Ketika kita belajar statistik di bangku sekolah, pasti pernah diajarkan regresi, baik sederhana maupun yang agak lanjut misalnya regresi berganda (kecuali kalo jurusannya tata boga barangkali tidak diajarkan). Saat ini metode regresi banyak berkembang dengan menggabungkannya dengan metode soft computing. Jika dengan Support Vector Machine (SVM) namanya menjadi Support Vector Regression (SVR), kalau dengan Neural Network atau yang dalam bahasa Indonesianya jaringan syaraf tiruan menjadi Neural Network Regression. Di sini kita akan berlatih yang mudah dahulu yaitu neural network regression.
Seperti telah dibahas di postingan sebelumnya, pada prediksi dengan JST terkadang diperlukan data yang mempengaruhi pergerakan ramalan yang dikenal dengan istilah variabel intervention. Tapi tentu saja jangan sampai variabel ini sangat berpengaruh karena bisa berakibat bukan peramalan, melainkan prediksi seperti biasa. Langsung aja praktek, misalnya kita memiliki data temporal, misalnya 5 tahun dengan masing-masing 1,2,3,4, dan 5 (kan supaya gampang prakteknya). Variabel interventionnya misalnya berturut-turut 1000, 2000, 3000, 4000, 5000, 6000, 7000 dan seterusnya, biasanya kalo di realnya prediksi populasi penduduk, inflasi, dan sejenisnya yang ikut menentukan peramalan lima tahun itu. Siapkan datanya di Matlab. Untuk membersihkan layar ketik clc, dan untuk membersihkan variabel di workspace ketik clear (pasti ada yang belum tahu 🙂 ).

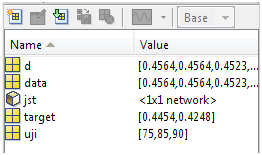
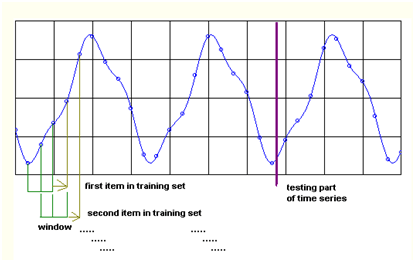
Saya lebih suka mengetiknya dengan gaya di atas, yaitu pada saat memasukan variabel pelatihan (data). Jadi JST akan kita beri dua data pelatihan (tentu saja untuk real Anda gunakan lebih dari dua data) yaitu 1,2,3 yang telah meramalkan 4 dan 2,3,4 yang telah meramalkan 5. Jadi jika kita ingin memprediksi tahun ke enam ya tinggal memasukan data 3,4,5 yang harapannya akan menghasilkan hasil ramalan, entah 5, 6 atau berapa, sesuai hasil training dua data sebelumnya. Anda bisa saja membuat tiga data pelatihan [1,2], [2,3],[3,4] tetapi ya kurang bagus kalo untuk peramalan Cuma dua series. Gimana intervention-nya? Intervention itu data input tambahan, jadi misalnya tadinya 1,2,3 karena ada data intervention menjadi 1,2,3, 4000 dan 2,3,4, 5000. Dari mana asal 4000 dan 5000, ya dari data untuk memprediksi berturut-turut tahun ke 4 dan ke-5 (mudah-mudahan nggak bingung). Ok, yg gampang dulu, ketik nntool dilanjutkan dengan mengimport variabel-variabel pelatihan ke toolbox tersebut. Ikutin prosedur-prosedur seperti postingan sebelumnya. Ketika memasukan dan mengeluarkan data sama dengan klasifikasi, tetapi untuk meramu JST, waspadalah .. waspadalah, sedikit berbeda.

Logis sedikit lah, kalo kita lihat trend datanya kan 1,2,3,4, dst, berarti linear kan? Pilihlah wakilmu yang dapat dipercaya, PURELIN alias si “pure linear”. Tapi kalau plot data yg akan diramal meliuk-liuk ya pilih tangen sigmoid aja (sorry kalo bikin pusing).

Lanjutkan dengan create hingga export hasil training (defaultnya bernama network1). Bereskah? Uji dahulu kalau begitu. Oiya ketika memprediksi data tahun ke 7, gunakan data hasil prediksi tahun ke 6, ya, di sini saya menggunakan 6.0000 karena kebetulan hasil prediksi data tahun ke 6 itu segitu, biasanya sih ga pas segitu, misal 5.889, gunakan angka itu untuk memprediksi tahun ke-7, bukannya 6.

Ok, selamat mencoba. Pencari ilmu itu harus haus, udah minum, pengen minum lagi, coba sendiri dengan menambahkan variabel intervention, dan juga data contoh yang tidak linear kayak di atas. Jika ingin pake bahasa vb, c#, java, silahkan buka m-file di matlab, pelajari dan coding ulang dengan bahasa yg menurut Anda the best, atau sesuaikan dengan permintaan jika ingin laku, informatics serves everything.


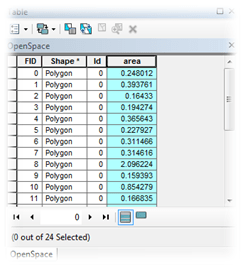
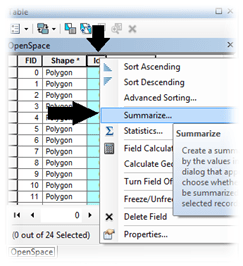


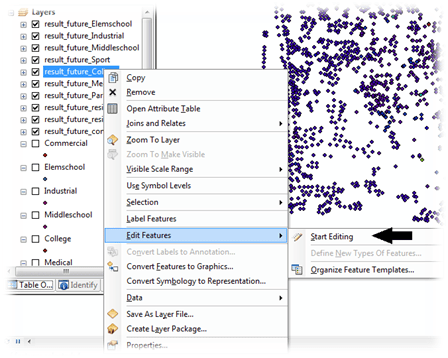
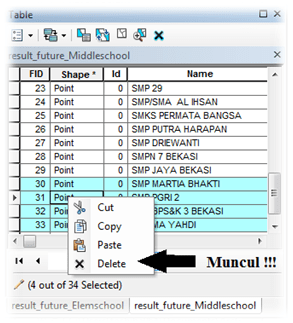





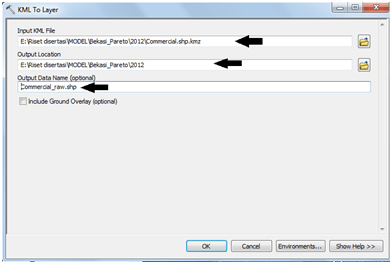




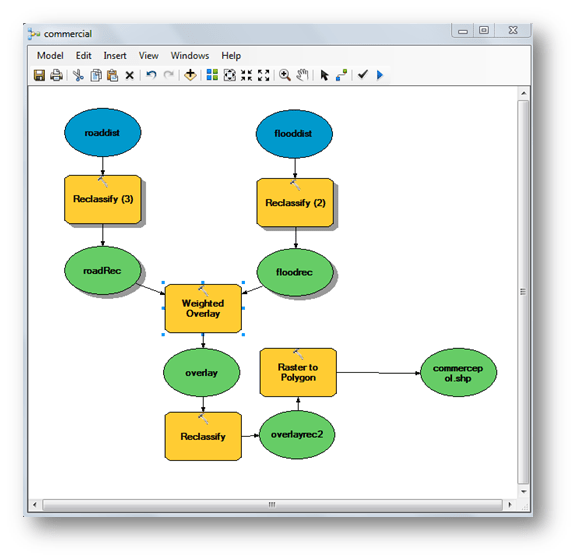
 atau di menu – windows – Catalog.
atau di menu – windows – Catalog.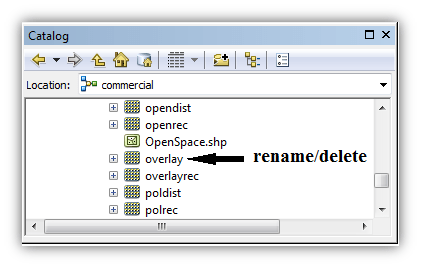



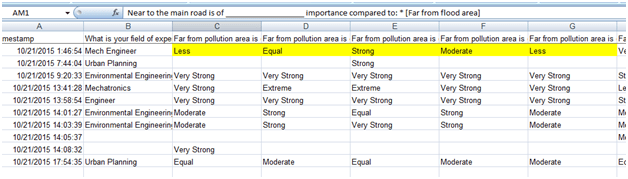
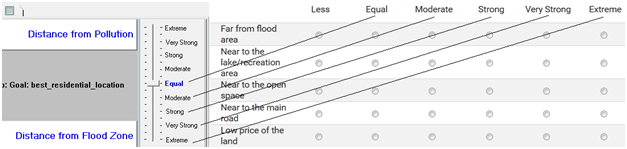
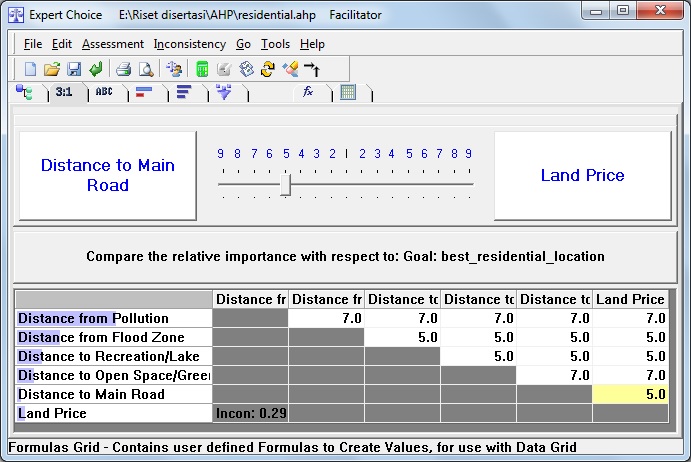
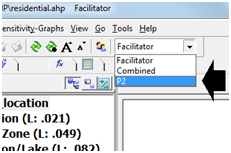
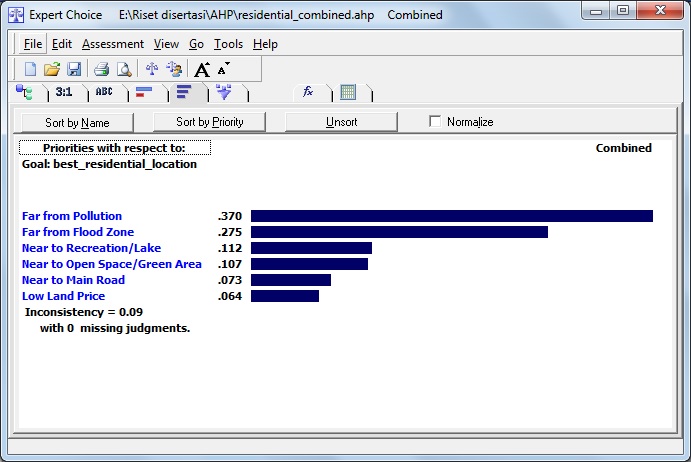
 Dulu sempat mengambil mata kuliah Decision Support System (DSS) dan memperoleh materi khusus AHP dan sekarang ternyata “butuh lagi”. Ketika membuka lagi folder-folder lama dan ternyata masih ada. Sayang softwarenya tidak bisa diinstal di laptop saya karena versi yang sekarang windows 64 bit. Untung ada yang “share” program aplikasi tersebut di internet, ya sudah saya “pinjam”.
Dulu sempat mengambil mata kuliah Decision Support System (DSS) dan memperoleh materi khusus AHP dan sekarang ternyata “butuh lagi”. Ketika membuka lagi folder-folder lama dan ternyata masih ada. Sayang softwarenya tidak bisa diinstal di laptop saya karena versi yang sekarang windows 64 bit. Untung ada yang “share” program aplikasi tersebut di internet, ya sudah saya “pinjam”.