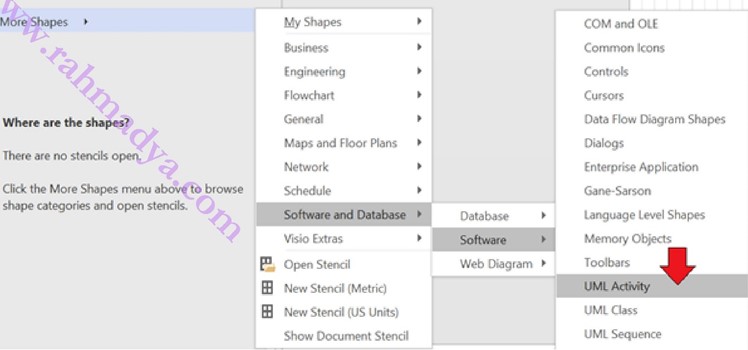
Particle Swarm Optimization (PSO) has been widely used for solving optimization problems. This method has many advantages, in particular for the computational complexity. PSO mimics the flock of bird or the school of fish when searching for foods. It faster than genetic algorithms (GAs), so become the first choice when optimizing the complex problems, such as multi-objective optimization, optimization with many constraints, etc. Following is the particle velocity calculation and its new location.

Many source codes can be found in the internet, for example this panda site. This beautiful code use object-oriented style with some classes. Some functions inside a class are easy to understand. This code can be copied and pasted in your jupyter notebook. As usual, use the Anaconda Navigator to choose the right environment. This code only uses a simple library: math, and matplotlib.

Choose your working directory to open the Jupyter Notebook by typing “juypyter notebook”. The Jupyter notebook then suddenly appear in your browser. Copy and paste the code to run the sample of PSO. This sample use two variables (X0 and X1). Use mm=-1 for minimizing problem and mm=1 for maximizing problem. A main class run two previous classes (Particle and PSO) to show the optimum result with a performance chart.

Here is the code:
import random
import math
import matplotlib.pyplot as plt
#------------------------------------------------------------------------------
# TO CUSTOMIZE THIS PSO CODE TO SOLVE UNCONSTRAINED OPTIMIZATION PROBLEMS, CHANGE THE PARAMETERS IN THIS SECTION ONLY:
# THE FOLLOWING PARAMETERS MUST BE CHANGED.
def objective_function(x):
y = 3*(1-x[0])**2*math.exp(-x[0]**2 - (x[1]+1)**2) - 10*(x[0]/5 - x[0]**3 - x[1]**5)*math.exp(-x[0]**2 - x[1]**2) -1/3*math.exp(-(x[0]+1)**2 - x[1]**2);
return y
bounds=[(-3,3),(-3,3)] # upper and lower bounds of variables
nv = 2 # number of variables
mm = -1 # if minimization problem, mm = -1; if maximization problem, mm = 1
# THE FOLLOWING PARAMETERS ARE OPTIMAL.
particle_size=100 # number of particles
iterations=200 # max number of iterations
w=0.85 # inertia constant
c1=1 # cognative constant
c2=2 # social constant
# END OF THE CUSTOMIZATION SECTION
#------------------------------------------------------------------------------
class Particle:
def __init__(self,bounds):
self.particle_position=[] # particle position
self.particle_velocity=[] # particle velocity
self.local_best_particle_position=[] # best position of the particle
self.fitness_local_best_particle_position= initial_fitness # initial objective function value of the best particle position
self.fitness_particle_position=initial_fitness # objective function value of the particle position
for i in range(nv):
self.particle_position.append(random.uniform(bounds[i][0],bounds[i][1])) # generate random initial position
self.particle_velocity.append(random.uniform(-1,1)) # generate random initial velocity
def evaluate(self,objective_function):
self.fitness_particle_position=objective_function(self.particle_position)
if mm == -1:
if self.fitness_particle_position < self.fitness_local_best_particle_position:
self.local_best_particle_position=self.particle_position # update the local best
self.fitness_local_best_particle_position=self.fitness_particle_position # update the fitness of the local best
if mm == 1:
if self.fitness_particle_position > self.fitness_local_best_particle_position:
self.local_best_particle_position=self.particle_position # update the local best
self.fitness_local_best_particle_position=self.fitness_particle_position # update the fitness of the local best
def update_velocity(self,global_best_particle_position):
for i in range(nv):
r1=random.random()
r2=random.random()
cognitive_velocity = c1*r1*(self.local_best_particle_position[i] - self.particle_position[i])
social_velocity = c2*r2*(global_best_particle_position[i] - self.particle_position[i])
self.particle_velocity[i] = w*self.particle_velocity[i]+ cognitive_velocity + social_velocity
def update_position(self,bounds):
for i in range(nv):
self.particle_position[i]=self.particle_position[i]+self.particle_velocity[i]
# check and repair to satisfy the upper bounds
if self.particle_position[i]>bounds[i][1]:
self.particle_position[i]=bounds[i][1]
# check and repair to satisfy the lower bounds
if self.particle_position[i] < bounds[i][0]:
self.particle_position[i]=bounds[i][0]
class PSO():
def __init__(self,objective_function,bounds,particle_size,iterations):
fitness_global_best_particle_position=initial_fitness
global_best_particle_position=[]
swarm_particle=[]
for i in range(particle_size):
swarm_particle.append(Particle(bounds))
A=[]
for i in range(iterations):
for j in range(particle_size):
swarm_particle[j].evaluate(objective_function)
if mm ==-1:
if swarm_particle[j].fitness_particle_position < fitness_global_best_particle_position:
global_best_particle_position = list(swarm_particle[j].particle_position)
fitness_global_best_particle_position = float(swarm_particle[j].fitness_particle_position)
if mm ==1:
if swarm_particle[j].fitness_particle_position > fitness_global_best_particle_position:
global_best_particle_position = list(swarm_particle[j].particle_position)
fitness_global_best_particle_position = float(swarm_particle[j].fitness_particle_position)
for j in range(particle_size):
swarm_particle[j].update_velocity(global_best_particle_position)
swarm_particle[j].update_position(bounds)
A.append(fitness_global_best_particle_position) # record the best fitness
print('Optimal solution:', global_best_particle_position)
print('Objective function value:', fitness_global_best_particle_position)
print('Evolutionary process of the objective function value:')
plt.plot(A)
#------------------------------------------------------------------------------
if mm == -1:
initial_fitness = float("inf") # for minimization problem
if mm == 1:
initial_fitness = -float("inf") # for maximization problem
#------------------------------------------------------------------------------
# Main PSO
PSO(objective_function,bounds,particle_size,iterations)