[per.informasi|t.komputer|lab.soft|pert.5]
Jika pada pertemuan sebelumnya telah berhasil memisahkan kata-kata dalam suatu kalimat agar bisa menghitung jumlah katanya maka pada pertemuan kali ini akan mencoba memisahkan kata dari imbuhan (awalan dan akhiran) agar diperoleh kata dasarnya yang dikenal dengan istilah stemming/lematization. Proses ini sangat penting dalam perancangan mesin pencari (searching). Imbuhan merupakan ciri khas bahasa Indonesia yang memang berbeda sekali dengan bahasa Inggris. Coba rancang GUI berikut untuk melakukan proses stemming.

Imbuhan ada banyak misalnya me, meng, ber, per, -an, dan lain-lain. Untuk memisahkannya kita perlu memproses pencarian berdasarkan spasi dan titik (untuk akhiran). Jika tanpa spasi akan terjadi kesalahan karena sistem akan mereplace seluruh yang diduga awalan/akhiran walau terletak di tengah-tengah kata yang tentu saja salah.
- % menghilangkan “-an”
- y=regexprep(y,‘an+\s’,‘ ‘) % sebelum spasi
- y=regexprep(y,‘an+\.’,‘.’) % sebelum titik
- set(handles.edit1,‘String’,y)
Kode di atas bermaksud menghilangkan akhiran –an. Jika diinput kata “akhiran.” Akan dihasilkan kata dasarnya “akhir”. Ada dua deteksi yaitu sebelum spasi dan sebelum titik.
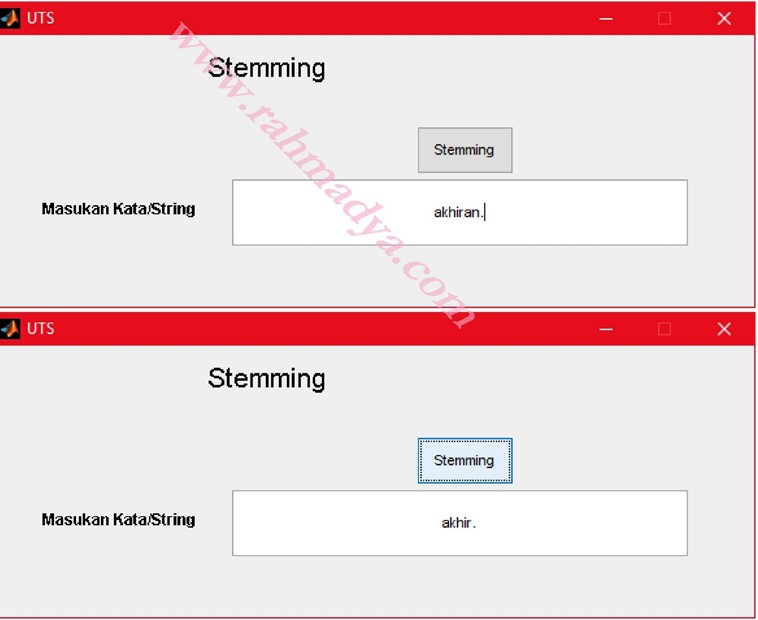
Logika sederhananya adalah mengganti “-an” tersebut dengan “blank”. Fungsi yang digunakan adalah regexprep yang mencari dan me-replace suatu string. Pertemuan berikutnya akan menggunakan proses perhitungan karakter tertentu, misalnya “makan”, tidak bisa jadi “mak” karena kurang dari 4 karakter. Selain itu perlu proses N-gram (dua, tiga, dst). Selamat mencoba, semoga UTS dapat dikerjakan dengan baik.
