Tujuan dari disain interaksi adalah menghasilkan suatu sistem yang mudah digunakan oleh pengguna/operator. Tidak ada cara lain selain pendekatan yang manusiawi untuk menghasilkan sebuah sistem yang mudah digunakan. Hanya saja, terkadang suatu sistem dirancang untuk orang-orang tertentu yang kita tidak dapat pinta apa yang diinginkan, sehingga diperlukan bidang-bidang khusus seperti bahasa, budaya, seni, dan bidang lain yang kebanyakan di luar wilayah ilmu informatika.

Relasi antara bidang Ilmu lain dengan IMK (Sumber Gaynor)
Buat syarat disain interaksi untuk kasus-kasus perancangan sebuah sistem sebagai berikut (tugas kelompok):
-
Web: game anak-anak SD
-
Absensi karyawan (desktop)
-
Web: Pembayaran online Pajak untuk Pensiunan
-
Web: absensi karyawan
-
Game: Pembelajaran untuk balita (desktop)
-
Web: On-line Marketing busana muslimah
Ket:
-
Gunakan bahasa yang menjelaskan syarat penting untuk web tersebut
-
Posisikan kita sebagai calon pengguna
-
Tidak perlu pakai diagram, storyboard, dan sejenisnya (dibahas nanti)
-
Makin banyak ide anggota kelompok, hasil makin mendekati sempurna
-
Bisa juga dengan menyebutkan SYARAT YANG DILARANG untuk aplikasi tersebut
-
Jangan lupa menyebutkan unsur-unsur manusiawi lainnya (bosan, lupa, mau menang, dll).

Four different team members looking at the same square, but each seeing it quite differently. (Source: Gaynor).
Contoh:
Soal No.2. Absensi karyawan (desktop)
Syarat disain:
1. Bisa cepat absen (ujang)
2. Tidak bisa diabsenkan orang lain (rudy)
3. dll (sebanyak mungkin).
Jawaban:
-
Web Game anak-anak SD.
-
Nama web mudah diingat oleh anak-anak (Aulia)
-
Harus bersifat komunikatif, sehingga mudah dimainkan (Aulia).
-
Game tersebut diharapkan mengandung unsur edukasi di dalamnya sehingga tidak hanya untuk sarana hiburan tetapi juga sarana belajar (Ghozia)
-
Tidak mengandung kata-kata atau gambar yang berkaitan dengan pornografi (Neti)
-
Tidak mengandung unsur kekerasan dalam visualnya (Ghozia).
-
Game tersebut dapat merangsang daya pikir anak (Aulia).
-
Harus memiliki animasi-animasi yang menarik (Winda)
-
Harus memiliki instrumen yang sifatnya ceria sebagai back sound (Neti)
-
Harus memiliki warna2 yang mencolok/menarik (Winda)
-
Menggunakan jenis dan ukuran font yang menarik (Ghalih)
-
Absensi Karyawan (Desktop)
-
Usahakan absen lebih awal
-
Absensi tidak boleh diwakili
-
Menggunakan metode identifikasi: sidik jari, id+Password
-
Waktu identifikasi >= 1 sec
-
Kapasitas sidik jari dapat menampung >1500 sidik jari
-
Kapasitas data 32.000 data transaksi
-
Sidik yang disediakan semakin melengkapi kinerja dari mesin sidik jari.
-
(Didin, Arya, Gusti, Carolin)
-
Pembayaran Online Pajak untuk Pensiunan (Web)
-
Tidak perlu banyak form yang diisi (Ikmal)
-
Disain sesederhana mungkin tanpa menyampingkan fungsi-fungsi (M. Fadhlan)
-
Adanya petunjuk/pedoman/panduan form (Rachmat)
-
Akses cepat dan tidak susah (Yayan)
-
Terintegrasi dengan sistem perbankan online (M. Fdhlan)
-
Dapat diakses melalui berbagai piranti (wahyu)
-
Customer service dapat dihubungi 24 jam. (Yayan)
-
Bukti transaksi yang dapat di print/simpan (Wahyu)
-
Multilingual/translate (Ikmal)
-
Sistem Pengingat/pemberitahuan jatuh tempo pembayaran via sms/email (Rachmat).
-
Yang tidak perlu dialayani
-
-
Terlalu banyak gambar
-
Terlalu banyak animasi
-
Terlalu banyak iklan
-
Perpaduan warna yang berlebihan
-
Font tulisan bermacam-macam
-
Panduan rumit
-
Terlalu banyak form yang diisi
-
Pengisian ulang data diri
-
Image verifikasi yang rumit untuk dibaca
-
Absensi karyawan (Web)
-
Syarat Penting:
-
Harus melakukan login terlebih dahulu
-
Tidak bisa diabsenkan/diwakilkan orang lain
-
Harus terhubung dengan internet/server
-
Tampilan web efisien dan simple. Tidak mengandung banyak iklan
-
Id admin dengan id karyawan berbeda.
-
Tambahan:
-
-
Dapat juga digunakan untuk mengetahui sebe3rapa besar presentasi kehadiran karyawan pada sebuah perusahaan
-
Pembuatan web absensi karyawan sebaiknya menjadi satu dengan web perusahaan, agar para karyawan mudah mengakses web absensi karyawan tersebut.
-
Sistem absensi disesuaikan dengan waktu/jam kerja dari para karyawan.
-
(bintang Fajar, Dwiyudha, Ichsan, Eko hadi, Nurikhsan, M. Chairudin)
-
Game Pembelajaran balita
-
Desain game menarik dan sederhana (Anita)
-
Game mendidik dan merangsang daya pikir (Indah)
-
Penggunaan Bahasa dan suara yang mudah dimengerti (Astri)
-
Cara penggunaan/cara memainkan game mudah (frida)
-
Tidak mengandung unsur pornografi (Dwi)
-
Web: Online marketing busana muslimah
-
Judul web online harus simple dan menarik (laras)
-
Layout harus menarik (rizka)
-
Penyusunan tampilan teratur (rizka)
-
Interaksi antara admin dgn pengunjung baik (rizka)
-
Menampilkan katalog barang (desta)
-
Contack person ada (rizka)
-
Membuat animasi yang menarik di web (desta)
-
Menyediakan kolom pencarian produk yg tersedia (elmina)
-
Menyediakan kolom komentar (maulidha)
-
Menyediakan banyak pilihan model baju (Elmina)
-
Detail barang yang ditawarkan ada (laras)
-
Gambar model yang memakai sample pakaian (desta)
-
Perpaduan warna atraktif (Laras)
-
Promosi ke jejaring sosial (Maulidha)
-
Info barang sold out ada (Maulidha)
-
Mendeskripsikan cara penorderan (Elmina)
-
Penggunaan web yang mudah dikunjungi (Elmina)
-
Detail produk bisa dideskripsikan dengan suara juga (Maulidha)
-
Menyediakan mp3 player agar tidak membosankan (Maulidha)
Begitu .. bener apa salah? Tidak ada yang benar dan salah, yang ada jika nanti diaplikasikan, disukai oleh pengguna atau tidak. Seleksi alam akan terjadi dengan sendirinya.















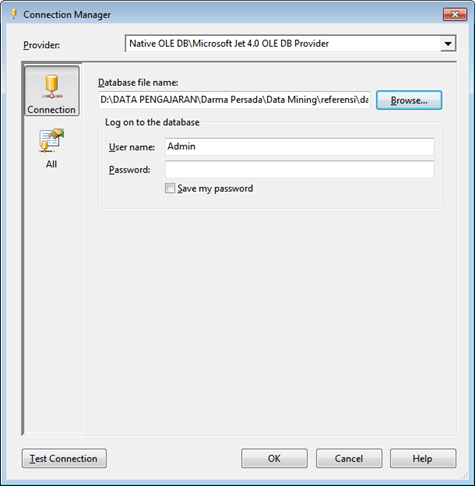

 “Process Mining …” untuk memproses Data Mining. Klik “Yes” dilanjutkan dengan proses Mining. Tunggu hingga selesai.
“Process Mining …” untuk memproses Data Mining. Klik “Yes” dilanjutkan dengan proses Mining. Tunggu hingga selesai.



