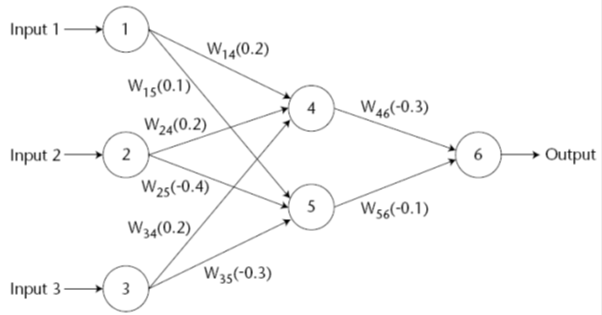
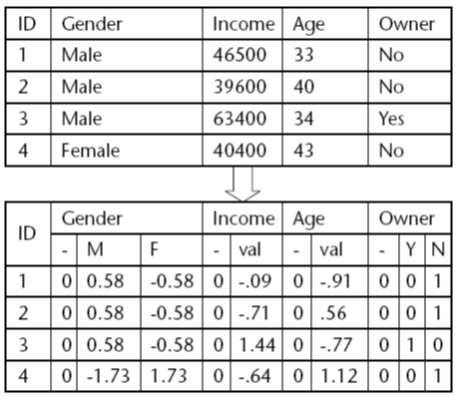
Oleh: Rahmadya Trias H., ST, MKom.
Clustering adalah mengumpulkan sederetan data sejenis dalam satu cluster yang membedakan dengan cluster lainnya. Ciri yang mendasari pengelompokkan berdasarkan variabel tertentu dari database. Tentu saja makin banyak variabel yang mendasari pengelompokkan, proses pengklasteran makin rumit.
11.1. Pengenalan Microsoft Clustering
Microsoft clustering bekerja menemukan peng-groupan secara alami dari data yang kita meliki dengan cara mencari variabel-variabel tersembunyi. Manfaat utama dari clustering, misalnya jika kita akan memasarkan suatu produk, katakanlah mobil, maka tentu saja kita akan mencari data-data dalam suatu cluster yang memiliki ciri-ciri tidak memiliki mobil tetapi berpenghasilan di atas rata-rata.
Ada dua metode yang digunakan untuk pengklusteran yaitu K-Means dan Expectation Maximization (EM). K-Means melakukan pengklusteran dengan menghitung jarak (distance) rata-rata satu kluster dengan kluster lainnya. Pusat kluster bergeser sesuai dengan jarak rata-ratanya. Metode ini sering diistilahkan dengan Hard clustering karena satu objek tepat hanya menjadi anggota suatu kluster.
Berbeda dengan K-Means, EM cenderung menggunakan probabilitas dalam pengklusteran. Kurva yang dipakai adalah kurva Bell. Karena antara satu kluster dengan kluster lainnya bisa overlapping, maka metode ini sering diistilahkan dengan nama Soft Clustering.
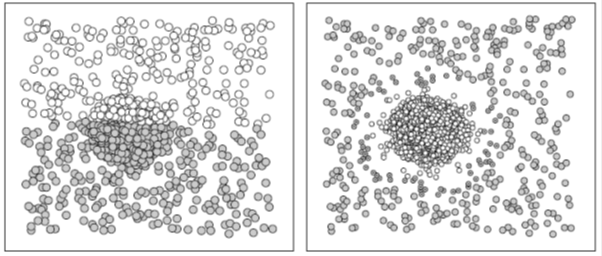
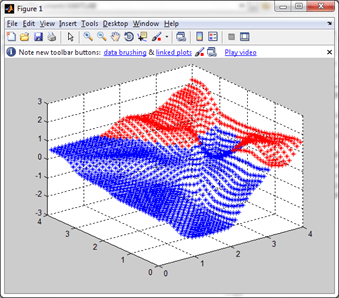
Gambar 11.1. Metode K-Means (Kiri) dan Metode EM (Kanan)
11.2. Pemodelan Clustering
Pemodelan diperlukan untuk melakukan clustering pada data set milik kita. Variabel yang menjadi basis klusterifikasi harus kita pilih setepat mungkin. Klusterifikasi dimanfaatkan untuk menganalisis, misalnya analisa terhadap kerugian penjualan. Sebaiknya model yang kita buat lebih dari satu untuk menghindari bias.
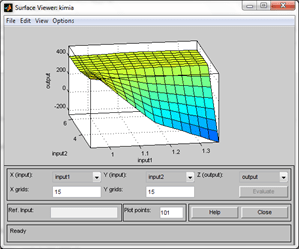
Gambar 11.2. Model Kluster
11.3. Klusterifikasi dengan Microsoft BI Development
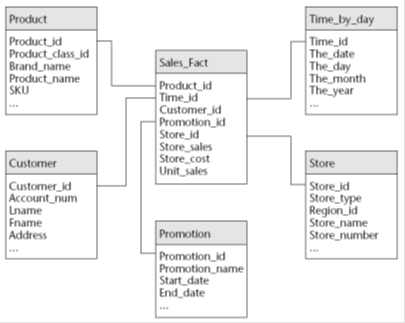
Akhirnya kita mencoba melakukan klusterifikasi dengan aplikasi dari microsoft, yaitu Microsoft Clustering. Langkah pembuatan project sama dengan bab-bab terdahulu hanya saat memodelkan Mining Structure kita memilih teknik yang digunakan dengan teknik Microsoft Clustering. Key, Input dan Predict agak berbeda. Pada Clustering, kita memiliki Input dan Predict dengan variabel (Field) yang sama.
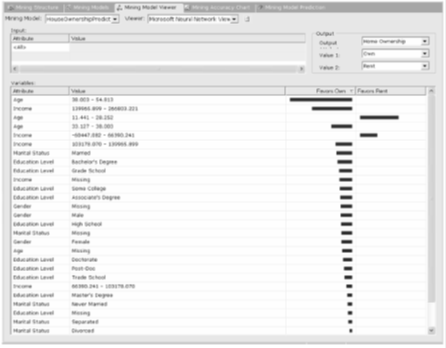
Dan yang terpenting adalah kemampuan membaca hasil pengolahan Microsoft BI Development yang terdiri dari view-view: Cluster Diagram, Cluster Characteristic dan Cluster Discrimination.
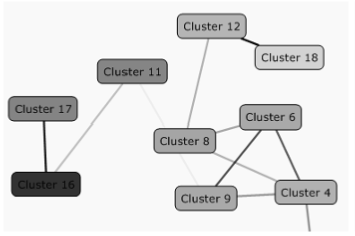
Gambar 11.3. Cluster Diagram
Coba Sendiri dengan Data “Movie Click” !!! Klasifikan berdasarkan Gender, Jenis Kelamin dan Status Perkawinan.





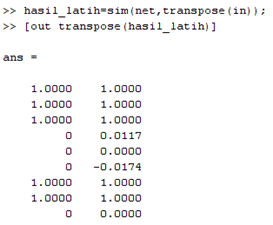
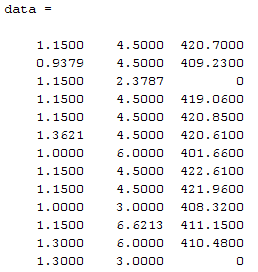
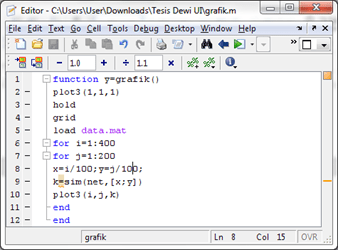
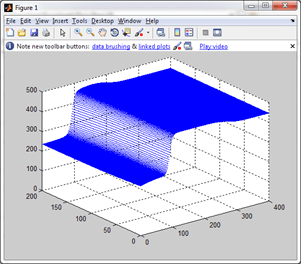
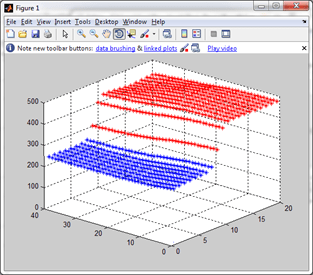



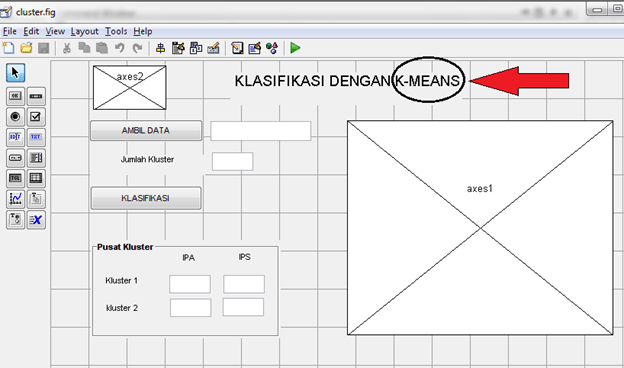

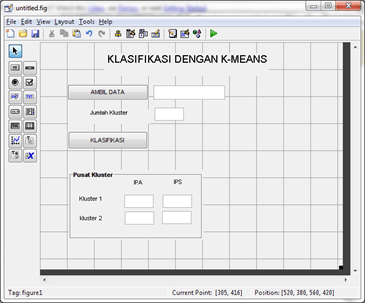
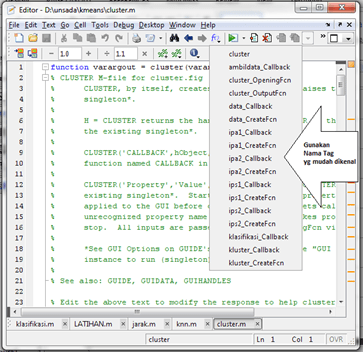
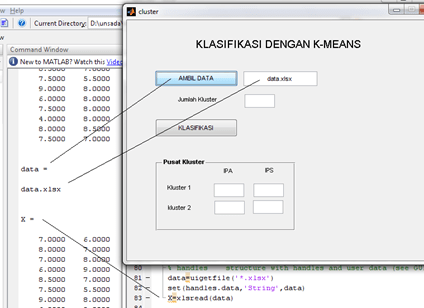
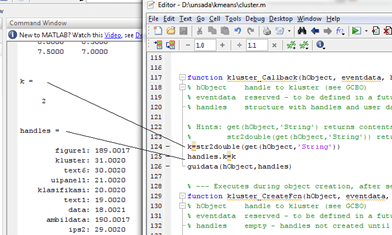
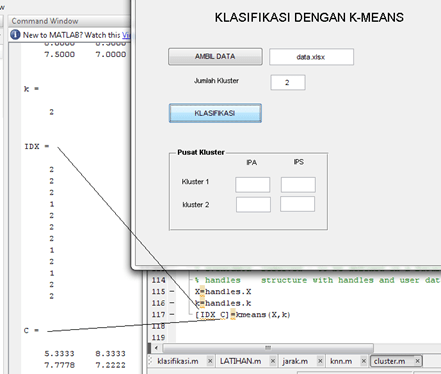
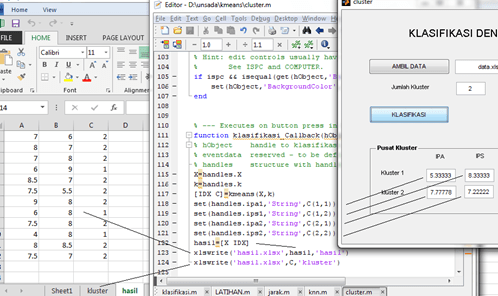
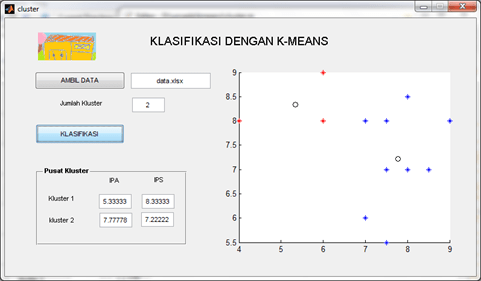
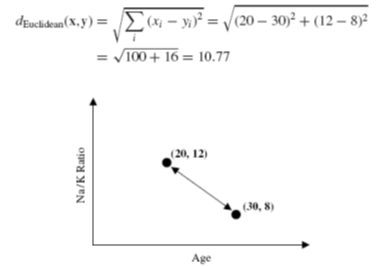
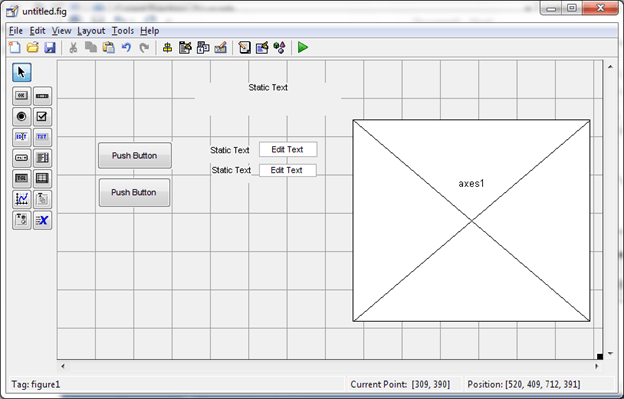
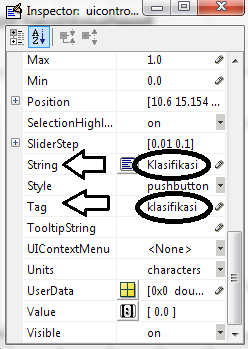

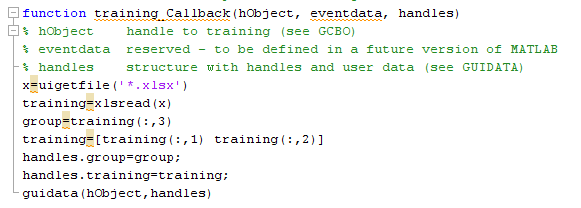
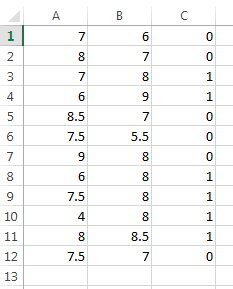
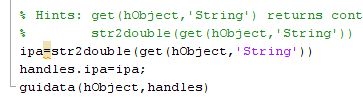
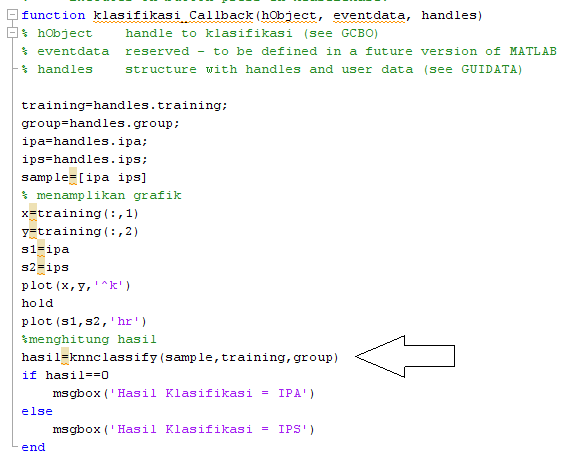
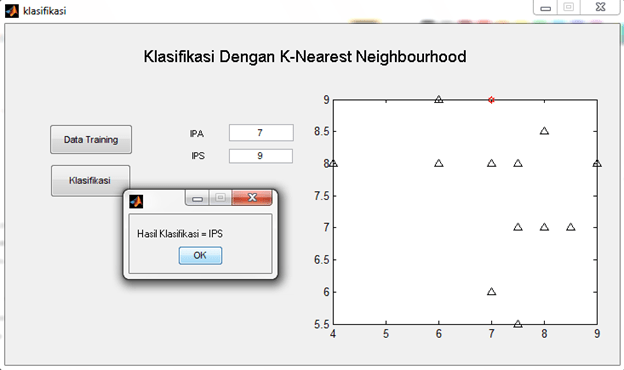
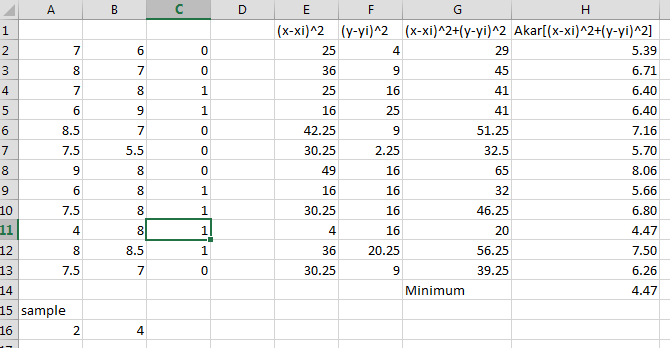






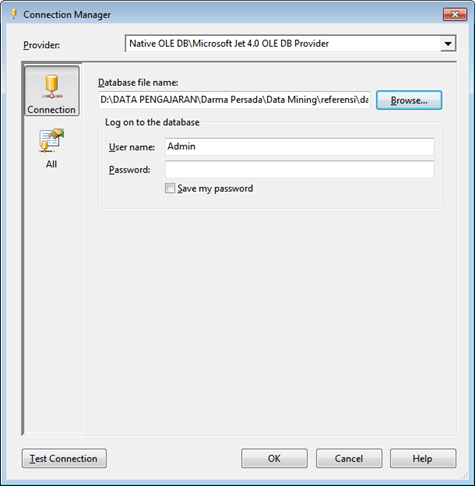

 “Process Mining …” untuk memproses Data Mining. Klik “Yes” dilanjutkan dengan proses Mining. Tunggu hingga selesai.
“Process Mining …” untuk memproses Data Mining. Klik “Yes” dilanjutkan dengan proses Mining. Tunggu hingga selesai.
