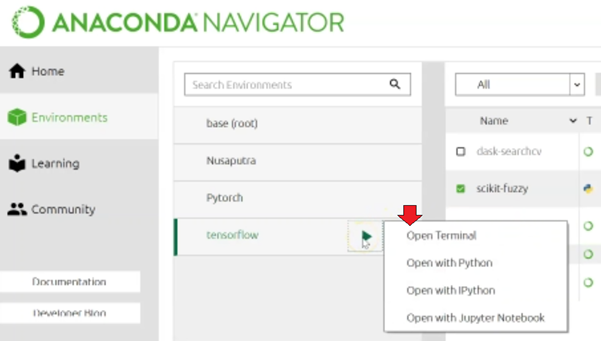
Untuk mengujinya, perlu memahami bagaimana konsep environment di python. Cara termudah adalah lewat Anaconda Navigator. Pastikan di environmen terpasang pustaka-pustaka yang dibutuhkan (bisa lewat PIP terminal ataupun lewat Anaconda). Buka environment yang tepat dengan menekan mouse di nama environmen tersebut dilanjutkan dengan mengklik kanan dan pilih “terminal” untuk membuka terminal yang mengarah ke environment tersebut. Environment ditunjukan dengan dalam kurung di terminal, misalnya kasus saya nama environmennya “tensorflow” (hanya nama saja).
Setelah masuk terminal arahkan folder ke lokasi program utama python-nya (berekstensi *.py). Untuk jelaskan silahkan buka video berikut ini. Sekian, semoga bermanfaat.
Untuk rekan-rekan mahasiswa yang sudah setia mengikuti perkuliahan (Univ. Islam 45, Univ. Nusa Putra, dan Univ. Bhayangkara Jakarta Raya) walaupun secara online di masa pandemic COVID-19, kami mengucapkan terima kasih sebesar-besarnya karena secara tidak langsung turut membantu terciptanya buku revisi “Data Mining” yang kini disertai bahasa Python yang Insya Allah sudah melewati revisi terakhir dan siap cetak.
Mungkin ada pembaca yang sudah mahir metode-metode yang digunakan untuk machine learning, tapi kesulitan ketika membuat aplikasi yang digunakan oleh pengguna. Banyak pilihan yang mungkin, apakah berbasis desktop ataukah web. Pilihan berupa mejalankan lewat konsol tentu saja menyulitkan pengguna yang biasanya eksekutif pengambil keputusan. Untuk yang berbasis desktop (lihat pos yang lalu tentang tkinter) menyulitkan jika ingin digunakan bersama. Nah, penggunaan aplikasi berbasis web untuk machine learning menjadi satu-satunya pilihan yang baik. Dengan aplikasi web, aplikasi dapat digunakan oleh divisi lain. Pos ini merupakan penjelasan lebih lanjut dari post yang lalu dengan penambahan pada operasi aritmatika sederhana (penjumlahan).
Bahasa Pemrograman Front-End dan Back-End
Dua pilihan framework web berbasis python yang terkenal adalah “django” dan “flask”. Jika django diperuntukan untuk aplikasi besar (enterprise), flask cocok jika digunakan internal di perusahaan karena karakteristiknya yang microframework. Toh biasanya memang aplikasi machine learning tidak “diumbar” ke luar, melainkan hanya kepentingan internal saja. Biasanya memang machine learning bekerja secara back-end, sementara bahasa pemrograman lain seperti java, php, dan bahasa front-end lainnya diperbantukan. Tetapi ternyata dengan framework-framework web, python secara mengejutkan dapat digunakan sebagai front-end juga.
Mempersiapkan Pustaka (Library) Flask
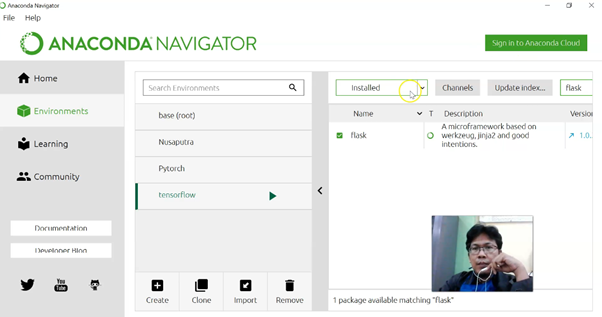
Langkah penting pertama adalah menyiapkan pustaka untuk menjalankan Flask. Kita dapat menggunakan dua metode yaitu lewat konsole (dengan PIP) dan lewat Anaconda Navigator. Silahkan atur environment yang tepat agar tidak salah menggunakan environment.
Di sini saya menginstal Flask di environment “tensorflow” (hanya nama saja). Untuk yang konsol, gunakan “path” yang sesuai, atau bisa menggunakan aplikasi “virtualenv”. Atau untuk pemula seperti saya, gunakan saja Anaconda yang terintegrasi.
Format Folder Flask
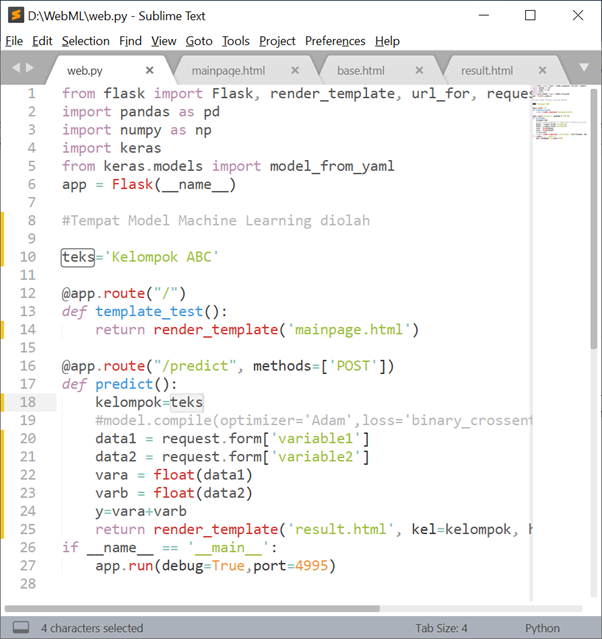
Flask membutuhkan satu file python untuk menghidupkan server dan beberapa templet HTML untuk input dan outputnya. Misalnya untuk contoh kita menggunakan satu file python “web.py” untuk menghidupkan server dan mengatur komunikasi templet lainnya: “mainpage.html” dan “result.html”.
Gunakan beragam text editor untuk mengetik dan membaca program-program tersebut, misalnya notepad, sublimetext, IDLE, dan text editor lainnya. Pastikan letak file mengikuti standar di atas dimana HTML terletak dalam satu folder “templates”. Berikut contoh kode untuk menghidupkan server Flask.
Memang perlu usaha keras untuk rekan-rekan yang kurang memahami format HTML dan CSS. Silahkan pelajari sumber-sumber belajar HTML dan CSS tersebut. Atau bisa gunakan Bootstrap yang tersedia dengan cuma-cuma di internet.
Menghidupkan Server
Dengan environment yang sesuai, masuk ke mode konsol dan ketik: python <namafile.py> di folder yang tepat. Pastikan server hidup dengan indikasi adanya instruksi untuk mengakses http://127.0.0.1:<port>.
Untuk keluar bisa menggunakan “Ctrl+C”. Ada kejadian unik ketika saya mengutak-atik kode tetapi tidak bisa dijalankan karena server masih menyimpan yang lama (cache). Setelah mengganti port baru bisa.
Testing
Buka browser dan jalankan aplikasi. Pastikan dapat berjalan dengan sempurna. Silahkan untuk jelasnya buka video tutorial saya di Youtube berikut ini.
Adaptive Neuro-Fuzzy Inference System (ANFIS) merupakan metode yang menggabungkan Jaringan Syaraf Tiruan (JST) dengan Fuzzy. Konsepnya adalah menjadikan “rule” sebagai “neuron”. Jumlah layer tersembunyi (hidden) hanya satu layer. Salah satu situs yang OK untuk mempraktikan ANFIS dengan bahasa pemrograman Python adalah salah satu TIM dari MIT di link berikut ini. Source code bisa diunduh dan penjelasannya lewat situs Github.
Instal Library ANFIS
Anaconda tidak memiliki pustaka ANFIS, oleh karena itu perlu mengunduh menggunakan PIP. Selain itu pustaka yang dibuat sendiri juga disertakan, misalnya anfis.py dan folder membership yang berisi dua file penting lainnya. Untuk mengetahui bagaimana fungsi eksternal bekerja silahkan lihat postingan saya yang lalu.
Menggunakan Google Colab
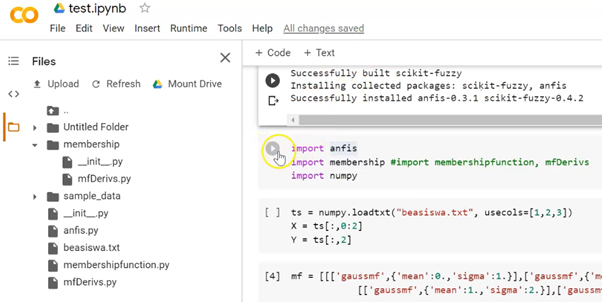
Memang lebih mudah menggunakan Google Colab karena sebagian besar pustaka sudah tersedia. Hanya saja untuk ANFIS terpaksa harus menginstal terlebih dahulu. Caranya adalah seperti instalasi PIP lewat terminal, hanya saja disini menggunakan tanda seru di awalnya.
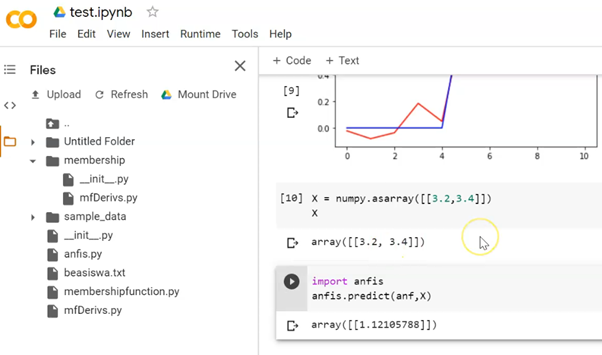
Ketik !pip install anfis. Tunggu beberapa saat hingga Google Colab berhasil mengunduh dan menginstal pustaka ANFIS tersebut. Jangan lupa, file-file pendukung unggah di bagian File di sisi kiri Google Colab. Pastikan ketika impor pustaka di sel berikutnya berhasil. Buat folder baru dengan nama membership lalu isi dengan file pendukungnya. Jangan diletakan di luar semua.
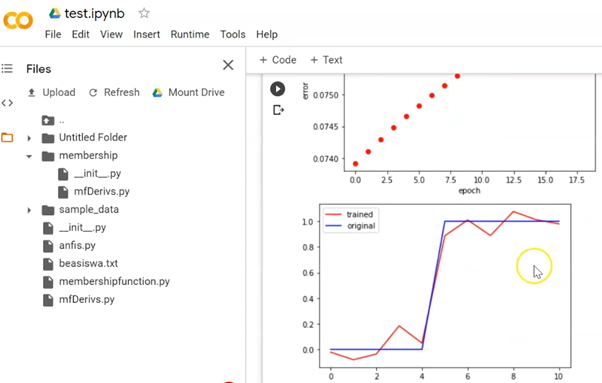
Berikutnya adalah mengambil data latih dari file “beasiswa.txt”. Pastikan X dan Y sesuai dengan yang diinginkan sebagai data latih dan targetnya. Silahkan cari sumber referensi mengenai membership function. Di sini mf berfungsi mem-fuzzy-kan inputan. Jalankan dan pastikan grafik performa pelatihan muncul.
Perhatikan hasil latih yang berwarna merah sudah mendekati target yang berwarna biru. Satu untuk memperoleh beasiswa dan nol untuk yang tidak memperoleh beasiswa. Gunakan satu data sampel untuk menguji apakah menerima beasiswa atau tidak.
Perhatikan untuk input1 3.2 dan input2 3.4 hasilnya adalah 1. Silahkan menggunakan fungsi “round” untuk membulatkan apakah nol atau satu. Untuk jelasnya lihat video berikut ini. Sekian semoga bermanfaat.