Buku teks atau buku ajar ada bermacam-macam. Ada yang berupa kumpulan penulis-penulis yang membahas topik tertentu (book chapter atau book section), ada pula yang hanya beberapa penulis membahas seluruh topik di suatu buku (buku teks). Sementara itu kebanyakan buku teks dibuat dalam bentuk kompilasi, yaitu kumpulan informasi yang berasal dari beragam sumber buku. Nah, kompilasi ini yang kerap saya jadikan patokan untuk menulis buku, karena lebih mudah. Ada juga jenis buku yang lain yaitu buku terjemahan, yang isinya hanya mengalih-bahasakan dari bahasa asing (biasanya bahasa Inggris) ke bahasa Indonesia tanpa menambah atau mengurangkan isinya. Hak cipta pun masih dipegang oleh buku sumber.
Bacalah
Membaca memang menjadi keharusan seorang pengajar karena informasi selalu berubah, apalagi dunia IT. Dalam kesehariannya terkadang ada debat antara satu dosen dengan dosen lainnya mengenai topik tertentu yang terkadang berimbas kepada siswa yang menjadi bimbingan tugas akhir, skripsi, atau pun tesis. Korban utamanya adalah si mahasiswa yang bingung harus mengikuti siapa? Pembimbing ataukah penguji. Untuk itu sebaiknya berpatokan kepada standar yang ada. Postingan kali ini saya mencoba membahasnya dalam dunia rekayasa perangkat lunak, khususnya UML.
Konflik Akademik
Sering saya menjumpai dosen-dosen yunior yang memang kebanyakan ahli dalam coding atau programming. Mungkin karena kesehariannya berasal dari instruktur lab yang naik pangkat jadi dosen. Terus terang ada manfaatnya karena mereka lebih mengetahui seluk beluk dan kesulitan yang dihadapi oleh mahasiswa yang kuliah IT. Masalah muncul ketika memasuki dunia akademis yang penuh dengan ilmu-ilmu baru yang selalu berkembang. Dosen yunior itu harus mempelajari perkembangan yang terjadi saat ini dan tidak kaku dan bersikukuh dengan bahasa pemrograman atau metode perancangan program yang dikuasainya. Lebih parah lagi, banyak juga yang merasa lebih jago dalam programming sehingga menganggap para dosen senior tidak tahu menahu prakteknya. Boleh saja beranggapan seperti itu, dan saya pun senang belajar dari mereka para dosen junior (sering disebut generasi milenial/generasi y). Sebenarnya malah menguntungkan para dosen-dosen senior.
Terus Membaca dan Belajar
Membaca buku-buku UML terkadang tidak ada habisnya. Muncul buku-buku baru yang terkadang membuat pusing jika kita tidak mampu memfilter-nya. Namun hanya membaca satu buku juga berbahaya karena membuat pembaca berfikiran sempit dan hanya memandang kebenaran dari satu sudut pandang saja, yaitu buku yang dia baca.
Misalnya pertama kali saya membaca satu buku yang khusus membahas UML, seluruh diagram dibahas. Namun di buku yang lain, dikatakan tidak semua developer menggunakan diagram UML, misalnya hanya diagram kelas, object, dan sequence. Tetapi buku yang lain yang berorientasi analisa disain menganggap diagram kelas dan use case lah yang penting, karena tidak semua stakeholder memahami pemrograman yang cocok dengan diagram sequence. Bahkan saya membaca satu buku khusus yang hanya membahas style yang baik dalam menggambar UML, misalnya ketika menggambar use case diagram, user di sebelah kiri dan admin di sebelah kanan dengan di tengah-tengahnya use case, unik juga. Tetapi bermanfaat juga sih, mengingat banyak siswa yang menggambar use case diagram acak adut, walaupun benar tetapi sulit dicerna.
Ribut terus berlanjut ketika ada yang membaca satu buku pemrograman berorientasi obyek yang menganggap UML harus diterapkan dalam pemrograman berbasis obyek saja. Pemrograman tanpa kelas tidak boleh menggunakan UML. Korbannya tidak lain adalah mahasiswa yang menjadi bimbingannya yang terkadang harus mengikuti outline yang disediakan kampus. Jika dosen itu membaca buku yang lain, dia mungkin akan berubah fikiran karena UML tidak harus untuk pemrograman berorientasi obyek, walaupun memang idealnya untuk berbasis object. Bahkan UML sendiri tidak melarang menggunakan diagram-diagram lainnya selama menambah kejelasan rancangan yang dibuatnya, terutama dalam komunikasi dengan user ataupun stakeholder.
Membaca Buku dengan Tema yang Berbeda
UML sangat berkaitan dengan tema-tema lainnya seperti rekayasa perangkat lunak dan analisa dan disain sistem. Beberapa buku rujukan utama software engineering uniknya sampai saat ini masih mengajarkan metode waterfall yang oleh kebanyakan pengembang saat ini banyak kelemahannya. Tetapi tetap saja 40% metode yang dipakai saat ini oleh pengembang menggunakan waterfall yang lebih mudah walaupun beresiko. Memang struktur yang jelas waterfall cocok dengan time frame perkuliahan. Namun, metode terkini yang bercirikan iterasi dan agile/extreem harus juga diperkenalkan.
Banyak hal-hal lain yang bisa kita pelajari dengan membaca lebih dari satu buku baik tema yang sejenis maupun tema lain yang memang saling berkaitan, misalnya pemrograman berorientasi obyek, rekayasa perangkat lunak, analisa dan disain sistem, pemrograman terstruktur, dan lain-lain. Untuk dunia akademik sendiri mau tidak mau harus menyampaikan seluruh informasi kepada siswa didik. Misalnya, untuk UML sebaiknya tidak hanya diagram-diagram yang sering digunakan di industri, melainkan wajib memberikan informasi secara total, walaupun terkadang membuat pusing baik mahasiswa maupun dosen (biasanya dilimpahkan pusingnya lewat tugas mahasiswa). Juga terkadang harus menghindari produk-produk dari vendor tertentu saja. Menggunakan software open source bisa jadi alternatif. Juga, antara dosen junior dan senior sebaiknya kompak dan saling bekerja sama sehingga bisa memberi ilmu dengan baik kepada siswa didik dan juga meningkatkan kinerja risetnya yang saat ini kita sudah berhasil mengalahkan Thailand dan sedikit lagi Singapura. Selanjutnya tinggal menghadapi Malaysia yang hampir dua kali jumlah publikasinya.

Sengaja saya tidak memberikan sitasi postingan ini karena memang untuk contoh kasus saja yang kemungkinan terjadi untuk tema perkuliahan yang lain. Mungkin pembaca, yang lebih senior dan expert, tidak sependapat dan bisa berbagi pengalaman. Semoga bermanfaat.








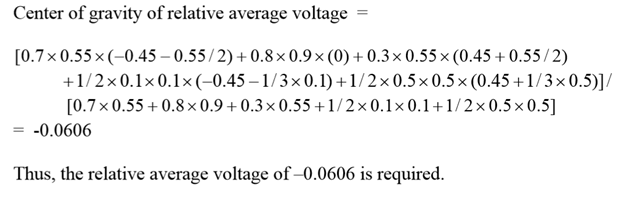





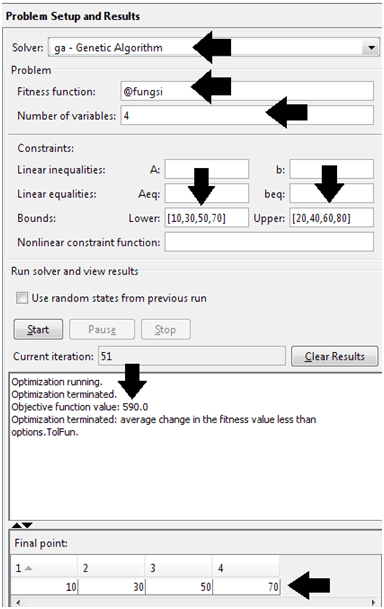
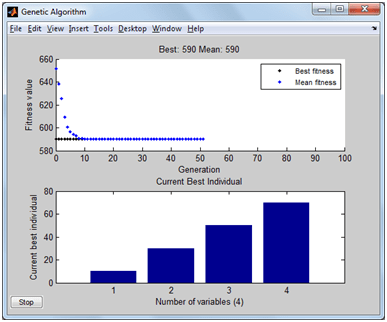
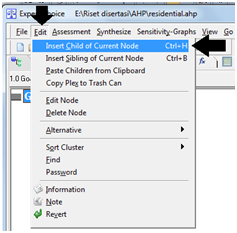
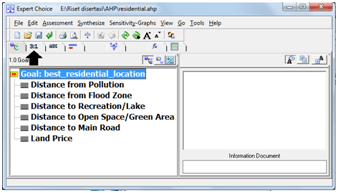
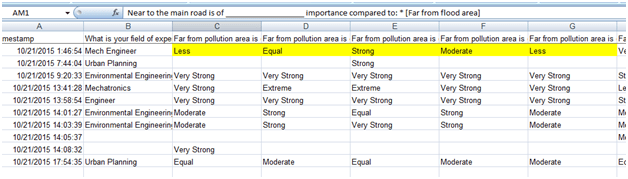
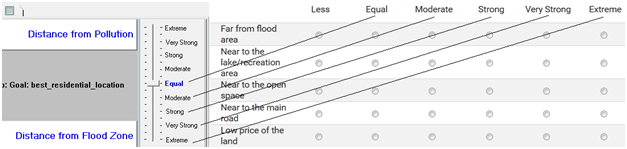
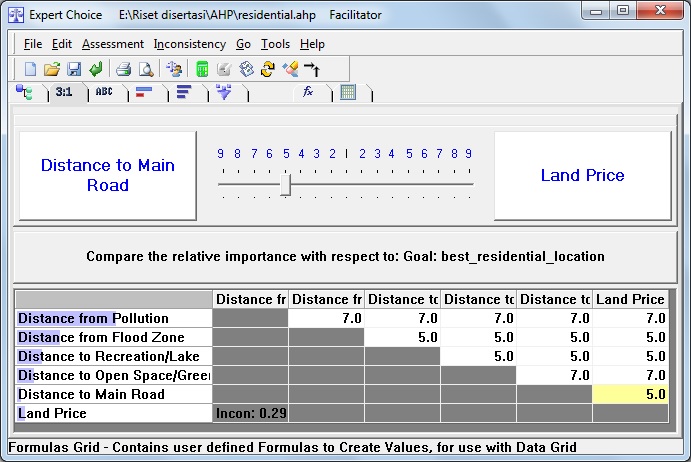
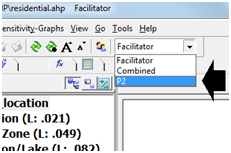
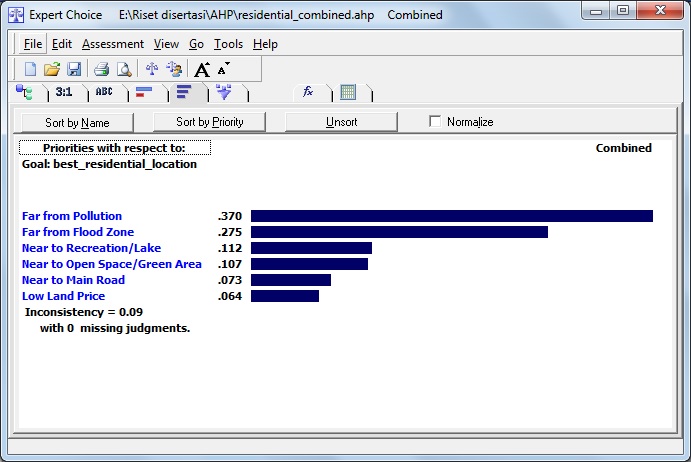
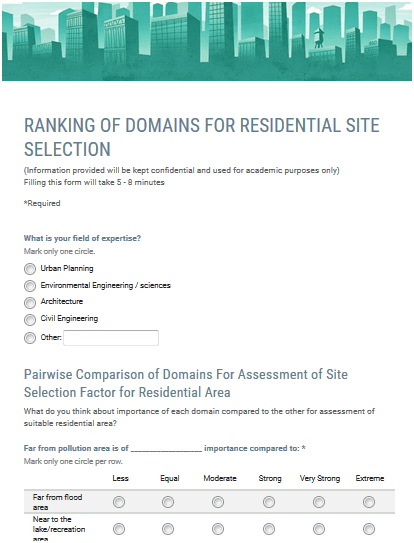 Dulu sempat mengambil mata kuliah Decision Support System (DSS) dan memperoleh materi khusus AHP dan sekarang ternyata “butuh lagi”. Ketika membuka lagi folder-folder lama dan ternyata masih ada. Sayang softwarenya tidak bisa diinstal di laptop saya karena versi yang sekarang windows 64 bit. Untung ada yang “share” program aplikasi tersebut di internet, ya sudah saya “pinjam”.
Dulu sempat mengambil mata kuliah Decision Support System (DSS) dan memperoleh materi khusus AHP dan sekarang ternyata “butuh lagi”. Ketika membuka lagi folder-folder lama dan ternyata masih ada. Sayang softwarenya tidak bisa diinstal di laptop saya karena versi yang sekarang windows 64 bit. Untung ada yang “share” program aplikasi tersebut di internet, ya sudah saya “pinjam”.