[inf.retrievalt.komputer|lab.software|pert.9]
Salah satu langkah perolehan informasi yang penting adalah pembuatan indeks. Indeks merupakan salah satu kunci untuk pencarian informasi. Untuk menghasilkan pengindeks yang baik perlu menggunakan teknik-teknik yang ada pada pemrosesan teks. Postingan kali ini bermaksud mengetahui cara pembuatan indeks dengan file yang diambil dari microsoft word.
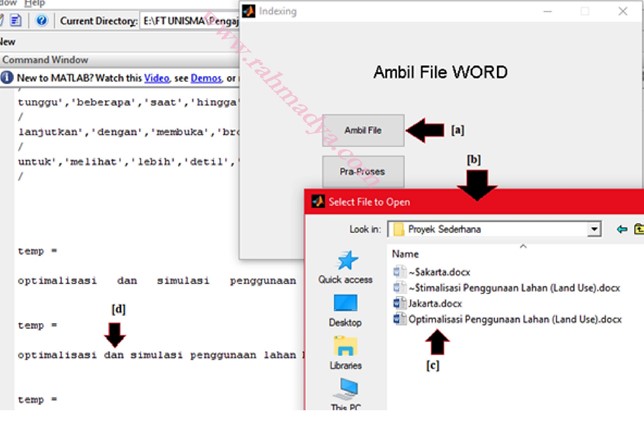
Mengambil File Ms Word
Banyak informasi yang memberikan cara bagaimana mengambil file word agar bisa diproses lebih lanjut pada Matlab. Biasanya file yang langsung bisa digunakan adalah file berekstensi txt, namun karena banyaknya file berformat DOC atau DOCX maka perlu mengetahui cara pengambilan file bertipe itu agar bisa diolah lebih lanjut pada Matlab. Agar lebih nyaman, ada baiknya membuat Graphic User Interface (GUI) agar lebih mudah digunakan atau disimpan agar mudah digunakan nantinya.
Masuk ke callback Ambil File dan isikan kode berikut menggunakan uigetfile yang mengeluarkan form ambil file. Akhiri dengan membuat variabel agar bisa digunakan nantinya lewat mekanisme handles.
Sementara pada callback Pra-Proses diisi dengan kode-kode berikut dimulai dari mengambil data dari word:
Variabel “file” merupakan string yang diambil dari instruksi “uigetfile” pada pushbutton sebelumnya yang kemudian disimpan dalam variabel sometext. (Lihat penjelasannya di buku Text Mining dengan Matlab karya Bachs).
Variabel “temp” berisi hasil pemrosesan yang dimulai dari lower untuk mengecilkan seluruh huruf hingga mengkonversi string word tersebut menjadi cell dalam variabel wordsofverses. Hasilnya kira-kira sebagai berikut. Semoga bermanfaat.