Mobile applications saat ini merupakan aplikasi yang paling banyak dipakai. Sebagai contoh, hampir jarang pengguna Facebook dengan browser. Mulai dari taxi online, hingga pembarayan menggunakan handphone. Kemudahan karena bentuk yang mudah dibawa menuntuk aplikasi-aplikasi (desktop dan website) disiapkan juga versi mobile-nya. Postingan kali ini hanya mengilustrasikan bagaimana mengkonversi aplikasi berbasis python yang kita buat menjadi aplikasi mobile, salah satu yang terkenal adalah berbasis Android.
Mobile applications are currently the most widely used applications. For example, it is rare to find Facebook users accessing it through a browser. From online taxis to mobile payments, smartphones have made it convenient to access various applications. As a result, many applications (both desktop and website-based) have prepared mobile versions. This post will illustrate how to convert a Python-based application into a mobile application, specifically focusing on the popular Android platform.
A. Kivy
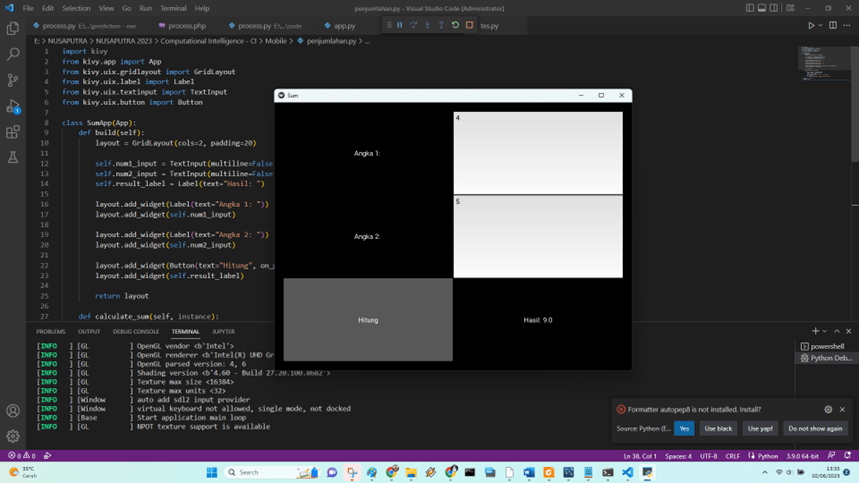
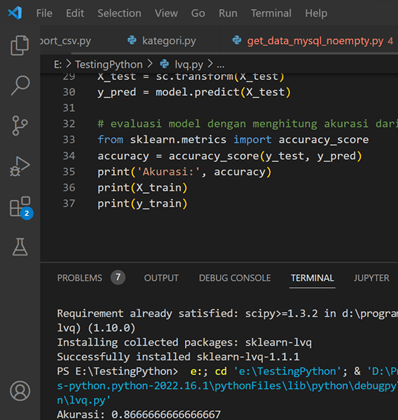
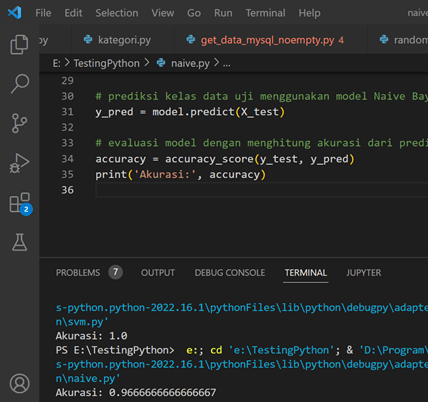
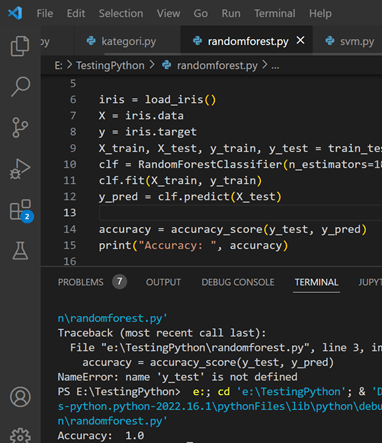
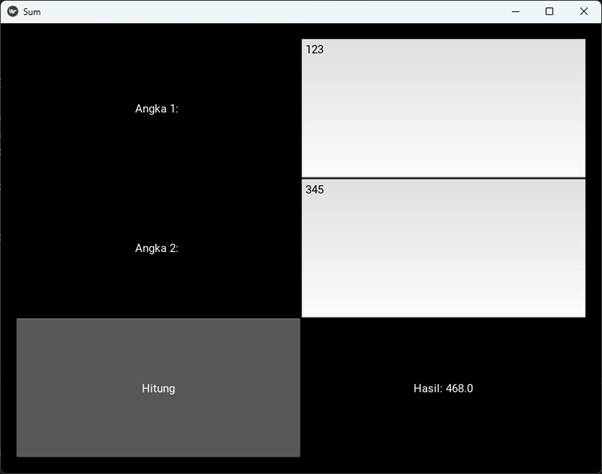
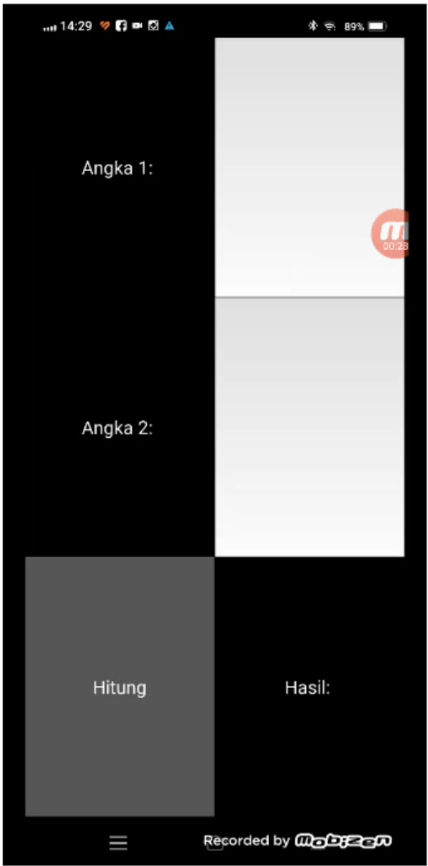
Salah satu library python yang banyak digunakan untuk membuat aplikasi Python agar bisa berjalan di mobile app adalah Kivy, lihat post terdahulu untuk lengkapnya. Masih menggunakan aplikasi pada post sebelumnya sebagai ilustrasi. Berikut tampilan GUI dengan Kivy setelah dirunningl.
One of the widely used Python libraries for creating Python applications that can run on mobile apps is Kivy, as mentioned in the previous post. Continuing with the application from the previous post as an illustration, here is the GUI appearance with Kivy after running it.
B. Buldozer
Buldozer merupakan satu paket berbasis Python untuk membuat apk dari bahasa Python yang dibuat dengan library kivy. Kira-kira tampilannya sebagai berikut. Silahkan lihat di google colab ini. Uniknya, buldozer dapat dijalankan lewat Google Colab, sehingga hanya membutuhkan browser saja. Metode lainnya lihat postingan ini.
Bulldozer is a Python-based package for creating APK files from Python code built with the Kivy library. Here is an example of its appearance. Please refer to this Google Colab link for more details. The unique feature of Bulldozer is that it can be executed through Google Colab, requiring only a web browser. For alternative methods, please refer to this post.
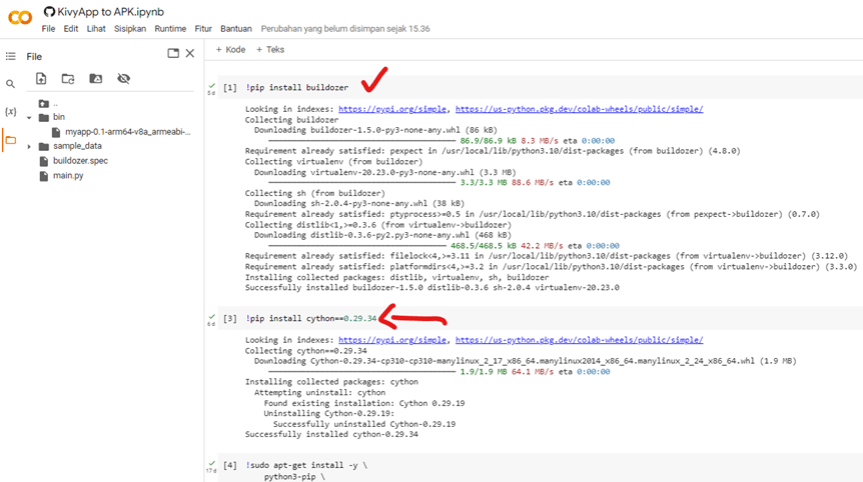
C. File Buldozer.spec
Perhatikan setiap instalasi pada cell di colab jangan sampai ada error (berwarna merah). Ketika inisialisasi, buldozer.spec muncul dan siap dijalankan, juga dengan Google Colab. Ganti nama aplikasi, tampilan splash dan icon. Untuk requirements di baris ke 40 tambahkan library-library yang digunakan, beserta versinya, misalnya kivy==2.2.0. Library lain tambahkan jika ada di impor pada header python, misal pillow, tensorflow, dll.
Please ensure that there are no errors (in red color) during the installation process in each cell in Colab. When initializing, the bulldozer.spec file will appear and is ready to be executed, even in Google Colab. You can rename the application, customize the splash screen, and change the icon. In line 40, add the required libraries along with their versions to the requirements, for example, kivy==2.2.0. If there are any additional libraries imported in the Python header, such as Pillow, TensorFlow, etc., please include them as well.
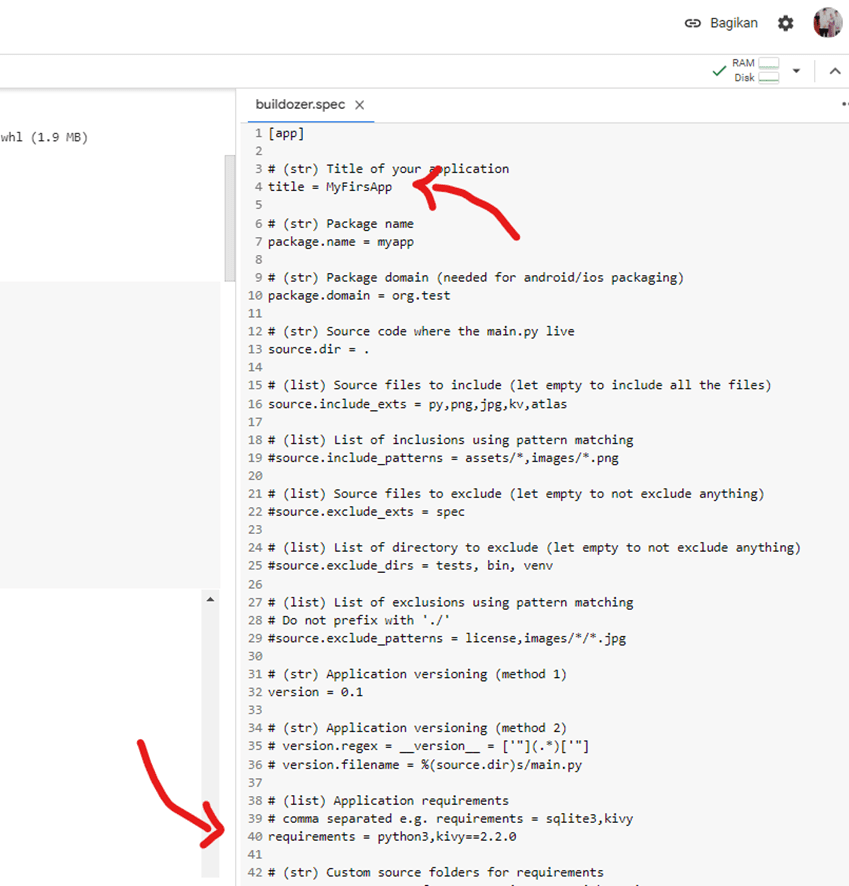
Jangan lupa menghilangkan hastag # jika akan digunakan. Please remember to remove the ‘#’ symbol if you intend to use the code.
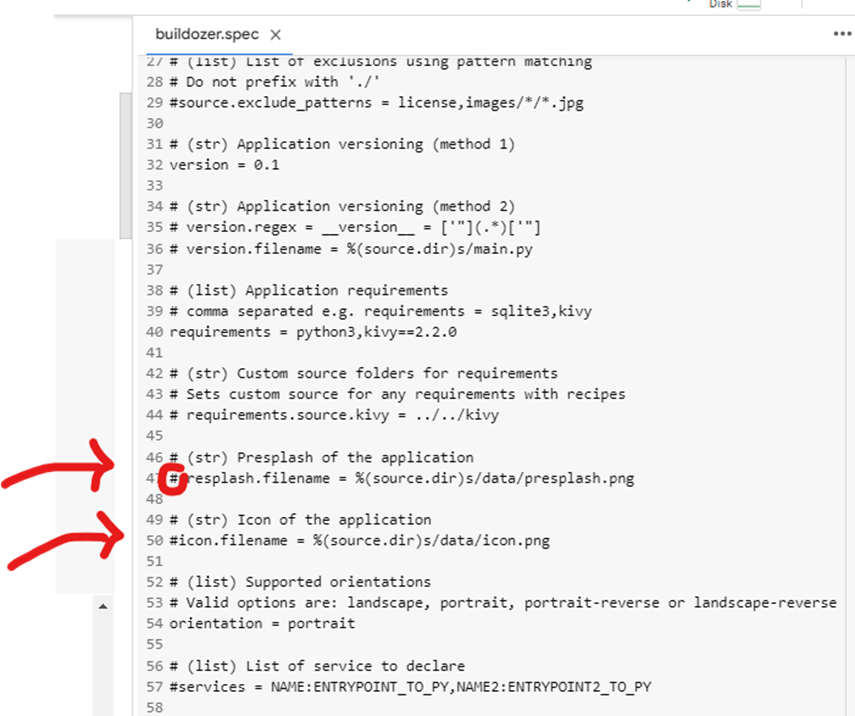
D. Menjalankan (running) File Apk
Nah, repotnya adalah proses kompilasi yang hampir setengah jam. Jika sudah tinggal dipindah apk yang dihasilkan untuk diinstal di handphone. Lokasi apk ada di folder bin. Pastikan Android paket sudah selesai terbentuk di bagian akhir google colab.
Well, the inconvenience lies in the compilation process which takes nearly half an hour. Once it’s done, you just need to transfer the generated APK file to your mobile device for installation. The APK file can be found in the ‘bin’ folder. Make sure that the Android package has been successfully created towards the end of Google Colab.
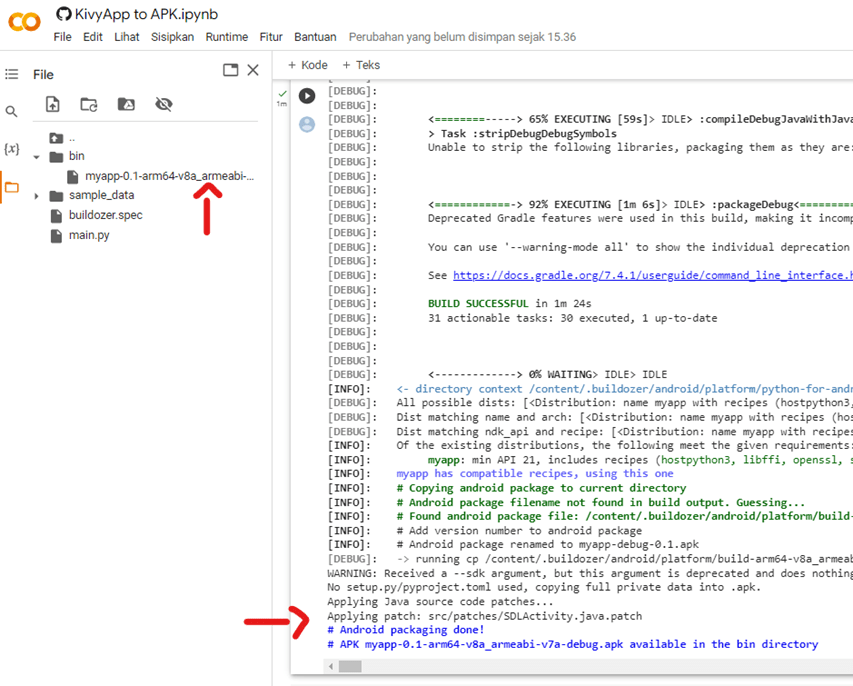
Tampilannya kira-kira seperti ini, mirip dengan versi Kivy python.
The appearance would be something like this, similar to the Kivy Python version.
Sekian, video youtube dapat dilihat di link berikut, terima kasih.
That’s all, the YouTube video can be viewed at the following link. Thank you.