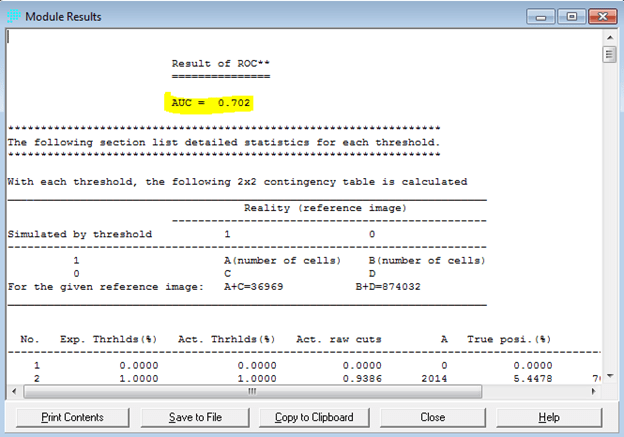
Kementerian riset, teknologi dan pendidikan tinggi (Ristek-dikti) mulai memberlakukan sistem pengindeks khusus dosen di Indonesia yang dikenal dengan nama SINTA (lihat link-nya di sini). Ketika masuk ke situs itu, beberapa peneliti dengan h-indeks (standar google scholar) yang tinggi sudah dimasukan, sementara itu saya yang h-indeksnya masih kecil belum dimasukan. Rencananya, verifikasi akan dilaksanakan bulan April 2017 nanti (info dari SINTA via email). Akan tetapi sebaiknya kita daftarkan nama kita yang sudah tercantum.
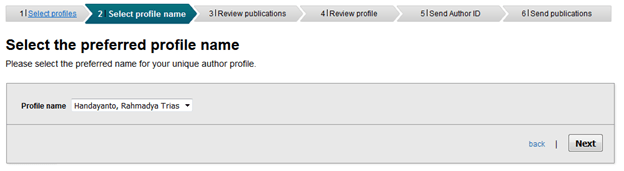
Secara default, SINTA mengambil data NIDN, nama, dan affiliation dari forlap dikti. Untuk registrasi, kita tinggal mengarahkan nama dan NIDN yang sesuai. Untuk registrasi, ikuti langkah-langkah berikut ini:
1. Masuk ke menu registrasi (klik registrasi). Anda akan diminta memasukan Affiliation dan nama. Affiliation di sini berarti Home Base NIDN kita. Ketika mengisi afiliasi, pastikan muncul nama kampus (pull down), lalu tekan kampus yang dimaksud (tidak mengetik manual).
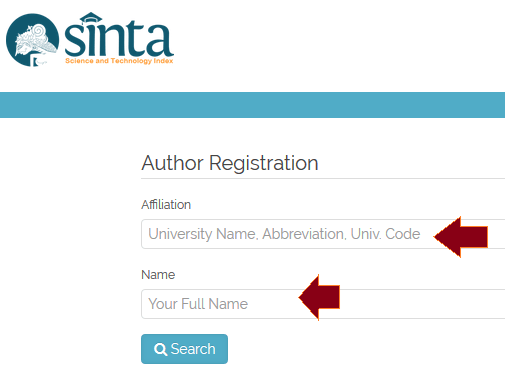
2. Setelah ditemukan tekan tombol registration di bawah nama Author. Maka berikutnya masuk ke isian detail data Author tersebut. Ada dua data penting, yaitu personal yang di sebelah kiri dan umum di sebelah kanan (NIDN, ID index yang lain – Inasti ID, Scopus ID, Google Scholar dan IPI Author portal Garuda). Untuk yang personal isi dengan lengkap gelar dan Email untuk aktivasi nanti. Sementara wilayah yang sebelah kanan sedikit butuh pengetahuan mengenai indexer selain SINTA.
3. Yang pertama adalah Inasti ID. Indexer ini sepertinya bawaan SINTA yang dikelola LIPI. Nama saya tidak ada di situ, mungkin karena belum diverifikasi.
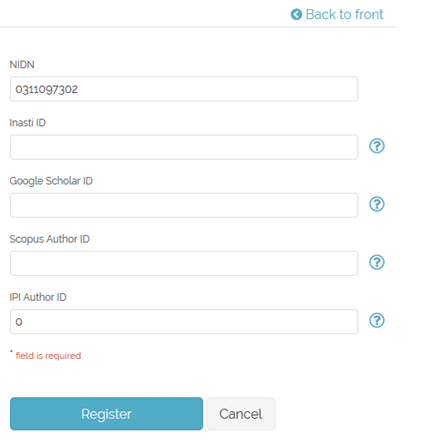
4. Berikutnya adalah, indexer yang banyak dipakai orang, yaitu Google Scholar. Cara melihatnya adalah dengan login ke google scholar, kemudian ambil ID di antara user= dan &hl. Cukup mudah tetapi prakteknya butuh kejelian. Oiya, jangan sampai &hnl ikut tercantum ya.
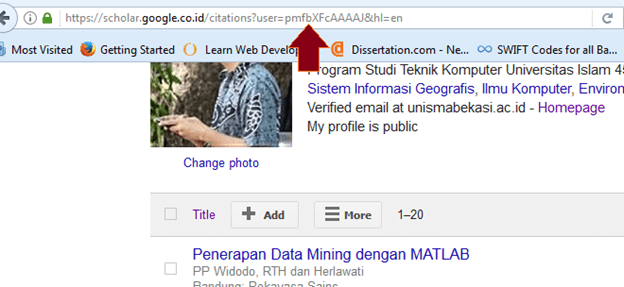
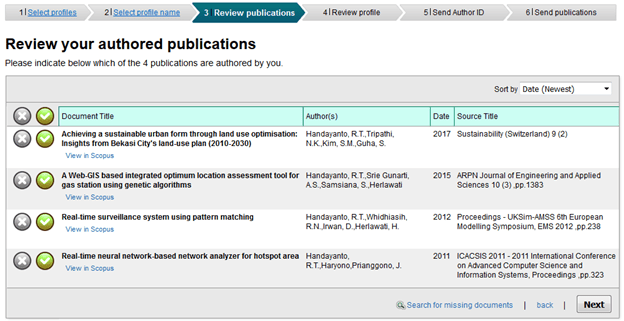
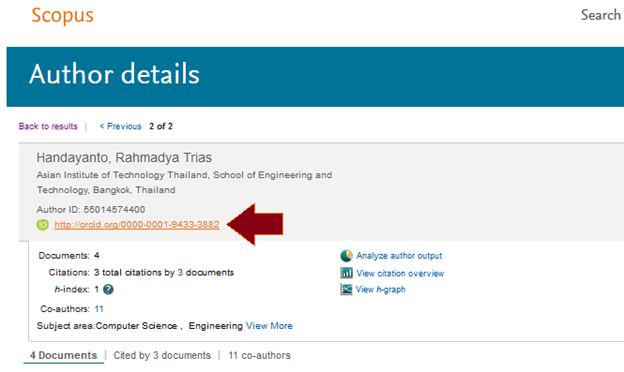
5. Scopus ID. ID yang terkenal ini untuk membukanya sedikit rumit jika kita tidak pernah menjadi penulis pertama. Lihat postingan saya terdahulu untuk mengetahuinya. Tentu saja jika Anda belum pernah menjadi Author maupun Co-Author, tidak akan memiliki Scopus ID. Tetapi jangan khawatir, Anda tetap bisa registrasi. Kosongkan saja bagian Scopus ID ini.
6. Berikutnya adalah IPI Author ID yang berasal dari Portal Garuda. Kebanyakan dosen sudah memiliki ID karena kebanyakan sudah mempublikasikan tulisan di jurnal nasional ber-ISSN. Ikuti saja link-nya dengan menekan simbol tanda tanya “?” di sebelah kanan isian. Isi nama, dan afiliasi jika perlu.

Lanjutkan dengan menekan tombol Register. Setelah langkah satu hingga enam, buka email yang merupakan email yang tadi dituliskan di kolom personal di bagian kiri. Tekan tombol Activation dari email yang sudah tiba. Selesai sudah registrasi ke sistem pengindeks peneliti asli Indonesia.
Update: 5 Mei 2017
Sinta sepertinya sudah diverifikasi, untuk yang belum daftar masih bisa registrasi susulan, bahkan id scopus langsung terkoneksi tidak seperti sayayang baru scholar google saja, tetapi bisa diajukan ulang untuk verifikasi scopusnya.
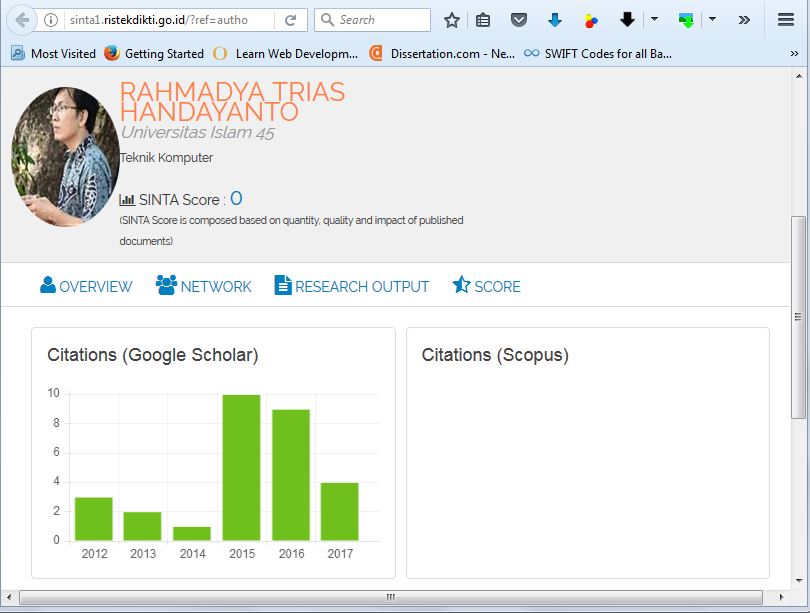
Berikut instruksi dari RISTEK-DIKTI untuk yang belum registrasi untuk segera registrasi.
Silahkan LINK BERIKUT untuk lebih jelasnya, dari Univ Islam Sultan Agung
Update: 24 Mei 2017
Setelah mengirim email ke djrisbang (lihat email lengkapnya di surat edaran di atas) akhirnya scopus saya bisa terkoneksi ke sinta saya. Trims bpk Witno (admin sinta), atas bantuannya.
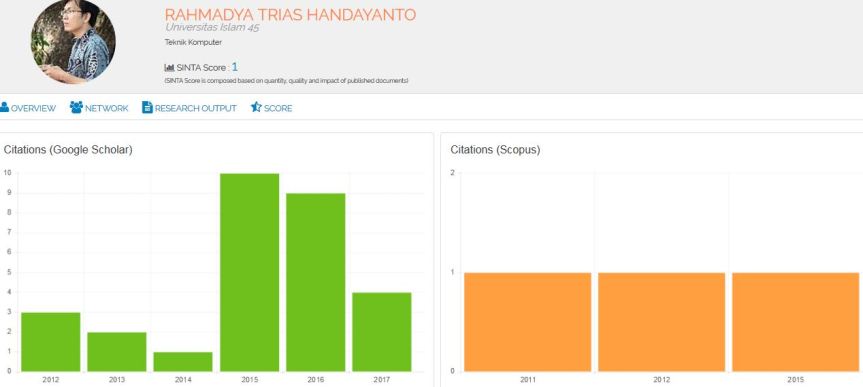
Update 18 Juli 2017
Ada sedikit perubahan tampilan Sinta di bagian Author kampus. Dosen yang tidak terindeks scopus pun muncul score di kanan walaupun nol semua. Sepertinya dosen dipaksa untuk publis Jurnal Internasional yang terindeks scopus juga (tidak hanya Google scholar).
Update: 4 Agustus 2017
Ada informasi bahwa publikasi Indonesia berhasil mengalahkan Thailand dan Vietnam. Tinggal menunggu waktu saja sepertinya untuk mengalahkan Malaysia dan Singapura, semoga. Tampilan Sinta yang baru ok juga, walaupun sitasi terakhir saya belum terekap:
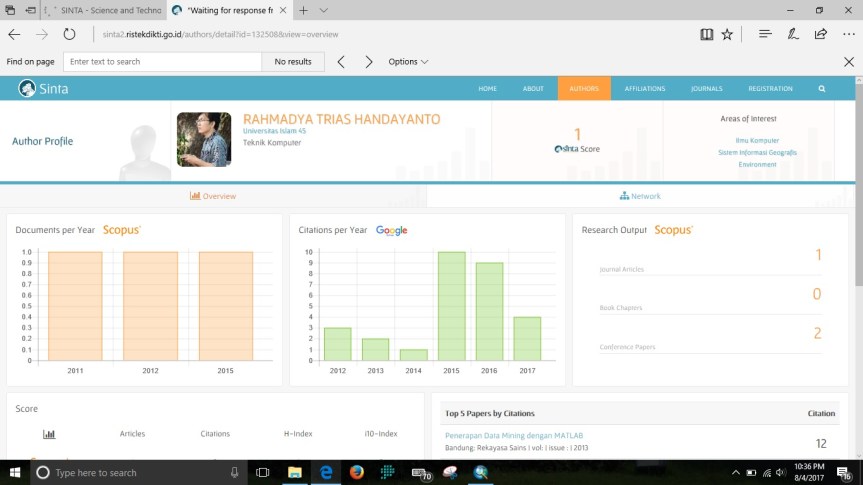
Update: 9 Agustus 2017
Info terbaru, Sinta membuka registrasi kembali untuk yang belum sempat registrasi. Silahkan daftar.
Update: 19 Agustus 2017
Sinta versi 2 (sinta2) sepertinya sudah OK, h-index scopus sudah terupdate (tadinya h-index=1 jadi 2). Sepertinya sudah terkoneksi online, kita tunggu saja perkembangannya, yg menurut saya sih sudah ok.
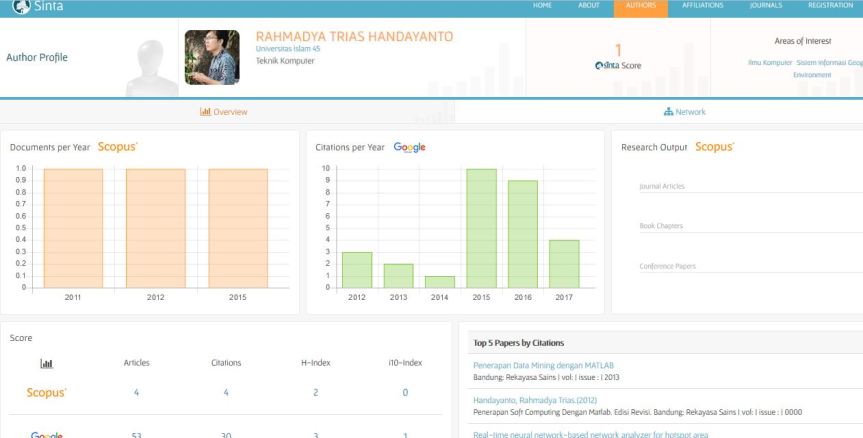
Update: 19 November 2017
Ide yang bagus dari Sinta untuk menambah desimal pada skor Sinta (dua angka di belakang koma). Manfaatnya untuk melihat lebih detil performa peneliti.
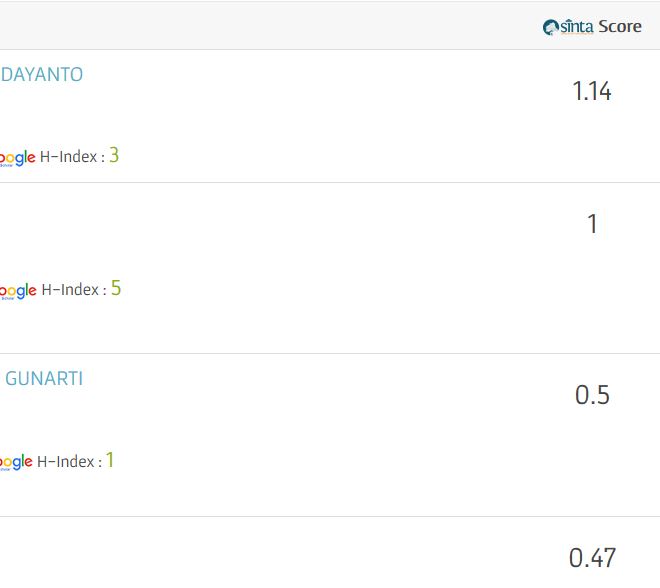
Update: 14/2/2018
Kampus akhirnya dilibatkan untuk verifikasi akun Sinta. Sepertinya mirip evaluasi diri dan akurasi data dosen-dosennya yang terdaftar di Sinta (juga jurnal2nya). Berikut infonya:
Update: 19/3/2018
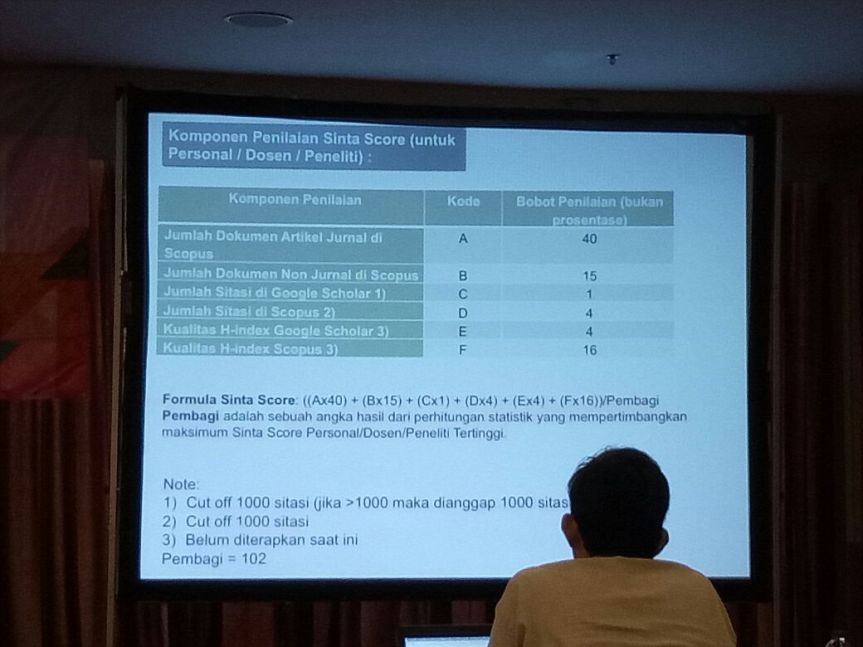
Kelanjutan dari verifikator sinta di level universitas masing-masing, ristekdikti mengadakan pelatihan verifikator sinta tgl 15-16 Maret di Bandung. Satu hal yang bisa jadi informasi perhitungan skor sinta adalah:
Skor = (Ax40 + Bx15 + Cx1 + Dx4 + Ex4 + Fx16)/Pembagi
Dimana A: Artikel jurnal di Scopus, B: Dokumen non jurnal di Scopus, C: Jumlah sitasi di Google scholar, D: Jumlah sitasi di Scopus, E: H-index di Google Scholar, F: H-index Scopus. Pembagi belum pasti, saat ini: 102. Tapi kok saya lebih kecil dari rumus itu ya? mungkin belum semua ketarik (scopus dan scholarnya)
Update: 31 Juli 2018
Protes-protes terhadap SCOPUS yang kapitalis ternyata tidak menyurutkan Kemristekdikti akan peran pengindeks ternama itu. Bahkan sistem informasi hibah SIMLITABMAS menarik data SCOPUS dari Sinta sebagai pertimbangan dalam eligible atau tidak seorang dosen untuk mengajukan proposal. Untungnya Sinta mudah disinkronasi karena dilakukan oleh pejabat yang ditunjuk pada tiap-tiap kampus. Berikut tampilan baru SIMLITABMAS yang telah menarik data dari Sinta. Letaknya di bawah profil di SIMLITABMAS kita.
Update: 29 Januari 2024
Ternyata SINTA mulai berbenah, dan sudah terkoneksi dengan SISTER, BIMA dan lain-lain. Postingan terpaksa diedit karena link SINTA ternyata berubah ke server yang baru (kemdikbud).

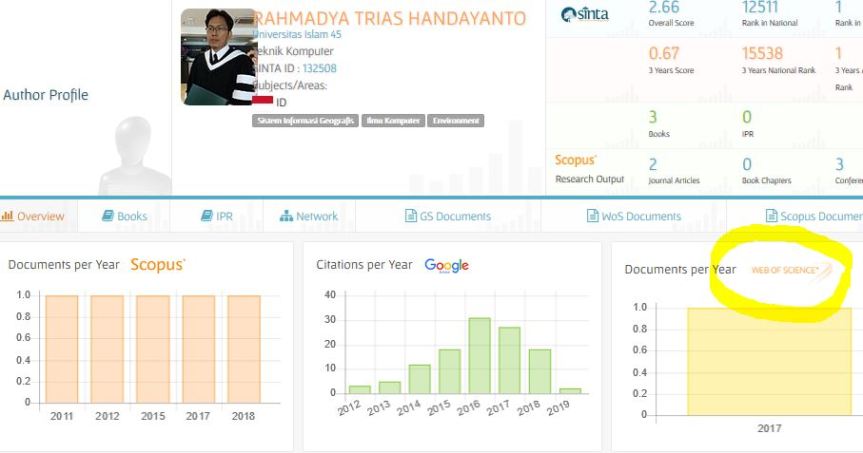
Update: 5 Maret 2019 : Web of Science
Lama tidak membuka Sinta, ternyata ada sedikit modifikasi pada sisi indeksasi. Salah satu pengindeks ternama, yaitu Web of Science, atau yang dikenal dengan Thomson Reuters masuk dalam Sinta. Lokasinya berada di bagian kanan pada overall baik di institusi maupun di individu (peneliti). Ternyata tidak semua yang terindeks Scopus terindeks di Web of Science.