Jika Natural Language Toolkit (NLTK) sudah diinstal, di dalamnya terdapat pula corpus yang berisi sampel data maupun kamus khusus, salah satunya adalah stopwords. Jalankan kode berikut ini dengan Python. Buka IDLE dan masukan instuksi berikut, simpan dan RUN.
import nltk
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
stop_words=set(stopwords.words(“english”))
print(stop_words)
Seperti biasa kode program mengimpor NLTK. Selain itu pada corpus diimpor juga stopwords. Berikutnya mengimpor word_tokenize dari tokenize pada NLTK. Kode terakhir adalah menampilkan stop words dalam bahasa Inggris. Sayangnya ketika mengganti “english” dengan “indonesia”, tidak ditemukan stop words dalam bahasa Indonesia. Kalau begitu kita coba dengan bahasa Inggris. Berikut hasil runningnya:
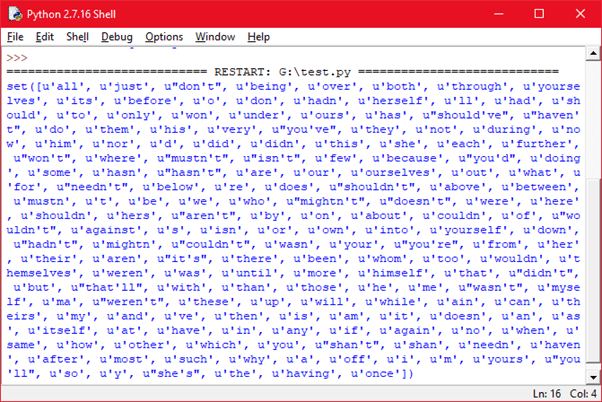
Kata-kata tersebut adalah stopword, yaitu kata yang tidak menjadi fokus search engine karena terlalu sering muncul seperti saya, kamu, dia, tatkala, dan lain-lain. Hanya saja dari corpus (berkas) NLTK untuk bahasa Inggris saja hasil donlot via nltk.download() (lihat post terdahulu).
Sastrawi Sebagai Corpus Berbahasa Indonesia
Corpus sastrawi dapat dilihat pada link resminya berikut ini. Jalankan pip install Sastrawi pada command prompt. Tunggu beberapa saat karena mengunduh file-file pendukung yang cukup besar.
Untuk mengujinya, jalankan kode berikut ini via IDLE python.
from Sastrawi.StopWordRemover.StopWordRemoverFactory import StopWordRemoverFactory
stop_factory = StopWordRemoverFactory()
more_stopword = [‘dengan’, ‘ia’,’bahwa’,’oleh’]
data = stop_factory.get_stop_words()+more_stopword
stopword = stop_factory.create_stop_word_remover()
print(data)
Perhatikan “more_stopword” bisa digunakan untuk menambah stopword baru jika dirasa Sastrawi kurang stopword-nya dan perlu ditambah misalnya “dengan”, “ia”, “bahwa”, “oleh”, atau lainnya.
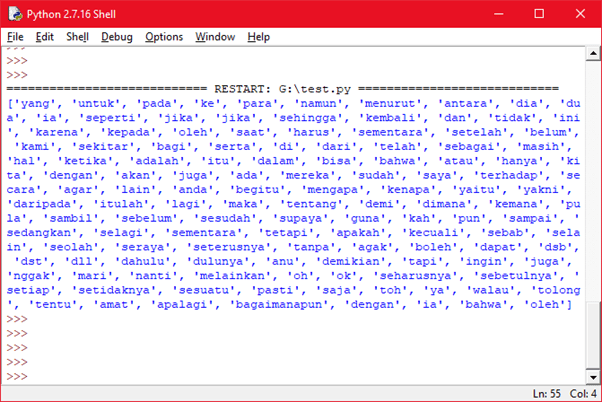
Perhatikan dalam bahasa Indonesia, stopword selain kata ganti adalah penunjuk, sapaan, dan sebagainya. Sekian, semoga bermanfaat.
