Terkadang ketika menutup word kita lupa menyimpan, padahal berisi naskah penting. Biasanya terjadi ketika banyak membuka file draft yang sementara. Ketika meng-close terkadang sengaja kita tidak menyimpan, padahal mungkin ada satu file penting yang ikut tidak disimpan karena terburu-buru menutup aplikasi.
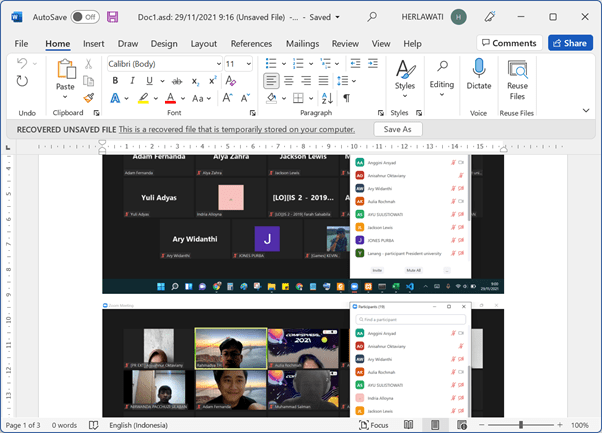
Microsoft Word menyediakan fasilitas tersebut, langkahnya adalah sebagai berikut. Masuk ke Menu File. Lalu pilih Manage Document di bagian bawah.
Tekan Icon Manage Document lalu pilih Recover Unsave Document. Di sana tampak file-file Anda yang tidak disimpan.
Biasanya kalau baru masih tersimpan di sana dengan ekstensi *.asd, entah mengapa nama ekstensi-nya ASD mungkin singkatan dari ASal Ditutup .. hehe. Klik saja dan Anda akan berhasil menyelamatkan ketikan penting yang lupa ditutup (padahal itu absen kelas ngajar online). Sekian, semoga bermanfaat.
Tahun 2014 saya masih menjadi mahasiswa doktoral Information Management. Ada satu mata kuliah: Decision Support Technologies yang berisi bagaimana sistem informasi membantu pengambil keputusan, salah satunya dengan pemanfaatan Big Data.
Waktu itu saya satu grup dengan mhs dari Thailand dan Uzbekistan. Tugasnya cukup menarik, yaitu menggunakan data dari Kagel yang berisi jutaan record penulis artikel ilmiah yang masih kasar (raw). Targetnya adalah mengumpulkan penulis yang berserakan menjadi rapih, dimana tidak ada redundansi penulis. Terkadang ada nama penulis yang terbalik susunannya, tanpa nama tengah, dan lain-lain. Selain itu perlu deteksi untuk afiliasi dan bidang ilmunya. Yang tersulit adalah terkadang nama belakang perempuan yang mengikuti nama suami.
Kendala utamanya adalah data yang berukuran besar baik dari sisi kapasitas maupun jumlah record. Ketika dibuka dengan Excel, tidak seluruhnya terambil karena ada batas record Microsoft Excel yakni sebanyak 1,048,576 record dan 16,384 kolom. Terpaksa menggunakan sistem basis data, yang termudah adalah Microsoft Access. Waktu itu fasilitas Big Data pada Matlab masih minim, terpaksa ketika menjalankan pemrosesan paralel, secara bersamaan dibuka 3 Matlab sekaligus (lihat postingan saya tahun 2014 yang lalu).
Tipe Data Tall
Sekitar tahun 2016-an Matlab memperkenalkan tipe data Tall dalam menangani data berukuran besar. Prinsipnya adalah proses upload ke memory yang tidak langsung. Sebab kalau ketika impor data dengan cara langsung maka akibatnya memory akan habis, biasanya muncul pesan ‘out of memory‘. Oleh karena itu Matlab membolehkan mengupload dengan cara ‘mencicil’. Tentu saja untuk memperoleh hasil proses yang lengkap dengan bantuan fungsi gather.
Seperti biasa, cara mudah mempelajari Matlab adalah lewat fasilitas help-nya yang lengkap, maklum software ‘berbayar’. Lisensinya saat ini sekitar 34 jutaan, kalau hanya setahun sekitar 13 juta dan kurang dari 1 juta untuk pelajar. Pertama-tama ketik saja di Command Window: help tall. Pastikan muncul, jika tidak muncul, berarti Matlab Anda belum support fungsi Big Data tersebut. Walau mahal, tetapi Anda bisa mencoba sebulan secara gratis. Ok, jalankan saja help yang muncul.
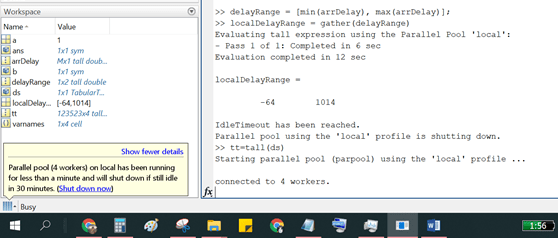
Dengan fungsi datastore, pertama-tama sampel Big Data disiapkan. Di sini masih menggunakan Comma Separated Value (CSV). Perhatikan hasil proses fungsi tall yang berupa matriks berukuran Mx4. Nah, disini istilah M muncul yang berarti ‘beberapa’, karena yang ditarik belum seluruhnya.
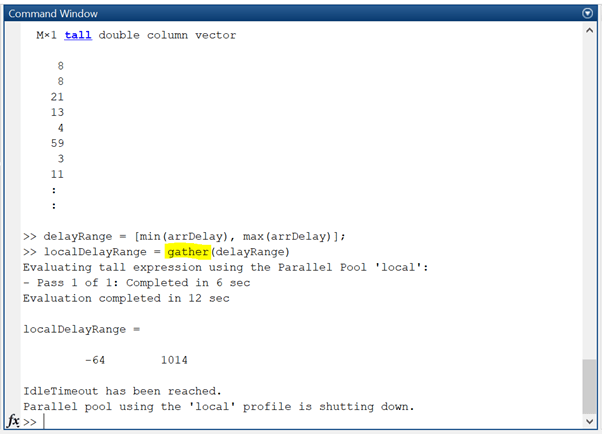
Tampak paralel pool sudah terbentuk, dengan 4 worker. Di sini dibatasi 30 menit, jika idle/tidak digunakan akan di-shutdown. Terakhir, fungsi gather dibutuhkan untuk merekapitulasi hasil olah.
Tampak informasi pooling yang merupakan ciri khas pemrosesan paralel telah selesai dilakukan. Sekian, semoga informasi ini bermanfaat.
Pada postingan yang lalu telah dibahas klasterisasi dengan KMeans menggunakan bahasa Matlab. Kali ini kita coba menggunakan bahasa Python dengan GUI Jupyter notebook pada Google (Google Colab).
Sebelumnya kita siapkan terlebih dahulu file data sebagai berikut. Kemudian buka Google Colab untuk mengklasterisasi file tersebut. Sebagai referensi, silahkan kunjungi situs ini. Saat ini kita dengan mudah memperoleh contoh kode program dengan metode tertentu lewat google dengan kata kunci: colab <metode>.
Mengimpor Library
Library utama adalah Sklearn dengan alat bantu Pandas untuk pengelolaan ekspor dan impor file serta matplotlib untuk pembuatan grafik.
from sklearn.cluster import KMeans
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
from matplotlib import pyplot as plt
Perhatikan di sini KMeans harus ditulis dengan K dan M berhuruf besar, begitu pula kelas-kelas yang lain seperti MinMaxScaler
Menarik Data
Perhatikan data harus diletakan di bagian file agar bisa ditarik lewat instruksi di bawah ini. Jika tidak maka akan muncul pesan error dimana data ‘beasiswa.csv’ tidak ada.
Selain itu tambahkan instruksi untuk mengeplot data. Tentu saja ini khusus data yang kurang dari 3 dimensi. Jika lebih maka cukup instruksi di atas saj.
Nah, hal terpenting adalah tidak hanya menghitung y_predicted saja melainkan melabel kembali datanya. Percuma saja jika kita tidak mampu memetakan kembali siapa saja yang masuk kategori klaster ‘0’ dan ‘1’.
df[‘klaster’]=y_predicted
print(df)
Finishing
Di sini langkah terpenting lainnya adalah kembali memvisualisasikan dalam bentuk grafik dan menyimpan hasilnya dalam format CSV.
Hasilnya adalah grafik dengan pola warna yang berbeda tiap klaster-nya.
Salah satu kelebihan Pandas adalah dalam ekspor dan impor data. Dalam hal ini kita akan menyimpan hasil klasterisasi dengan nama ‘klasterisasi.csv’. Lihat panduan lengkapnya di sini.
df.to_csv(‘klasterisasi.csv’)
Silahkan file hasil sempan diunduh karena Google Colab hanya menyimpan file tersebut sementara, kecuali kalau Anda menggunakan Google Drive (lihat caranya). Untuk mengujinya kita buat satu sel baru dan coba panggil kembali file ‘klasterisasi.csv’ yang baru terbentuk itu. df=pd.read_csv(‘klasterisasi.csv’)
df.head()
Note: ada field yang belum dinamai (Unnamed), bantu ya di kolom komentar caranya. Oiya, MinMaxScaler digunakan untuk jika data ‘jomplang’ misalnya satu dimensi, IPK dari 0 sampai 4 sementara misalnya penghasilan jutaan, tentu saja KMeans ‘pusing’. Oleh karena itu perlu dilakukan proses preprocessing. Sekian, semoga bermanfaat.
Era Industri 4.0 ditandai dengan perkembangan IT, salah satunya adalah Big Data. Dengan konsep serba “V” seperti “velocity”, “volume”, dan “v” lainnya membuat siapa yang bisa memanfaatkannya akan menang dalam persaingan. Bentuk Big Data yang “Variety” membuat rumitnya pengaksesan dan pengolahan, khususnya data yang tidak terstruktur dimana tidak berlaku standar QUERY lagi.
Beragamnya jenis data mengakibatkan para perancang aplikasi saat ini tidak lagi berpatongan dengan “single database” yang dikenal dengan istilah monolitik. Tentu saja akan sulit menyimpan beragam tipe data dalam satu sistem basis data, misalnya sistem yang terdiri data Geospasial harus bekerja sama dengan Non-Spasial.
Microservices
Untuk mengatasi beragamnya jenis basis data, saat ini banyak yang menerapkan metode microservices yang membagi aplikasi menjadi service-service kecil. Selain bermanfaat ketika dihadapkan dengan jenis tipe data yang beragam, microsoervices juga dapat mengatasi “bottleneck” ketika satu transaksi akan diakses oleh banyak pengguna, misalnya ketika deadline atau hari terakhir submit.
Aplikasi-aplikasi E-Commerce seperti Gojek, Grab, Traveloka, dan lain-lain sudah pasti menggunakan prinsip tersebut. Perpaduan antara data spasial yang dibutuhkan mitra, gudang data yang menggunakan NoSQL, misalnya mongodb, akan menyulitkan jika server hanya satu. Traveloka pun menggunakan prinsip mengakses service dari situs lain, seperti Lion, AirAsia, Garuda, dan maskapai lainnya, selain tentu saja hotel dan akomodasi pendukungnya. Servis ini dikenal dengan istilah Application Programming Interface (API). API ini ibarat tombol yang dapat diakses oleh siapapun tanpa harus menggunakan bahasa pemrograman atau platform yang digunakan oleh penyedia. Ibarat tombol listrik, tidak peduli arus searah atau bolak-balik, yang penting pengguna dapat menekan tombol on-off.
Data Semistructure
Dalam pertukaran data, aplikasi berbasis web tidak menerapkan format data terstruktur dengan baris dan kolom. Jenis data yang digunakan adalah tipe yang ramah dengan HTML, yakni XML dan Jason. Nah, ketika transaksi berjalan, dengan pertukaran message/pesan lewat metode REST ataupun SOAP, aplikasi lain dengan aman mengakses data dari service lain yang diijinkan.
Untuk mempraktikannya, misalnya kita buat sebuah database dengan aplikasi berbasis PHP-MySQL berisi data siswa. Ketika dibuat sebuah service, misalnya “data.php”, maka dapat digunakan untuk mengirim data lewat fungsi GET yang akan dimanfaatkan oleh fungsi lain. Banyak server-server testing yang gratis yang dapat dimanfaatkan. Tentu saja, yang berbayar lebih baik seperti Amazon Web Service (AWS) dan sejenisnya.
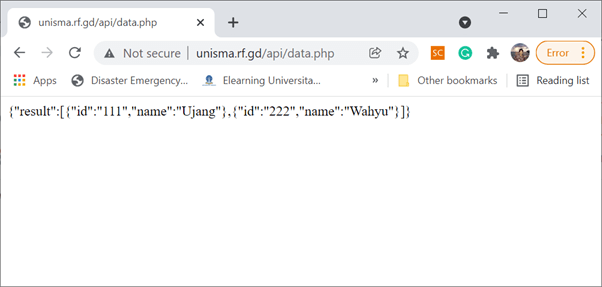
Aplikasi di atas menunjukan bagaimana service diakses langsung dari PHP server. Ketika mengakses data di atas, sistem tidak secara langsung mengakses basis data lewat SQL melainkan lewat format GET yang disiapkan oleh satu file bernama “data.php” lewat “form_get.php” untuk mempersiapkan data berformat Jason.
Sebagai bukti servis dapat dimanfaatkan oleh aplikasi lain, lewat browser kita dapat langsung mengakses “data.php” yang berisi data siswa. Tentu saja perlu menambahkan API key agar menjaga akses dari pihak-pihak yang tidak diijinkan, terutama untuk service POST dan PUT yang menginput dan mengedit data. Untuk jelasnya silahkan lihat video berikut, semoga bermanfaat.
Menilai lebih mudah dari membuat. Coba baca satu artikel pada jurnal bereputasi, misalnya satu paragraf saja. Tampak mudah dibaca dan mengalir lancar. Terlihat sederhana dan mudah dipahami, namun ketika kita mencoba membuat seperti itu, menit berlalu, bahkan sudah berjam-jam, belum juga bisa membuat tulisan seperti itu.
Teringat ketika membuat skripsi waktu S1. Selesai menulis dan sidang akhir, saya merasa banyak salah tulis, baik dari tata bahasa maupun kesalahan-kesalahan lainnya. Anehnya waktu itu lulus tanpa revisi, yang menjadi misteri bagi saya bertahun-tahun.
Ketika mulai bekerja sebagai pengajar di salah satu kampus di Jakarta dan membimbing tugas akhir. Banyak siswa yang ternyata memiliki masalah yang sama dengan saya ketika menjadi mahasiswa dahulu, yaitu menulis. Mengingat kejadian waktu saya kuliah dahulu, jarang sekali saya memberikan revisi yang banyak ke siswa, dan menolerir kesalahan-kesalahan yang tidak penting.
Waktu kuliah S2 saya mengalami kejadian mirip S1, yaitu tanpa revisi. Tetapi hal ini terjadi karena saya sidang ulang akibat ada masalah administratif dengan sidang pertama. Alhasil sidang ulang hanya seperti diskusi saja. Nah, yang agak unik ketika disertasi.
Jenjang S3 membutuhkan waktu yang lebih lama dibanding level lainnya, baik dari sisi eksperimen maupun penulisan laporannya. Ditambah lagi syarat publikasi di jurnal internasional bereputasi membuat mahasiswa harus mampu menulis. Namun jangan khawatir, karena tulisan hanya melaporkan saja apa yang telah dilakukan, akhirnya pasti akan selesai juga.
Tiap kampus berbeda-beda dalam tata cara sidang. Kebetulan di kampus saya sebelum disidangkan, naskah harus dicek oleh dosen luar kampus. Revisi dari luar pun hanya istilah-istilah tertentu yang harus diganti, mengikuti standar yang ‘lebih umum’, dan menghindari bentuk-bentuk jargon tertentu. Tidak ada revisi besar.
Nah, uniknya walau saat sidang terjadi kontroversi mengenai kesimpulan, akhirnya salah satu penguji menyetujui format kesimpulan yang ada di tiap bab pembahasan, mengingat bidang saya multidisiplin maka ketika pembahasan pada bidang ilmu komputer di akhir bab dimasukan pula kesimpulan bidang ilmu komputer. Bab yang membahas perencanaan tata ruang, di bagian akhir bab diisi pula kesimpulan bidang tersebut, dan seterusnya hingga ada kesimpulan umum di akhir tulisan.
Saat itu saya berencana merevisi sesuai argumen salah satu penguji karena menurut saya benar. Ketika menghadap dosen pembimbing dan mengutarakan maksud saya ternyata di luar dugaan dia tidak setuju. Kalau pun mau merivisi sedikit saja, sambil menjentikan jari ke saya memberi kode berarti ‘sedikit sekali’. “Disertasi adalah tulisan terburukmu”, lalu malah menanyakan tulisan paper-paper berikutnya yang perlu di-publish. Dengan kata lain berarti tulisan saya berikutnya harus lebih baik dari disertasi saya tersebut. Ternyata itu jawaban tidak pernah revisi selama ini. Artinya tulisan terakhir kita, walaupun kita anggap tulisan terbaik, sekaligus menjadi tulisan terburuk, karena tulisan kita berikutnya harus lebih baik lagi.
Kalau pun revisi, itu pun dianggap edisi tersendiri dalam sebuah terbitan seperti gambar di bawah. Sekian semoga bisa menginspirasi.