Jaringan Syaraf Tiruan (JST) merupakan metode terkenal dalam Soft Computing. Metode yang pertama kali diperkenalkan oleh McCulloch dan Pitts ini menggunakan prinsip yang mirip transfer function dalam sistem kontrol/kendali. Sebuah neuron yang mirip neuron makhluk hidup (dalam bentuk yang sederhana) berfungsi menghantarkan suatu masukan ke keluaran berdasarkan proses sebelumnya yang terkenal, yaitu training. Karena prinsip kerja neuron berupa bobot dan bias yang hanya mengandalkan training, akibatnya JST sering disebut “black box” bagi pengguna, berbeda dengan fuzzy inference yang memiliki alur logika dalam bagian rule-nya. Hasil training JST bisa menghasilkan dua sistem yang berbeda jika dilakukan dua kali pelatihan dan hal ini merupakan ciri khas dari soft computing yaitu ketidakpastian (uncertainty).
Ketidakpastian banyak dijumpai dalam kehidupan sehari-hari. Proses kita mengenali wajah seseorang pun sesungguhnya melibatkan ketidakpastian. Penemu fuzzy, L. Zadeh, mengusulkan dibentuknya notasi fuzzy yang menyatakan besaran dalam ukuran yang sering digunakan sehari-hari seperti tua, muda, dan sejenisnya dibanding bilangan seperti 20, 40, 70 tahun, dan sebagainya. Bentuk tertentu terkadang tidak bisa dibuat logika fuzzy-nya sehingga peran JST sangat membantu. Tidak mungkin membuat aturan rule suatu tanda tangan, gambar, warna, bentuk, dan sejenisnya. Sehingga JST memiliki peran penting terhadap suatu bidang yang belum ada aturan/dasar-dasar ilmunya.
DATA SPASIAL
Saat ini data spasial sedang berkembang dan banyak digunakan dalam aplikasi-aplikasi sehari-hari seperti GPS, berita cuaca, data traffic lalu-lintas, dan banyak lagi. Bahkan game terkenal “pokemon” memanfaatkan fasilitas data spasial dalam sistemnya. Menjamurnya angkutan umum berbasis aplikasi online membuat data spasial berkembang pesat.
Perkembangan aplikasi berbasis data spasial ditunjang oleh metode-metode komputasi baik hard computing maupun soft computing. Menghitung jarak tempuh, prediksi waktu ke tujuan, mencari alternatif jalur, sudah banyak diterapkan dalam aplikasi-aplikasi berbasis data spasial. Data spasial memiliki keunikan tersendiri dibanding data lainnya. Di sini ada suatu koordinat yang menyatakan lokasi disertai dengan atribut-atribut lainnya yang mirip tabel biasa. Jadi prinsip sederhananya adalah data spasial merupakan tabel biasa dengan koordinatnya. Tentu saja diperlukan proyeksi geografis jika ingin diterapkan dalam suatu peta.
JST masih perlu dikembangkan untuk aplikasi data spasial mengingat proses training membutuhkan memory yang cukup besar. Tetapi hardware yang berkembang terus menyebabkan metode ini tidak menjadi masalah untuk perangkat-perangkat mobile terkini.
ENVIRONMENT dan PERENCANAAN
Salah satu keunggulan dari JST adalah sifatnya yang fleksibel dan dapat diterapkan ke berbagai bidang. Bahkan bidang-bidang yang berkarakter ilmu sosial pun dapat memanfaatkan JST, salah satunya adalah lingkungan dan perencanaan. Saat ini bidang-bidang tersebut mengandalkan aplikasi-aplikasi yang berbasis data spasial, dan juga statistik tentu saja. Ada istilah spatial metric, yang merupakan statistika terhadap data spasial. Software yang terkenal adalah Fragstats (lihat postingan tentang software ini).
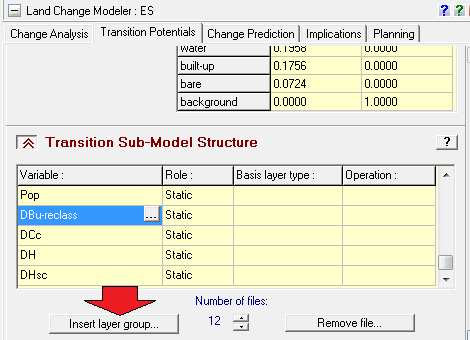
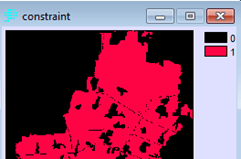
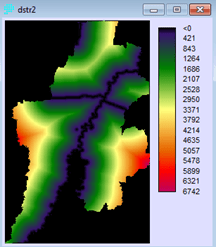
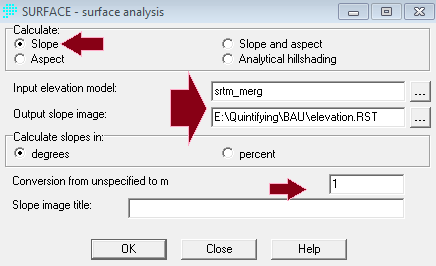
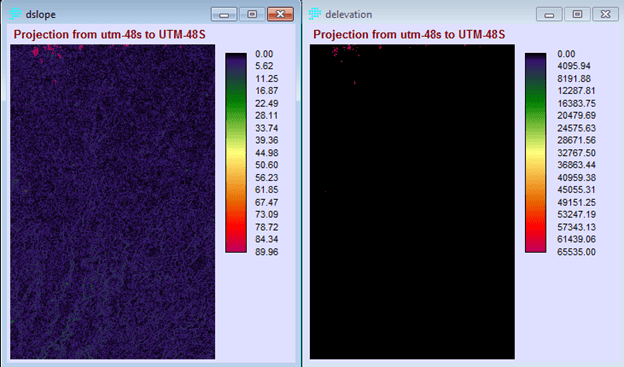
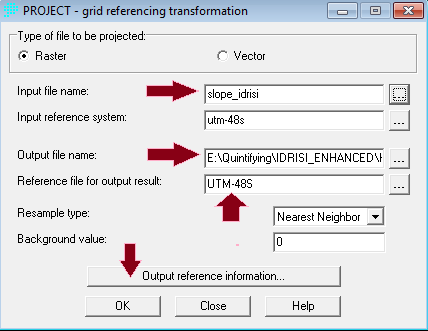
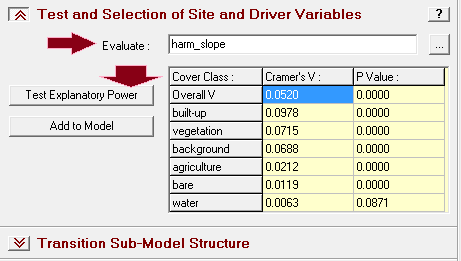
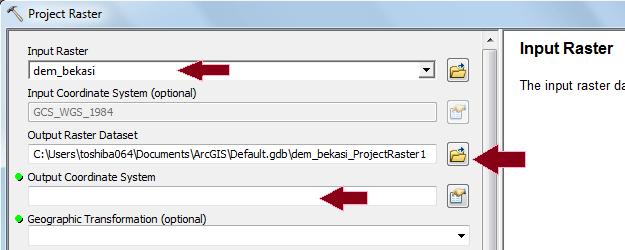
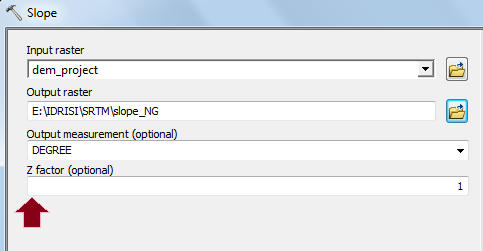
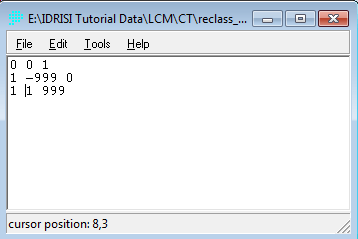
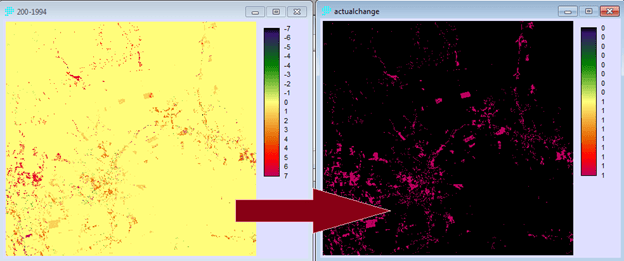
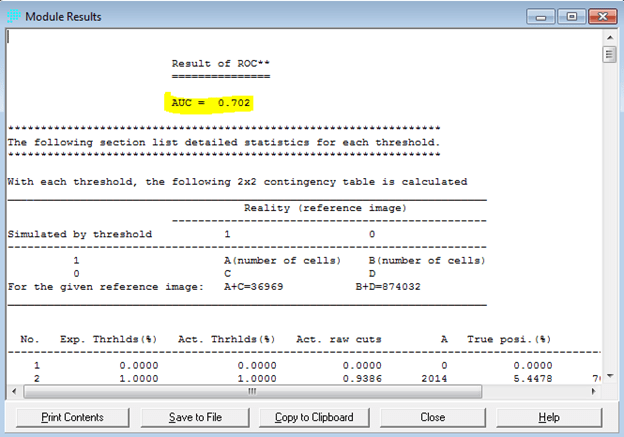
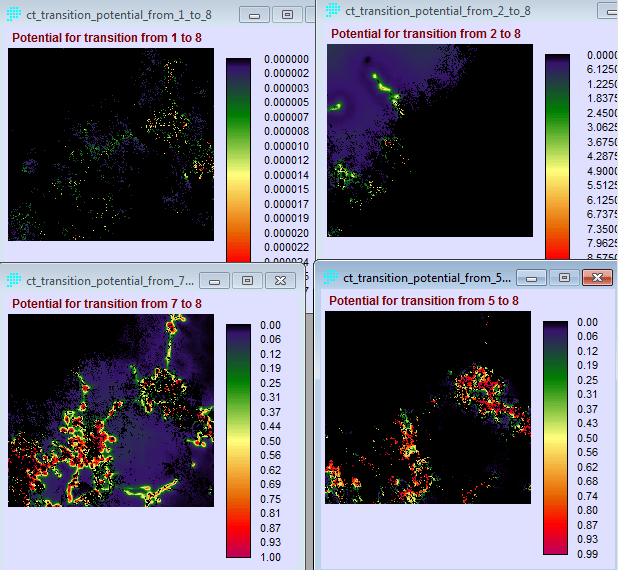
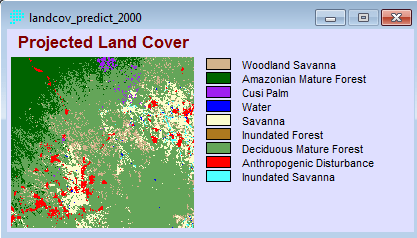
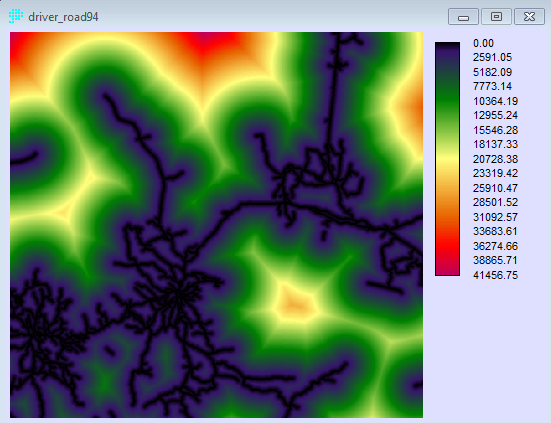
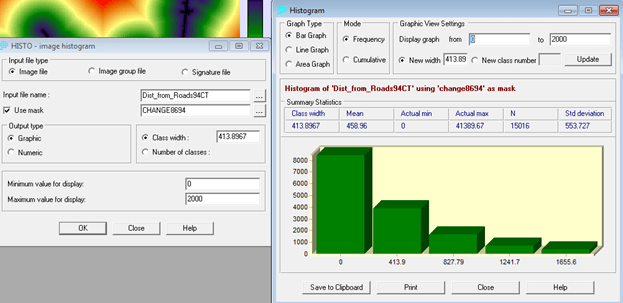
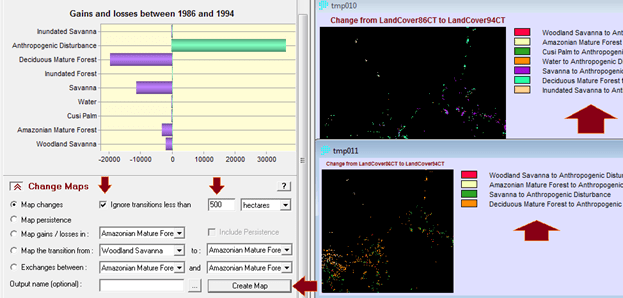
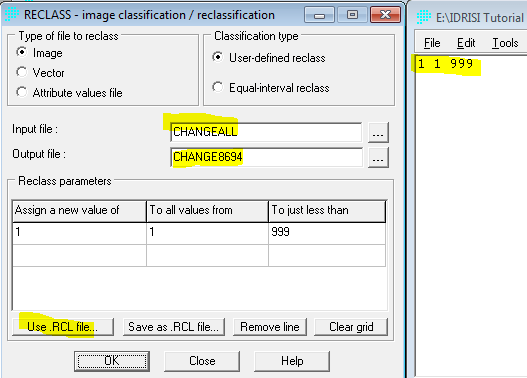
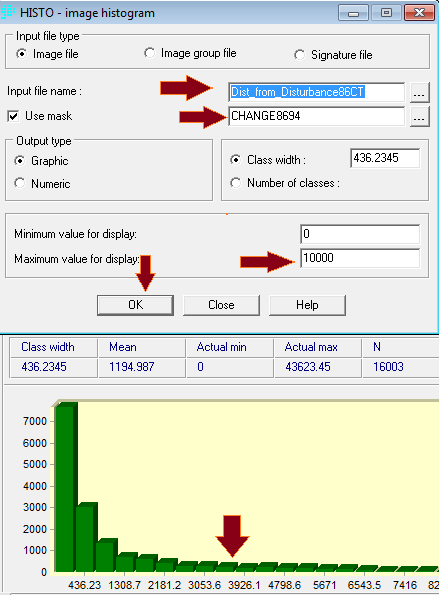
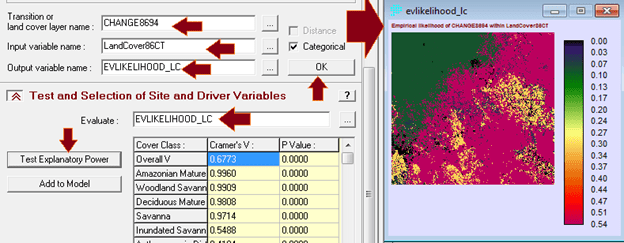
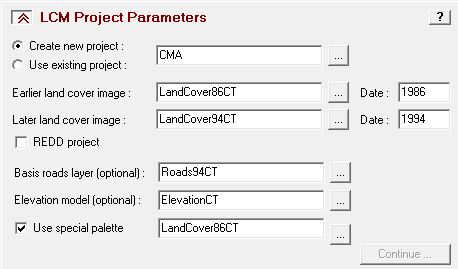
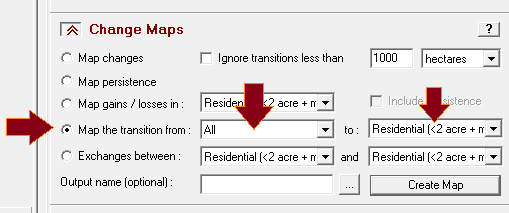
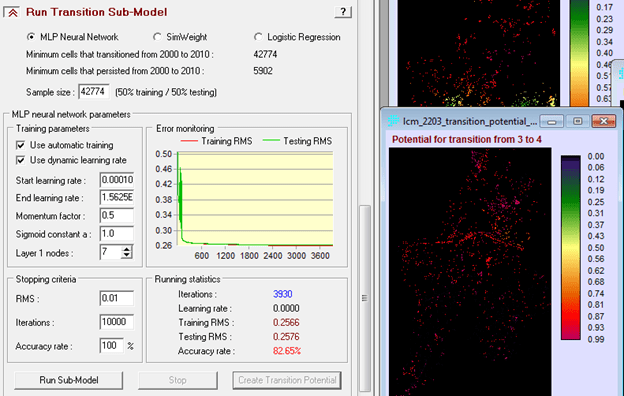
Penerapan yang mencolok adalah pada bidang perencanaan. Di sini suatu model biasanya dibentuk dengan dua metode yaitu logistic regression dan JST. Salah satu keunggulan JST adalah karakteristiknya yang mampu menangani data non-linear, sementara logistic regression harus melinearkan data terlebih dahulu dalam bentuk logaritmik. IDRISI memanfaatkan JST dalam salah satu modelnya (LCM) untuk melatih model terhadap suatu perubahan. Jadi data spasial sangat berkaitan dengan data temporal. Gambar berikut contoh hasil training dengan JST, yang disebut di aplikasi itu dengan nama multi-layer perceptron (MLP) neural network.
RISET DOKTORAL
Untuk yang telah menyelesaikan kuliah doktoralnya pasti merasakan bagaimana sulitnya menjalani pendidikan level ini. Untuk yang belum dan berencana untuk melanjutkan studi, perlu dipersiapkan hal-hal yang penting. Salah satunya adalah proposal dan topik disertasi yang akan diselesaikan. Untuk beasiswa sepertinya saat ini tidak menjadi masalah mengingat kuota yang dibutuhkan masih banyak. Tentu saja syarat bahasa mutlak diperlukan untuk lolos dan memperoleh beasiswa. Kampus tujuan dengan level sedang dan rendah sepertinya tidak mencari mahasiswa yang cemerlang, asalkan lolos syarat minimal dan memiliki/telah memperoleh beasiswa.
Kuliah doktoral tidak lepas dari riset yang harus dipublikasikan ke jurnal internasional. Saat ini untuk menembus jurnal internasional kian sulit karena perkembangan pesat penelitian. Tiap hari muncul temuan-temuan baru yang dipublikasikan dalam jurnal internasional. Bagaimana dengan kita? Kebaruan (state of the art), research gap, dan yang tak kalah penting, tren terkini harus diperhatikan. Jangan sampai mengambil tema yang mudah tetapi sulit tembus jurnal internasional atau terlalu sulit sehingga riset tidak selesai-selesai. Tetapi biasanya promotor mengetahui mana batas idealnya. Terus terang saya sendiri sulit bersaing dalam ilmu komputer murni, bagaimana mengoptimalkan algoritma data mining misalnya, meningkatkan akurasi dan performa lain suatu metode, menggabungkan metode-metode (hybrid) untuk menghasilkan metode baru, dan sejenisnya. Jalan pintas pun diambil dengan menyeberang komputasi untuk bidang-bidang lain yang masih jarang disentuh seperti lingkungan dan perencanaan. Saya terkejut ketika profesor-profesor bidang lingkungan dan perencanaan mengatakan mereka sangat membutuhkan bantuan pakar-pakar bidang ilmu komputer untuk bekerja sama. Bahkan kontroversi-kontroversi dan debat-debat di area mereka, misalnya masalah urban, dapat kita bantu membuatkan analisa kuantitativenya jika tidak ditemui kompromi, seperti yang saya publikasikan dalam salah satu jurnal URBAN ini. Sekian, semoga bisa menginspirasi.
Update: 3 Desember 2017
Untuk yang mengkhususkan riset tentang JST, saat ini deep learning menjadi topik yang sedang hangat (lihat post berikutnya tentang apa itu deep learning dan hubungannya dengan Machine Learning)