Karena kelemahan scoring dengan Jaccard adalah tidak disertakannya frekuensi suatu term dalam suatu dokumen, maka diperlukan skoring dengan kombinasi dari Term Frequency dan Invers Document Frequency atau disingkat tf-idf.
Term Frequency (tf)
Tf menyatakan jumlah berapa banyak keberadaan suatu term dalam satu dokumen dan kemudian dilogaritmikan agar mengurangi besarnya bilangan, dimana logaritmik suatu bilangan akan mengurangi digit jumlah, misalnya 1000 dengan log (1000) hanya menghasilkan angka tiga. Rumus Tf adalah sebagai berikut:

Jadi jika suatu term terdapat dalam suatu dokumen sebanyak 5 kali maka diperoleh bobot = 1 + log (5) =1.699. Tetapi jika term tidak terdapat dalam dokumen tersebut, bobotnya adalah nol.
Inverse Document Frequency (Idf)
Terkadang suatu term muncul di hampir sebagian besar dokumen mengakibatkan proses pencarian term unik terganggu. Idf berfungsi mengurangi bobot suatu term jika kemunculannya banyak tersebar di seluruh koleksi dokumen kita. Rumusnya adalah dengan inverse document frequency. Document frequency adalah seberapa banyak suatu term muncul di seluruh document yang diselidiki.

Sehingga bobot akhir suatu term adalah dengan mengalikan keduanya yaitu tf x idf. Berikut ini kita mengambil contoh suatu kasus. Misalnya kita memiliki vocabulary sebagai berikut:
girl, cat, assignment, exam, peace
Dan kita diminta merangking suatu query: “girl exam” terhadap dua dokumen di bawah ini:
Document 1 : exam peace cat peace peace girl
Document 2 : assignment exam
Langkah pertama adalah kita membuat tabel dengan term urut abjad (lexicography) dan mengisi nilai bobotnya untuk document 1 dan document 2. Setelah itu menghitung score(q,d1) dan score(q,d2) yang menyatakan berturut-turut skor rangking query terhadap dokumen 1 dan dokumen 2.

Bagaimana angka-angka tf-idf tersebut muncul? Jawabannya adalah dengan menghitung bobotnya lewat rumus tf x idf di atas. Perhatikan exam dan girl yang merupakan query (ditandai kotak hitam). Tampak untuk dokumen 1 score-nya adalah 0 + 0.3 = 0.3, sementara untuk dokumen 2 score-nya 0 + 0 = 0, jadi jika diranking, yang pertama adalah dokumen 1 dan berikutnya dokumen 2. Bagaimana menghitung bobot Wt,d untuk girl pada document 2 di atas yang diperoleh hasil 0.3? berikut ini jalan lengkapnya:
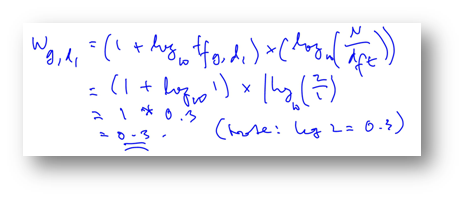
Coba hitung bobot di kolom yang lainnya siapa tahu saya salah hitung. Berikut video tutorialnya:



