Oiya, sudah daftar Sinta kan? (Untuk yang belum). Banyak yang protes karena Sinta menggunakan Google scholar sebagai salah satu faktor perhitungan Sinta selain Scopus. Salah satunya adalah karena Google scholar serampangan memasukan suatu tulisan/artikel ke akun Google scholar kita. Namun karena Google scholar metodenya self assesment, ada baiknya kita menghapus dan mendaftarkan tulisan-tulisan kita secara mandiri. Postingan ini terinspirasi dari tulisan rekan saya waktu mengajar di satu kampus di jalan Fatmawati dulu (lihat di sini).
Setelah login di google scholar, masuk ke profile kita. Di bagian atas kiri ada simbol “wisuda” yang artinya profile kita. Klik untuk masuk ke dalam dan melakukan manajemen artikel milik kita.
Pilihlah tulisan-tulisan yang bukan tulisan kita. Kemudian tekan “DELETE” agar dibuang dari daftar tulisan kita. Misalnya “klasifikasi lovebird ..” (hmm sejak kapan saya nulis klasifikasi burung bercinta).
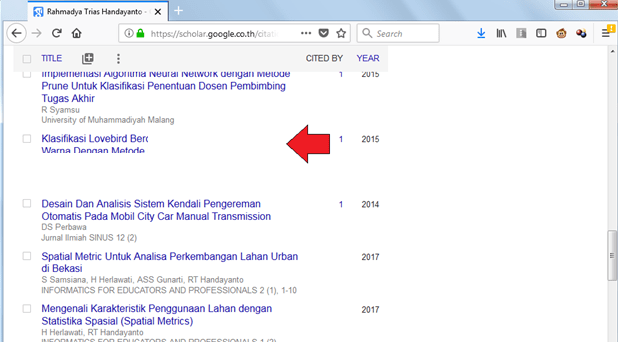
Kemudian akan muncul informasi jurnal tersebut. Berikutnya tinggal menekan simbol “tempat sampah”. Artinya kita membuang tulisan tersebut dari daftar tulisan kita.

Oiya, jangan sedih. Kan bukan tulisan kita. Tapi lama-lama repot juga kalo google “nyepam” terus suatu tulisan ke akun Google scholar kita, capek juga sih menghapusnya. Untungnya bobot Google scholar jauh di bawah Scopus yang memang “screening”nya bagus. Hanya saja masih jarang dosen-dosen di tanah air yang sudah punya ID scopus.
Berikut kalau ingin menambahkan artikel, tinggal tekan simbol “+”. Ada dua pilihan tambah artikel (manual atau otomatis). Untuk yang otomatis searching nama kita di kolom “searching” lalu tekan simbol kaca pembesar. Sementara kalau yang manual tinggal isi informasi tulisannya.

Oiya, jangan asal masukin tulisan orang. Semoga postingan ini bermanfaat.
