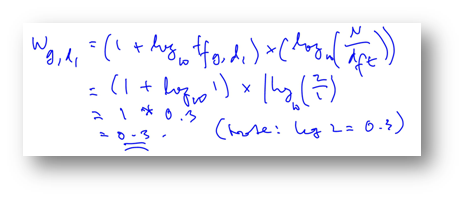Lama tidak ngeblog tidak enak juga. Banyak hal-hal yang bisa saya sharing ke orang lain yang siapa tahu membutuhkan informasi tertentu yang saya miliki. Terkadang sedih juga membaca komentar-komentar di tulisan saya yang mengatakan “sotoy”, jangan asal tulis, dan lain-lain, bahkan ada yang mengatakan saya asal “copas”. Tapi sesuai dengan prinsip situs saya “just a Little Kindness”, saya coba untuk memberi kebaikan walau hanya sedikit.
Saya dulu pernah membuat tulisan mengenai akses database dengan Visual Query Builder, dan banyak yang tidak puas dengan koneksi seperti itu. Lama saya tidak mencoba “ngoprek” hal itu karena belum merasa perlu karena akses dapat dilakukan dengan menggunakan excel atau notepad. Untuk data kecil sebenarnya tidak ada masalah, tetapi jika data yang berukuran besar, Excel tentu saja tidak sanggup menanganinya. Saya pernah mencoba mengkonversi file CSV ke dalam Access kemudian saya kembalikan lagi menjadi TXT untuk diolah Matlab dalam rangka Data Mining (waktu itu tugas Text Mining dari dosen saya). Tetapi tentu saja tidak efektif. Perlu dilakukan koneksi data langsung dari DBMS ke Matlab.
Berawal dari Hibah Penelitian dari Dikti (Hibah Bersaing) dimana tahun ketiga saya harus mengkoneksikan GIS desktop dengan Web GIS, mau tidak mau saya membutuhkan sistem basis data. Terpaksa saya harus mengkoneksikannya langsung. Cari paling mudah adalah lewat mekanisme Open Data Base Connectivity (ODBC) yang tersedia di Windows. ODBC ini memiliki keunggulan dalam hal fleksibilitas, dimana jika kita sudah merakit ODBC maka program yang telah dibuat dengan Matlab tidak tergantung dengan software DBMS yang telah ada karena koneksi antara program dengan database lewat ODBC, beda jika kita mengkoneksikan Matlab dengan Software DBMS langsung (Access, MysQL, Oracle, PostgreSQL, dll). Jika kita mengganti software DBMS, kita harus mengeset lagi program yang telah kita buat. Dengan DBMS, jika kita akan mengganti Software DBMS, tinggal menghubungkan Software DBMS dengan ODBC lagi, termasuk user dan password jika diperlukan.
Untuk membuat ODBC Anda dapat membaca literatur yang membahas tata caranya. Yang penting Anda ketahui adalah Windows yang Anda miliki, 64 Bit atau 32 Bit. Jika 32 bit sepertinya tidak ada masalah. Nah, masalah muncul jika windows yang digunakan versi 64 bit, karena ODBC yang digunakan harus mundur yang 32 bit karena software DBMS kebanyakan masih berversi 32 bit. Untuk windows 8 dengan searching di control panel, akan ditemukan dua pilihan, ODBC 32 bit atau ODBC 64 bit. Sedangkan jika Windows 7 64 bit, maka Anda harus masuk ke folder SysWOT di C: dan menjalankan file odbcad32.exe. Jika Anda memaksa menggunakan ODBC 64 bit padahal program yang Anda gunakan versi 32 bit, akan memunculkan pesan kesalahan saat melakukan koneksi Matlab dengan ODBC (mismatch .. bla bla).
Untuk menghubungkan Matlab dengan ODBC dapat Anda lakukan dengan langkah sebagai berikut. Misalkan Anda telah memiliki ODBC dari database Anda, misalnya bernama “lokasi” dengan user ID “user” dan password “123”, lakukan koneksi dengan instruksi:
Conn=database(‘lokasi’,’user’,’123)
Cukup sederhana. Cek koneksi dengan instruksi isconnection(Conn). Jika jawabannya 1 maka koneksi berjalan dengan baik, sebaliknya jika jawabannya nol, maka Anda harus mengecek error-nya. Ketik saja Conn.Message untuk melihat instruksi kesalahannya. Jika Database telah terisi, Anda dapat mengecek dengan instruksi sql “select”.
Results=fetch(conn,’select * from lokasi’)
Misalnya tabel yang ada di database kita lokasi. Anda akan menerima data dari database dengan nama Results yang siap Anda olah dengan Matlab. Bagaimana dengan input data ke database? Mudah saja, gunakan instruksi insert. Hanya saja sedikit rumit karena ada tata cara penulisan nama field yang ada di tabel. Misal ada dua field yaitu x dan y. Kemudian akan saya isi data dengan x=1 dan y=2, maka gunakan instruksi sebagai berikut:
Insert(Conn,’lokasi’,[{‘x’} {‘y’}],[1 2])
Jika tidak ada pesan kesalahan sintax di Matlab, cek apakah data sudah masuk di database Anda. Selamat mencoba.