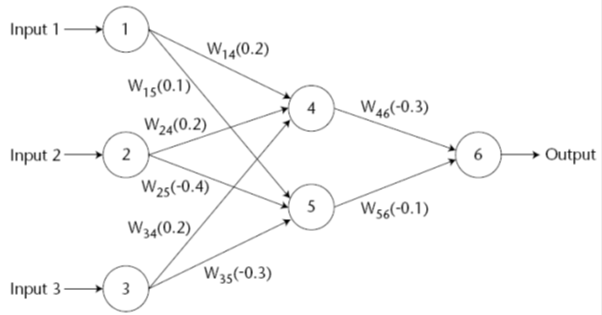
Oleh : Rahmadya Trias H., ST, MKom.
Online Analytical Processing (OLAP) pertama kali dikemukakan oleh E.F. Codd pada tahun 1994. Banyak kegunaannya terutama untuk Sistem Pengambil Keputusan (Decision Support System) yang melibatkan multiple database.
OLAP saat ini hampir pasti digunakan untuk sistem berbasis Business Intelligent (BI) bersama dengan data mining. Terdiri dari Tabel Fakta (Fact Table) dengan beberapa dimensi (dimensions) dengan bentuk hierarchy. Sasarannya adalah bagaimana menemukan informasi yang berguna dari suatu cube.
13.1. Pengenalan OLAP
Online Transaction Processing (OLTP) ditujukan untuk merekam transaksi harian, misalnya transaksi penjualan, pembelian dan perbankan. OLTP tidak memiliki perangkat yang cukup untuk menganalisa, oleh karena itu diperlukan sistem OLAP yang digunakan dalam sistem DSS.
Cube adalah database dengan dimensi banyak (multidimensions) dengan bentuk hirarkinya. Misalnya, dalam pola All Product -> Category -> Sub Category -> Product Name. Kemudian tiap Cube memiliki ukuran (measure) yang berasal dar tabel fakta.
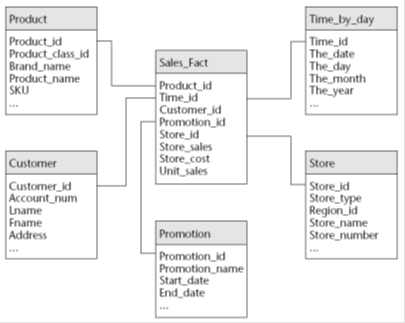
Gambar 13.1. Skema OLAP
13.2. Pembuatan CUBE
Buka kembali SQL Server BI Dev Studio, buat project baru degan mengambil database “MovieClick”. Berbeda dengan data source view yang lalu hanya satu tabel, untuk membuat cube kita harus memiliki tabel fakta dan dimensi. Untuk database movieclick, kita memiliki satu dimensi yaitu Customer dan tabel fakta misalnya yang disewa.
Langkah berikutnya adalah kita merelasikan antara dimensi dengan tabel fakta. Jangan sampai salah arahnya. Coba sendiri ya … Cao (Bersambung)