Data Mining/25.03.2013/Sistem Informasi – S1
K-nearest Neighborhood (K-NN) adalah salah satu teknik klasifikasi yang sudah ada sejak dulu. Teknik ini memiliki prinsip kerja menemukan tetangga terdekat terhadap sampel daya yang akan diuji. Jika tetangga terdekatnya masuk dalam kategori kelas “A”, maka sample tersebut dapat dikatakan kelas “A”.
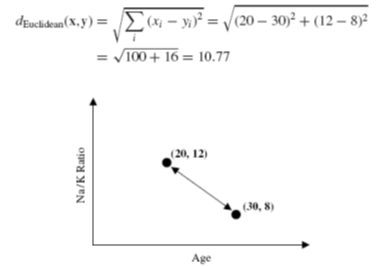
K-NN menggunakan teknik perhitungan jarak antara sampel dengan data yang telah ada (dikenal dengan istilah data training). K-NN masuk dalam kategori “Supervised Learning” karena data yang menjadi acuan (data training) memiliki Label (kelas tertentu). Berikut ini contoh pembuatan aplikasi dengan GUI untuk klasifikasi suatu sampel dengan K-NN. Berikut contoh perhitungan jarak antara titik sampel, misalnya (20,12) dengan salah satu data training, misalnya (30,8) dan diperoleh hasil 10.77.
Create New GUI and choose “Blank GUI”
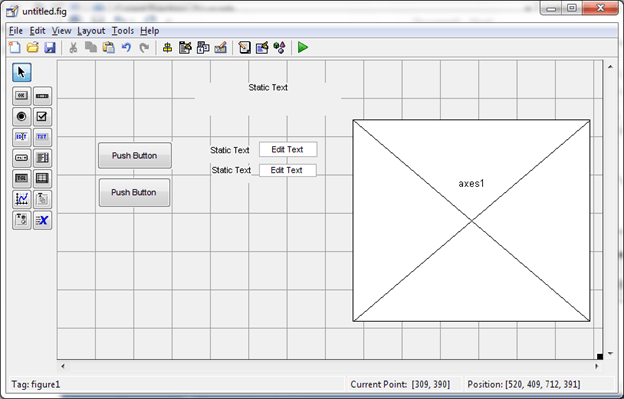
Rename every component.
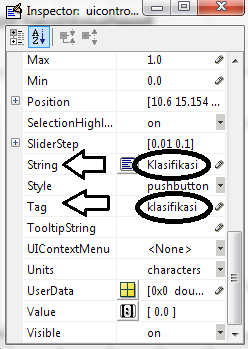
String and Tag on Property Editor must be renamed (Matlab is case sensitive)
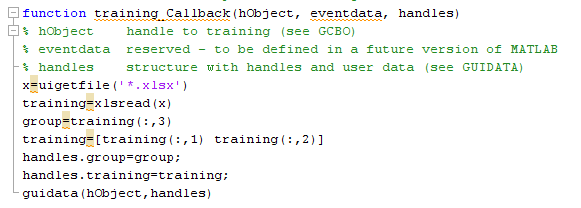
Save your work in order to get m-file that appear immediately after saving.

Look at the m-file above, you will see the functions according to your pushbutton and edit text. The green text will not be executed and sometimes you see “do not edit” warning. Chose the training_Callback function (see: https://rahmadya.com/2013/03/18/pengenalan-data-mining/ ):
Use your Excel to create training data
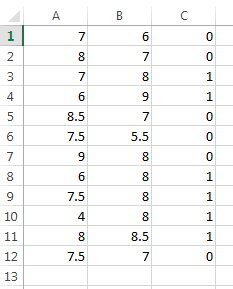
The last column is group, so you have to separate training and group in m-file.
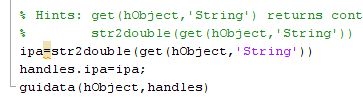
Back to m-file, we have to create script for capturing ipa and ips values. At function ipa_Calback and ips_Callback, use this script. Copy-paste this script for ips and replace “a” with “s” for easiness.
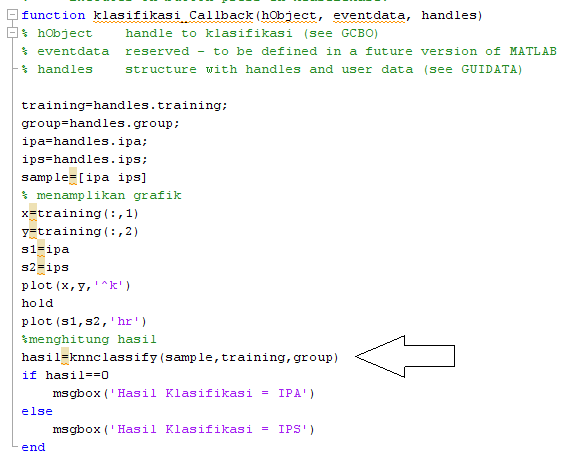
Last script is the core script because it contain k-nearest neighborhood classification using function “knnclassify“. See how to create plot for our GUI. The hold function means we do not erase the previous chart. We use “msgbox” (message box) to show the result of classification.
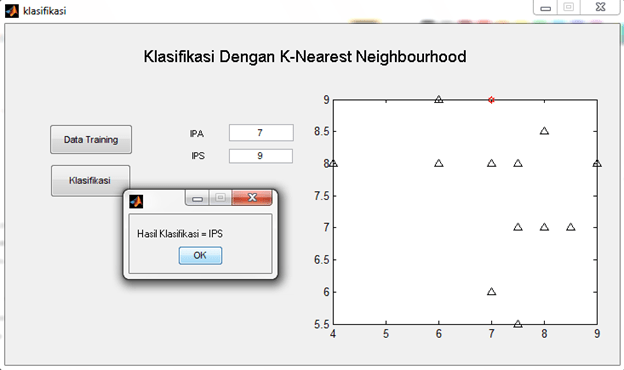
If the run icon is pressed, the result come after push “klasifikasi” button.
Next week we’ll discuss Kmeans.
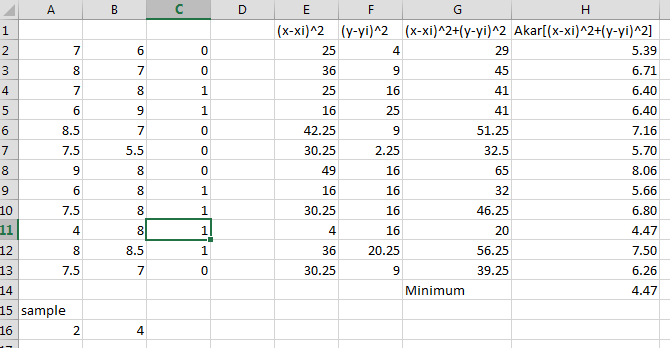
Tugas: Hitung jarak sampel (kel 1: (5,7) dan kel2 : (6,5)) terhadap data training, tentukan kelasnya berdasarkan data training tersebut (IPA atau IPS). Berikut hasil dengan Ms Excel

saya sudah mencoba tapi hasilnya eror dg keterangan:
Reference to non-existent field ‘group’.
Error in knn1>klasifikasi_Callback (line 95)
group=handles.group;
Error in gui_mainfcn (line 95)
feval(varargin{:});
Error in knn1 (line 42)
gui_mainfcn(gui_State, varargin{:});
Error in @(hObject,eventdata)knn1(‘klasifikasi_Callback’,hObject,eventdata,guidata(hObject))
Error while evaluating uicontrol Callback
mohon penjelasan
apakah group yang berisi 0 dan 1 sudah dibuat? sepertinya tidak berhasil memanggil field ‘group’.
bagaimana cara menampilkan perhitungan jarak euclidean yang dihasilkan dari program diatas?
Liat aja di fungsi norm dgn mengetik edit norm di command window
gimana caranya buat 6 Atribut?
kalo 6 atribut, caranya sama, cuma ya ga bisa diplot semua
pnentuan kelasx gmna ya ?
pnentuan kelasx gmna crax ya ?
kebanyakan menghitung jarak data ke pusat kluster terdekat. yang terbaik ya training ulang beserta data yang baru trus dilihat dia masuk kluster yg mana, untuk FCM cocok karena satu data dia memiliki prosesntasi kemungkinan masuk kluster yang mana, misal ke kluster A 0.2, kluster B 0.3 dan kluster C 0.5 maka data itu cocoknya di kluster C.
cara membuat dari awal gman saya masih pemula tolong di bantu,
ada dua bagian dari contoh kasus di atas: 1) pembuatan GUI dan 2) pembuatan core system “soft computing” dengan KNN, kira2 sisi yg mana?
Terima kasih ya mas Rahmadya