Optimalisasi (optimization) merupakan usaha menemukan hasil maksimal (maximization) atau minimal (minimization), tergantung dari kasus yang ingin dioptimalkan. Besar atau kecilnya hasil optimalisasi berdasarkan hitungan sebuah fungsi yang dikenal dengan nama fungsi objective (terkadang untuk bidang RS-GIS lebih disukai fungsi kriteria – criteria function). Secara algoritmik fungsi objektif dikenal dengan istilah fitness function. Selain itu ada batasan-batasan (constraint) tertentu dalam mencapai harga optimal dari objective tersebut.
Deterministik atau Stochastic
Untuk mencapai nilai minimal/maximal fungsi objective beragam metode sudah dikembangkan. Secara garis besar metode-metode yang ada dibagi menjadi deterministic dan stochastic. Deterministic merupakan metode lama dengan bantuan gradient, khusus untuk fungsi-fungsi kontinyu. Di sekolah dulu kita pernah menghitung nilai minimal sebuah fungsi dengan menurunkan dan menyamakannya dengan nol (dikenal dengan metode Newton). Metode stochastic muncul ketika yang akan dioptimalisasi bukan fungsi kontinyu, tidak konvergen, tidak bisa diturunkan dan aspek-aspek analitis lainnya. Beberapa literatur-literatur terkini menyebut metode stochastic dengan sebutan baru yang dikenal dengan nama metaheuristic. Pertama kali istilah ini diperkenalkan oleh Fred Glover di tahun 1986. Dalam proses pencarian, ada dua aspek yang ingin dikejar, diversifikasi (focus ke global optimal secepatnya, dikenal dengan istilah exploration), dan aspek lokalitas untuk mencari yang benar-benar optimal di suatu wilayah tertentu (dikenal dengan sebutan exploitation). Dua aspek tersebut (exploration dan exploitation) harus dikompromikan untuk menghasilkan metode heuristik yang tepat.
Metaheuristic
Metaheuristic merupakan gabungan kata Meta dan Heuristic. Heuristic artinya mencari jawaban dengan cara trial & error sementara meta berarti melampaui atau tingkat yang lebih dari. Jadi metaheuristic tidak hanya mencari jawaban dengan coba-coba saja melainkan dengan bantuan atau arahan dari faktor-faktor lain. Faktor-faktor itulah yang membuat banyaknya variasi dari metaheuristic ini. Algoritma-algoritma metaheuristic yang banyak dikenal dan diterapkan antara lain:
1. Simulated Annealing
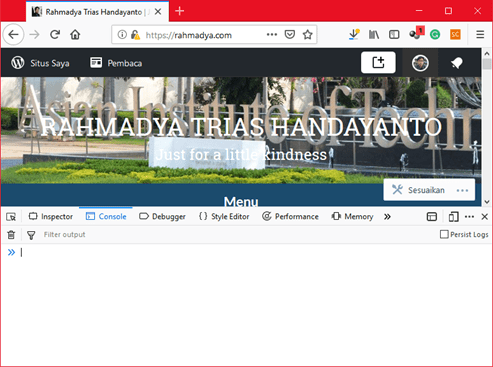
Metode ini meniru proses pendinginan baja yang dicor. Fungsi yang digunakan adalah fungsi eksponensial:

dengan kB konstanta Boltzmann dan T adalah suhu (kelvin). E merupakan energi yang perubahannya setara dengan perubahan fungsi objektif:

Dengan gamma konstanta yang biasanya berharga 1 untuk penyederhanaan.
2. Genetic Algorithm
Algoritma genetika diperkenalkan oleh John Holland di tahun 60-an. Metode ini meniru sifat alami evolusi dimana yang adaptif adalah yang optimal. Setelah fungsi objektif ditentukan, maka serentetan algoritma bekerja mencari nilai optimal fungsi tersebut. Keunikan metode ini adalah mengkombinasikan antar nilai sementara yang diperoleh dengan kawin silang (crossover) dan mutasi. Awalnya nilai-nilai tersebut harus di-encode menjadi biner agar beberapa bitnya bisa disalingtukarkan dengan nilai lainnya dan juga untuk mutasi. Namun saat ini banyak dikembangkan metode tanpa mengkonversi bilangan tersebut menjadi biner. Pemilihannya pun (selection) berdasarkan bentuk peluang (roulette wheel) dimana nilai yang memiliki harga fitness besar akan memiliki peluang yang besar pula.
3. Differential Evolution
Differential Evolution (DE) merupakan metode pengembangan dari algoritma genetika yang diperkenalkan oleh R. Storn dan K. Price di tahun 96-97. Jika pada algoritma genetika kromosom dalam bentuk biner, DE menggunakan vektor sebagai kromosom.

Mutasi, crossover, dan selection sedikit lebih rumit dari algoritma genetika. Secara detail silahkan buka makalah aslinya.
4. Ant Colony Optimization
Metode ini meniru prinsip semut dalam usaha mencari makanan. Semut menggunakan senyawa kimia bernama pheromone ketika berjalan. Jalur yang banyak dilalui semut akan memiliki konsentrasi pheromone yang lebih banyak. Penurunan fungsi konsentarasi pheronome adalah berikut ini.
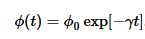
Jika ada jalur yang memiliki konsentrasi pheromone melebihi jalur yang lain maka jalur ini dikatakan favorit dan umpan balik positif berlaku di sini dan lama kelamaan berlaku kondisi “self-organized”.
5. Bee Algorithms
Sesuai dengan namanya, algoritma ini mengikuti pergerakan lebah dalam mencari sumber materi pembuatan madu. Mirip dengan semut, tawon juga mengeluarkan pheromone yang disertai dengan tarian “waggle dance”. Bee algorithm dikembangkan oleh Moritz and Southwick 1992, Craig A Tovey, Xin-She Yang, dan lain-lain.
Turunan algoritma ini cukup banyak, antara lain: honeybee algorithm, artificial bee colony, bee algorithm, virtual bee algorithm, dan honyebee mating algorithm. Banyak dikembangkan untuk optimasi posisi tertentu dalam suatu jaringan (misal server).
6. Particle Swarm Optimization
Particle Swarm Optimization (PSO) meniru pergerakan sekelompok binatang (ikan, burung, dll) dalam mencari makanan. Berbeda dengan algoritma genetika yang berganti individu (punah, baru, dan mutasi), PSO menjaga jumlah kelompok individu dan hanya perubahan posisi saja. Algoritma ini dikembangkan oleh Kennedy dan Eberhart (lihat pos yang lalu).

PSO memiliki dua nilai sebagai patokan pergerakan kerumunan: local optima dan global optima. Local optima merupakan nilai terbaik tiap individu di masa lampau (biasanya hanya sebelumnya saja) sementara global optima adalah nilai terbaik di kerumunan tersebut. Bobot antara keduanya menggambarkan karakter PSO apakah selfish atau sosialis. Selain itu langkah pergerakan menentukan karakter PSO apakah lebih tinggi daya jelajah atau lebih sempit tetapi berkualitas.
7. Tabu Search
Tabu search dikembangkan oleh Fred Glover di tahun 1970 (tapi baru dipublikasikan dalam bentuk buku di tahun 1997-an). Berbeda dengan PSO yang menggunakan data lampau satu atau dua iterasi sebelumnya, tabu search merekam seluruh data yang lampau. Manfaatnya adalah mengurangi jumlah komputasi karena data yang lama sudah ada dan tidak perlu dihitung ulang. Algoritma ini masih banyak peluang untuk dikembangkan dengan cara hybrid dengan metode lain.
8. Harmony Search
Ide dari algoritma ini adalah musik. Metode ini diperkenalkan oleh Z.W. Geem di tahun 2001. Prinsipnya adalah di tiap iterasi ada tiga jenis pencarian antara lain berdasarkan: daftar irama yang sudah terkenal dimainkan, mirim dengan yang ada dengan beberapa penekanan (pitching), dan merancang komposisi yang benar-benar baru. Pitch adjustment mengikuti pendekatan Markov Chain:
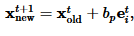
dengan b merupakan bandwidth yang mengontrol pitch adjustmant.
9. Firefly Algorithm
Metode ini dikembangkan oleh Xin-She Yang pada tahun 2008 dengan mendasari prinsip kerjanya dengan seekor kunang-kunang. Fakta unik kunang-kunang antara lain:
-
Kunang-kunang tidak memiliki jenis kelamin, interaksi dengan kunang-kunang lain tidak berdasarkan jenis kelamin.
-
Ketertarikan berdasarkan kecerahan dari cahaya. Kunang-kunang yang lebih bercahaya, lebih menarik kunang-kunang lain yang kurang bercahaya.
Kecerahan berdasarkan lanskap dari fungsi objektif-nya:
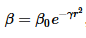
dengan beta merupakan tingkat kecerahan. Pergerakan kunang-kunang i mengikuti ketertarikan dengan kunang-kunang lain, j ditentukan dengan persamaan:

10 Advanced Method
Beberapa metode masuk kategori terkini dan sangat advanced, misalnya Cuckoo Search (CS) yang akan dibahas di lain waktu bersama-sama metode-metode terkini lainnya. Diyakini metode-metode terbaru tersebut lebih baik dari yang saat ini banyak digunakan (algoritma genetika, dan PSO). Sekian, semoga bisa membantu bagi yang tertarik dengan metode-metode optimasi metaheuristik.