Genetic Algorithms (GAs) digunakan untuk mencari nilai optimal (maksimum atau minimum) suatu fungsi. Fungsi itu dikenal dengan istilah fitness function, atau ada juga yang menyebutnya fungsi objektif. Sebelumnya optimasi dilakukan dengan cara matematis, kalau kita inget-inget lagi pelajaran SMA dengan menurunkan suatu persamaan dan disamadengankan dengan nol. Tetapi masalah muncul jika persamaan itu memiliki banyak nilai optimal, karena nilai optimal akan terjebak dalam lokal optimum. Contohnya adalah fungsi rastrigin dari Matlab yang memiliki banyak jebakan local minimum dan hanya ada satu global optimum (kayak tempat telor ya).

Ok, kita coba mengoptimasikan satu fungsi objektif dari penanya: y = 2*x(1)+3*x(2)+4*x(3)+4*x(4). Dengan constraint: 10<x(1)<20, 30<x(2)<40, 50<x(3)<60, 70<x(4)<80. Kayaknya susah. Sebelumnya, buat terlebih dahulu fungsinya di m-file. Praktisnya ketik saja edit fungsi jika kita mau membuat fungsi objektif itu bernama fungsi. Tekan “yes” jika ada pesan bahwa tidak ada m-file bernama “fungsi”. Berarti fungsi bernama fungsi itu tidak dimiliki oleh bahasa built-in bawan Matlab. Ketik fungsi y di atas di m-file editor yang baru saja terbuka.

Kok Cuma gitu? Ya iyalah, coba tes dengan x1, x2, x3, dan x4 berturut-turut 1,2,3, dan 4 di command window dengan mengetik y=fungsi([1 2 3 4]). Jawabannya harus 36 dan tidak ada pesan error. Oiya, ini harus benar, karena jika sampai sini tidak berhasil mengikuti ya dijamin ga bakal bisa terus ke algoritma genetik, tapi kalo hanya ingin membaca saja ya rapopo.

Seperti biasa, cara termudah mengoperasikan Matlab adalah dengan menggunakan toolbox yang tersedia. Untuk GAs, karena masuk dalam kategori optimization toolbox, gunakan fungsi optimtool di command window.
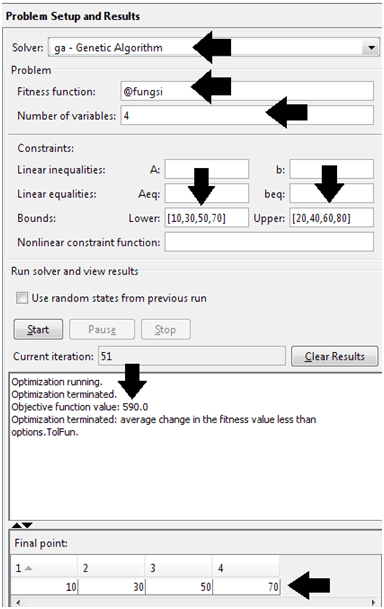
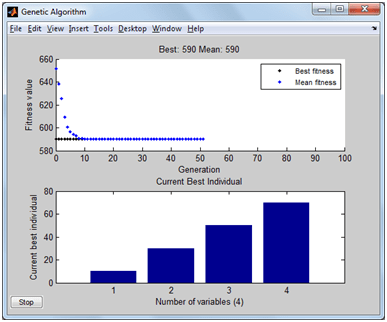
Setelah memilih jenis optimasinya (GAs), isi nama fungsi didahului @, jumlah variabel (4 variabel) dan perhatikan teknik mengisi bound yang sesuai persoalan. Di bagian kanan masih ada sebenarnya, tapi ga wajib. Centang pada isian plotting pada best fitness dan best individual sehingga ketika tombol “Start” ditekan, proses optimasi akan disertai pergerakan grafik yang interaktif. Oiya, tolong dicek benar atau tidak kalau itu nilai minimum. He he .. kayaknya ga perlu pake GAs saya juga bisa nebak, ya pasti batas bawah lah jawabannya (10, 30, 50, dan 70) soalnya fungsi kuadrat (membesar terus). Coba ganti fungsi yang lain.