Oleh: Rahmadya Trias H., ST, MKom
Pohon keputusan (decision tree) merupakan salah satu teknik terkenal dalam data mining. Tugas paling umum yang diserahkan kepada pohon keputusan adalah klasifikasi. Dari set database kita bisa mengetahui apakah suatu nasabah merupakan nasabah yang baik atau tidak dari riwayatnya, seseorang berpeluang terkena suatu penyakit tertentu berdasarkan riwayatnya dan lain-lain.
Pohon keputusan merupakan teknik yang paling efisien. Ibaratnya, kita menyaring sesuatu lewat pohon keputusan, apakah suatu data lolos atau tidak terhadap saringan kita dengan proses yang cukup cepat. Teknik regresi sangat banyak, tetapi yang paling terkenal adalah algoritma yang diperkenalkan oleh Prof. Briemann dengan istilah The Classification and Regression Tree (CART).
10.1. Prinsip Dasar
Untuk lebih mempercepat pemahaman tentang pohon keputusan, ada baiknya kita mengambil contoh kasus data “college plan” yang meriset beberapa orang yang akan mengambil kuliah berdasarkan IQ, Paksaan Orang Tua, Ekonomi dan Gender. Sasarannya adalah kita mampu membuat pohon keputusan, apakah seseorang kemungkinan besar mengambil kuliah atau tidak berdasarkan IQ, Paksaan Orang Tua, Ekonomi dan Gender.
Masalah pertama pada pembuatan pohon keputusan adalah, variabel manakah yang menjadi akar dari pohon tersebut. Akar di sini adalah pemisah pertama dari pohon keputusan. Dikenal istilah Bayesian Score yang menilai suatu variabel, atau dalam Pohon Keputusan terkenal dengan sebutan Entropi. Entropi dihitung dengan rumusan sebagai berikut:

Akar dipilih berdasarkan nilai entropi terendah, dan berdasarkan hasil hitungan ternyata entropi terendah adalah Paksaan Orang tua. Jadi penentu pertama peluang tertinggi seseorang mengambil kuliah berdasarkan database tersebut adalah paksaan orang tua.
10.2. Penggunaan MS BI Development
Langkah pembuatan dengan Microsoft Business Intelligent Development sama dengan bab IX tentang Naive Bayes. Bedanya adalah pada saat menentukan Mining Technique, kita memilik “Microsoft Decision Tree”. Pilih ID sebagai Key, kemudian pilih semua variabel sebagai input, prediksi kita pilih “College Play” yang berisi data “yes” atau “no”.
Coba Sendiri !!!

Gambar 10.1. Hasil Mining


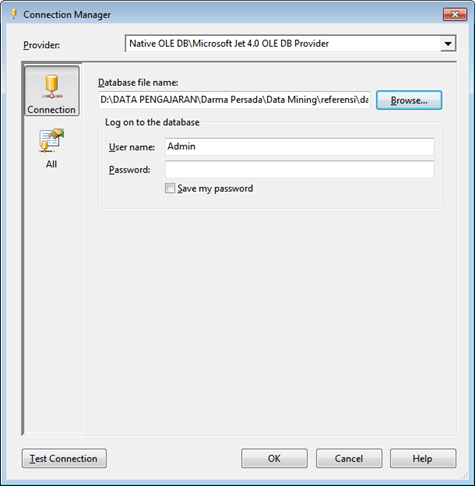

 “Process Mining …” untuk memproses Data Mining. Klik “Yes” dilanjutkan dengan proses Mining. Tunggu hingga selesai.
“Process Mining …” untuk memproses Data Mining. Klik “Yes” dilanjutkan dengan proses Mining. Tunggu hingga selesai.
