Saat ini metode-metode machine learning sepertinya sudah established sehingga pengguna tinggal memilih metode apa yang cocok. Beberapa jurnal juga sudah menyediakan laporan tentang kinerja metode-metode yang ada termasuk bagaimana meng-improve nya.
Kalau dulu kita harus membuat kode, menyiapkan data latih, validasi, dan testing, sekarang data sudah tersedia, misal daya IRIS pada Python. Bagaimana dengan metode? Seperti postingan yang lalu, kita bisa gunakan Chat GPT.
A. LVQ
Linear Vector Quantization (LVQ) adalah salah satu jenis jaringan saraf buatan yang digunakan untuk klasifikasi. LVQ digunakan untuk mengklasifikasikan suatu data ke dalam kategori yang telah ditentukan sebelumnya. Masukan kata kunci: “bagaimana membuat lvq dengan contoh data iris python?”.
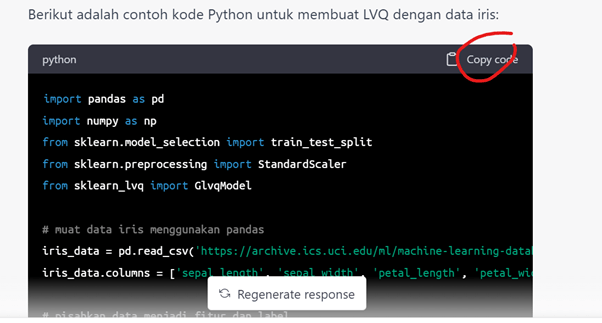
Kopi kode dengan mengklik pojok kanan atas. Lalu paste di Visual Studio Code (saya sarankan menggunakan editor praktis dan gratis ini).
Jika ada pesan No Module … berarti harus instal library dengan PIP. Lihat google bagaimana menginstal library tersebut. Setelah selesai, run visual studio code Anda. Oiya, instal dulu Python di visual studio code, buka terminal dan lihat hasil runnya.
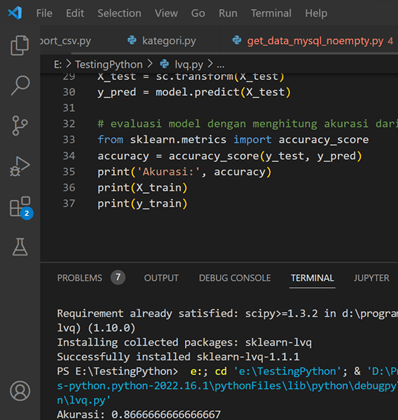
Akurasi LVQ untuk dataset IRIS ternyata 86.67%. Berikutnya kita coba Naïve Bayes.
B. Naïve Bayes
Masukan kata kunci: “bagaimana klasifikasi naive bayes data iris python?” seperti sebelumnya, dengan mengganti LVQ dengan Naïve Bayes.
Algoritma Naive Bayes bekerja dengan menghitung probabilitas kelas target dari suatu data berdasarkan probabilitas masing-masing fitur yang terdapat pada data tersebut. Algoritma ini memiliki tiga jenis dasar yaitu Naive Bayes Gaussian (untuk data yang berdistribusi normal), Naive Bayes Multinomial (untuk data yang terdiri dari frekuensi hitung), dan Naive Bayes Bernoulli (untuk data biner).
Dengan cara yang sama, copas kode masukan ke Visual Studio Code, jalankan dan ternyata diperoleh akurasi di atas LVQ, yakni 96.67%.
C. Support Vector Machine (SVM)
SVM sangat terkenal karena keampuhannya, namun kurang disukai karena proses yang lambat. Support Vector Machine (SVM) adalah salah satu algoritma pembelajaran mesin yang digunakan untuk klasifikasi dan regresi. SVM bekerja dengan membuat sebuah hyperplane (bidang pemisah) yang dapat membedakan antara kelas-kelas data pada sebuah ruang fitur (feature space).
SVM bertujuan untuk mencari hyperplane yang optimal, yaitu hyperplane yang memberikan margin terbesar (jarak terbesar antara hyperplane dan data dari setiap kelas) antara kelas-kelas data. Margin adalah jarak antara dua hyperplane yang sejajar dan melewati data terdekat dari masing-masing kelas. Dalam hal ini, SVM mengambil data yang berada di dekat hyperplane untuk membuat keputusan kelas.

Ternyata akurasinya cukup ampuh, 100%. Jauh di atas Naïve Bayes, apalagi LVQ.
D. Random Forest (RF)
Ada satu model machine learning klasik yaitu Random Forest (RF) yang cukup terkenal. Random Forest (hutan acak) adalah salah satu algoritma pembelajaran mesin yang populer untuk masalah klasifikasi dan regresi. Algoritma ini menggabungkan konsep dari dua teknik pembelajaran mesin, yaitu pohon keputusan (decision tree) dan teknik bootstrap aggregating atau bagging.
Dalam algoritma Random Forest, beberapa pohon keputusan dibangun secara acak dengan menggunakan subset acak dari fitur-fitur dataset. Hal ini dilakukan untuk menghindari overfitting, yang dapat terjadi ketika sebuah pohon keputusan dibangun pada semua fitur.
Metode ini ternyata cukup akurat, sama dengan SVM, 100% akurat.
Bagaimana untuk publikasi jurnal? Tentu saja saat ini jurnal membutuhkan novelty atau kontribusi. Jika tulisan ini akan dipublish di jurnal internasional, pasti ditolak karena tidak ada kebaruan baik dari metode, maupun dataset implementasi.
Improve Metode vs Domain Implementation
Bagi peneliti ilmu komputer biasanya menemukan metode yang lebih baik dari yang ada sekarang, baik dengan murni baru atau hybrid/penggabungan dengan metode yang ada agar dihasilkan metode baru yang lebih cepat dan akurat.
Terkadang bidang tertentu, seperti kedokteran, SIG, keuangan dan lain-lain dapat menerapkan metode yang telah ada. Hal ini terkadang dianggap kontribusi, terutama pada bidang-bidang yang memang jarang disentuh Machine Learning.
Ditolak atau tidaknya naskah terkadang dilihat dari hal tersebut, jika fokus ke perbaikan metode, maka jika tidak ada model usulan, pasti ditolak. Tapi jika fokus ke domain implementation, jika pada pembahasan hanya membahas akurasi model maka dipastikan naskah tidak tepat, karena seharusnya pembahasan fokus ke domain implementation (impak terhadap domain baik dari sisi sistem atau kebijakan). Sekian semoga bermanfaat.