Jika pada postingan yang lalu dibahas clustering dengan jumlah kluster yang sudah ditetapkan dari awal, kali ini kita akan membahas clustering dengan jumlah kluster yang optimal. Optimal di sini masih menjadi perdebatan, terutama dalam menentukan kedekatan (similarity) antar anggota kluster. Makin tinggi nilai similarity antar elemen dalam kluster yang sama dan makin rendah dengan kluster yang berbeda, makin optimal proses clustering yang dilakukan. Banyak metode yang dapat digunakan untuk proses klusterisasi antara lain: k-means, FCM, DBSCAN, OPTICS, CLARANS, dan lain-lain. Tetapi untuk auto-clustering diperlukan iterasi untuk mencari titik pusat dan jumlah kluster terbaik. Salah satu situs yang cukup baik untuk menjadi rujukan klusterisasi adalah dari yarzip.com dengan metode evolutionarinya (genetic algorithms, particle swarm optimisation, dan differential evolution).
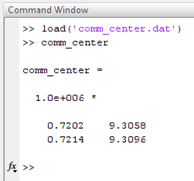
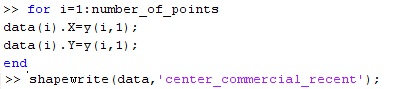
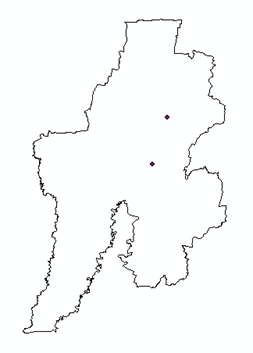
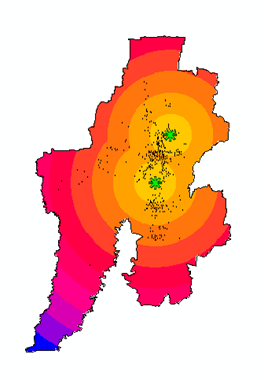
Dengan menggunakan data dari landuse optimisation, algoritma dari situs di atas dapat diterapkan. Misalnya saya akan mengkluster penggunaan lahan pemukiman. Dengan menggunakan Matlab 2013 hasil runningnya dapat dilihat berikut ini.