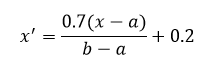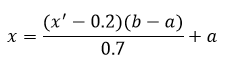Walaupun kecerdasan buatan (Artificial Intelligent), Machine Learning, dan Deep Learning berbeda tetapi satu sama lain berhubungan. Deep Learning, yang dimotori oleh Jaringan Syaraf Tiruan lapis banyak, adalah salah satu jenis Machine Learning. Machine Learning itu sendiri adalah salah satu jenis dari kecerdasan buatan.
Machine Learning yang merupakan proses induksi ada tiga jenis. Penerapannya beragam, dari pengenalan gambar, pengenalan suara, pengenalan bahasa, dan lain-lain. Berikut ini jenis-jenisnya:
1. Suppervised Learning
Kebanyakan Machine Learning diterapkan pada jenis ini. Alur prosesnya antara lain: 1) memilih basis pengetahuan untuk menyelesaikan problem. Bandingkan jawaban dengan hasil sesungguhnya, 2) jika jawaban salah, modifikasi basis pengetahuan. Langkah 1) dan 2) diulangi terus hingga jawaban mirip dengan hasil sesungguhnya. Basis pengetahuan itu sendiri diistilahkan dengan Model. Jika disimpulkan suppervised learning memiliki pola:
{ input, correct output }
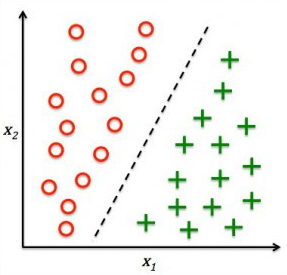
Dua tipa aplikasi terkenal dari machine learning jenis ini adalah klasifikasi dan regresi. Jika klasifikasi membagi dalam kelas-kelas yang diskrit, regresi bukan dalam kelas melainkan harga tertentu. Masalah yang sering dijumpai adalah Overfitting, yaitu adanya anomali dimana akurasi training yang bagus ketika diaplikasikan dalam kondisi real jatuh. Hal ini terjadi karena proses training tidak mampu menghasilkan generalisasi dari data dalam artian terlalu kaku mengikuti data training.
Namun terkadang klasifikasi dan regresi bekerja sama membentuk sistem seperti support vector regressin, juga neural network regression. Biasanya mengklasifikasi dulu baru meregresi hasil pastinya.
2. Unsuppervised Learning
Berbeda dengan suppervised learning, pada unsuppervised learning tidak diperlukan hasil sesungguhnya (correct output). Pada mulanya hal ini sulit dimengerti, tetapi dapat diterapkan untuk kasus yang memang tidak ada hasil sesungguhnya. Polanya adalah sebagai berikut:
{ input }
Salah satu representasi dari aplikasi unsuppervised learning adalah pengklusteran (clustering) dimana data training diinvestigasi karakteristiknya sebelum dikategorisasi.

3. Reinforcement Learning
Machine learning ini memasukan aspek optimasi dalam pembelajarannya. Jadi selain input, beberapa output dengan grade/kualitasnya digunakan untuk training. Biasanya diterapkan dalam bidang kontrol dan game plays.
{ input, some output, grade for this output }
Clustering dan Classification
Dua aplikasi tersebut serupa tapi tak sama. Untuk jelasnya kita ambil kasus pembagian kelas siswa menjadi IPA dan IPS. Jika kita memiliki data dengan label (output) IPA jika nilai IPA lebih besar dari IPS dan begitu pula sebaliknya kelas IPS jika nilai IPS lebih besar dari IPA, maka karena proses learningnya memiliki target/label/output, maka masuk kategori suppervised learning dan otomatis masuk domain klasifikasi. Namun jika kebanyakan guru IPA-nya “killer”, maka dikhawatirkan seluruh siswa masuk kelas IPS. Disinilah peran pengklusteran. Di awal kita tidak memiliki output tertentu, biarlah data yang membagi menjadi dua, baru diselidiki mana kelompok kelas IPA mana IPS. Tetapi waspadalah, jangan sampai kita membagi dua kategori (cluster) yang salah, bukannya IPA dan IPS malah kelas IPA dan IPS yang bagus dan kelas IPA dan IPS yang jelek, alias membagi siswa menjadi dua kategori siswa pintar dan siswa yang perlu lebih giat belajar (kata Kho Ping Hoo tidak ada orang pintar dan bodoh, tetapi tahu dan tidak tahu). Semoga bermanfaat.