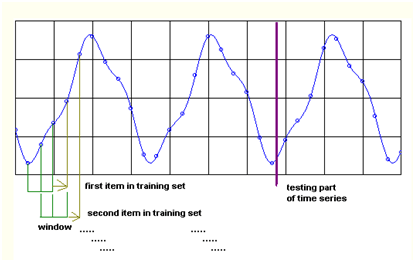
Postingan yang lalu sudah dibahas bagaimana mengelola Mat-file agar file hasil learning JST bisa dibuka kembali. Ketika dibuka dengan fungsi load pertama kali saya mencoba ternyata hanya variable hasil training yang muncul, misalnya variabel jst. Padahal kita ingin mengetahui bobot, bias, jumlah input, output dan neuronnya. Untuk mengetahui bagaimana melakukan training JST dapat Anda lihat postingan di menu JST. Sebenarnya kita sudah mengetahui jumlah neuron, bias dan bobot ketika kita melakukan proses pembelajaran, tetapi jika lupa mencatatnya maka kita dapat mengetahui paramater-parameter JST lewat langkah berikut ini.
Di sini kita mencoba menjawab pertanyaan berapa bobot, bias, dan jumlah neuron suatu JST? Seperti biasa buka Matlab dan masuk ke command window.
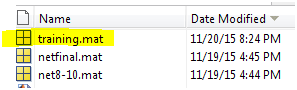
load training
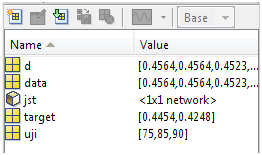
Di sini saya memanggil file mat bernama “training” yang telah saya simpan sebelumnya dengan fungsi write. Perhatikan di jendela workspace, tampak muncul variabel baru bernama jst. Variabel itulah yang akan kita cari jawabannya. Caranya sederhana, ketik saja nama variabelnya
jst
Maka Anda akan disuguhkan oleh data-data yang tersimpan dalam variabel “jst”. Data-data itu tersusun dalam format bertitik. Perhatikan informasi bias dan bobot di bagian bawah.

-
>> bobot=jst.IW
-
bobot =
-
[9×4 double]
Maksud dari “jst.IW” adalah kita memanggil informasi bobot yang ada dalam variabel “jst” yang kemudian disimpan dalam variabel bernama “bobot”. Namun muncul masalah dimana bobot hanya menampilkan file bertipe structure. Tipe file ini sering digunakan oleh pengguna Matlab yang berkecimpung dengan database.
-
>> cell2mat(bobot)
-
ans =
-
0.6300 0.9296 0.5837 -0.2078
-
0.8001 -0.6945 0.9106 0.2863
-
-0.7114 0.9695 0.3352 -0.5743
-
0.8743 0.9537 -0.8952 0.5222
-
0.3212 0.0178 0.7384 -0.8089
-
-0.8575 0.5574 0.8318 -0.5720
-
-0.4038 -0.6834 0.3856 -0.8205
-
0.1292 -0.1272 0.5403 -0.7231
-
0.8403 0.7692 0.4331 0.4783
Sebenarnya jumlah bobot sudah terjawab, tetapi jika ingin mengetahui bobot tiap neuron berdasarkan masukan (ada 4 input) maka gunakan konversi dari cell ke mat (fungsi cell2mat). Begitu juga untuk biasnya:
-
>> bias=jst.b
-
bias =
-
[9×1 double]
-
[ -0.5114]
-
>> cell2mat(bias)
-
ans =
-
0.3908
-
-0.3910
-
0.9763
-
-0.8269
-
0.0012
-
-0.3521
-
0.6170
-
0.6681
-
-0.7900
-
-0.5114












 atau di menu – windows – Catalog.
atau di menu – windows – Catalog.



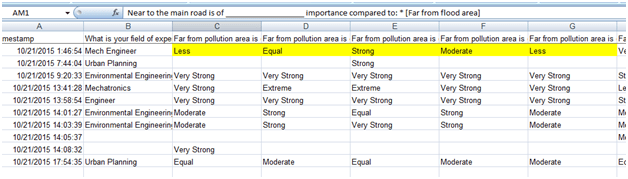
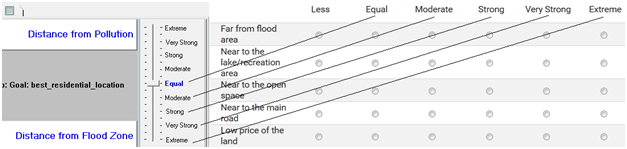
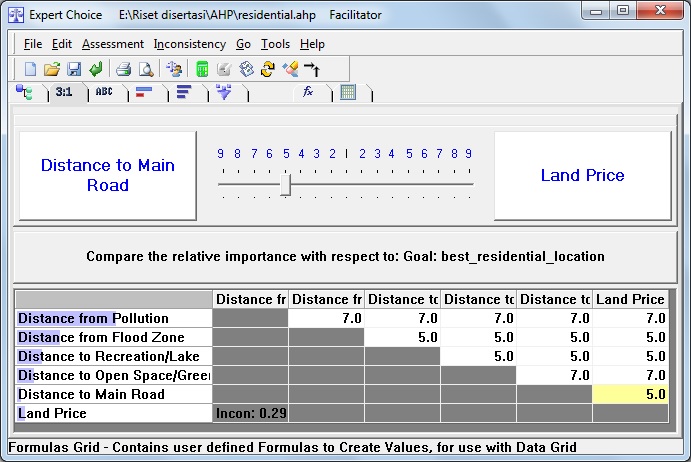
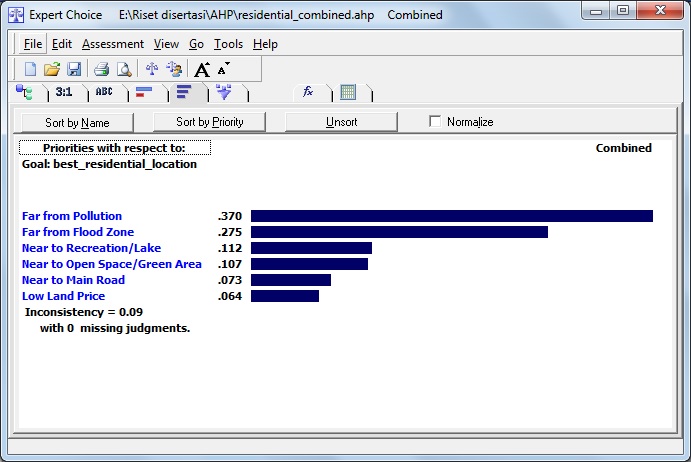
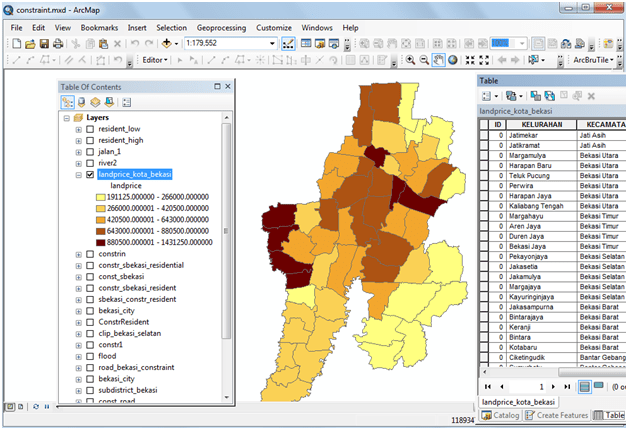
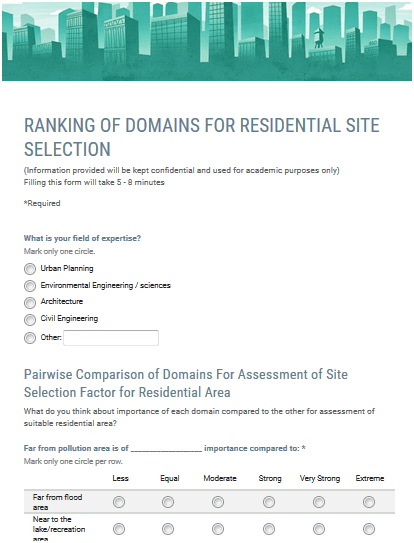 Dulu sempat mengambil mata kuliah Decision Support System (DSS) dan memperoleh materi khusus AHP dan sekarang ternyata “butuh lagi”. Ketika membuka lagi folder-folder lama dan ternyata masih ada. Sayang softwarenya tidak bisa diinstal di laptop saya karena versi yang sekarang windows 64 bit. Untung ada yang “share” program aplikasi tersebut di internet, ya sudah saya “pinjam”.
Dulu sempat mengambil mata kuliah Decision Support System (DSS) dan memperoleh materi khusus AHP dan sekarang ternyata “butuh lagi”. Ketika membuka lagi folder-folder lama dan ternyata masih ada. Sayang softwarenya tidak bisa diinstal di laptop saya karena versi yang sekarang windows 64 bit. Untung ada yang “share” program aplikasi tersebut di internet, ya sudah saya “pinjam”.